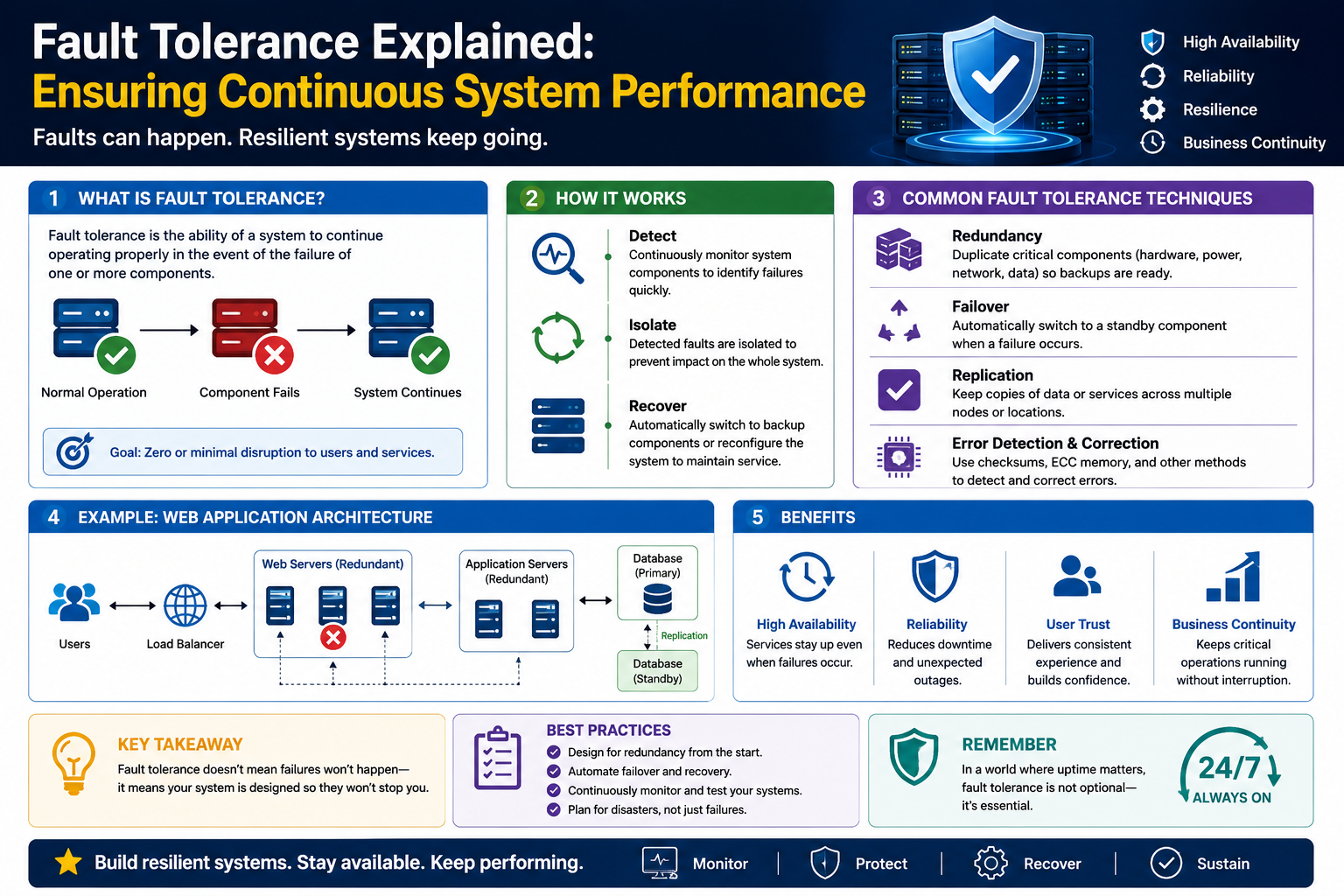
Fault tolerance refers to the ability of a system to continue operating correctly even when one or more of its components experience failure. These components may include hardware elements such as processors, memory units, storage drives, or network interfaces, as well as software services, applications, or communication processes. The central idea is that a system should not completely stop working when something goes wrong internally. Instead, it should maintain essential operations and continue delivering services with minimal interruption.
In modern computing environments, systems are built from multiple interconnected layers. Each layer depends on others to function correctly. If even one layer fails, it can potentially disrupt the entire system unless mechanisms are in place to handle such disruptions. Fault tolerance ensures that the system does not rely entirely on a single component or pathway. Instead, it distributes responsibilities and prepares alternative ways to continue operation when failures occur.
Fault tolerance is not about preventing failure altogether, because failure is unavoidable in real-world systems. Instead, it focuses on reducing the impact of failure and maintaining continuity of service. This makes it an essential design principle for systems that support critical operations where downtime can lead to financial loss, safety risks, or operational disruption.
Why System Failures Are Inevitable in Real Environments
Every computing system is subject to eventual failure, regardless of how advanced or well-maintained it is. Hardware components are physical devices that naturally degrade over time due to heat, electrical stress, mechanical wear, or environmental conditions. Even high-quality components have a limited operational lifespan.
Software systems, while not physically degrading, are still vulnerable to failure. Bugs, memory leaks, unexpected input conditions, logic errors, and conflicts between software components can cause instability. In addition, external factors such as network congestion, power fluctuations, or security incidents can also lead to system disruption.
Complex systems increase the likelihood of failure because they contain many interacting components. The more components a system has, the greater the probability that at least one of them will fail at some point. This is why large-scale systems are designed under the assumption that failure is not a matter of if but when.
Instead of attempting to eliminate all possible failures, system designers focus on managing their consequences. Fault tolerance is built into the architecture so that when failures occur, the system can isolate the problem and continue functioning without collapsing entirely.
Behavior of Systems During Component Failure
When a non-fault-tolerant system experiences a failure, the result is often immediate disruption. Applications may stop responding, services may become unavailable, or data processing may halt entirely. Users may experience errors, delays, or complete loss of access.
In a fault-tolerant system, the behavior is different. When a failure occurs, the system detects the problem and isolates the affected component. It then redirects operations to functioning components that can take over the workload. This transition is designed to happen quickly and in many cases without user awareness.
The system continuously evaluates its internal state through monitoring mechanisms. These mechanisms track performance indicators such as response time, resource utilization, error rates, and connectivity status. When abnormal behavior is detected, automated processes determine whether a component is failing or already failed.
Once a failure is confirmed, corrective action begins. This may involve rerouting traffic, activating backup components, or redistributing tasks across healthy parts of the system. The goal is to ensure continuity of service while the failed component is repaired or replaced.
Role of System Design in Achieving Fault Tolerance
Fault tolerance is not an add-on feature that can be applied after a system is built. It must be integrated into the design phase. System architects carefully evaluate which components are critical and how failure in those components would affect overall system behavior.
A fault-tolerant design avoids single points of failure. A single point of failure is any component whose malfunction would cause the entire system to stop working. By identifying these points and introducing alternative paths or backup components, designers reduce system vulnerability.
Designing for fault tolerance also involves determining acceptable levels of performance degradation during failure. Some systems prioritize maintaining full functionality, while others may temporarily reduce performance to preserve essential operations. These design decisions depend on the purpose of the system and the consequences of downtime.
Another important aspect of system design is isolation. Fault-tolerant systems are often structured in a way that limits the spread of failure. If one component fails, it should not cascade and cause additional components to fail. This containment strategy helps preserve overall system stability.
Continuous Monitoring as a Foundation of Reliability
Monitoring is a critical element in fault-tolerant systems because it provides real-time visibility into system health. Without monitoring, failures could go undetected until they cause significant disruption. Monitoring systems continuously collect data from hardware and software components to identify abnormal conditions.
These systems track metrics such as CPU usage, memory consumption, disk activity, network latency, and application response times. They also monitor error logs and system alerts that indicate potential issues. By analyzing these signals, the system can detect early warning signs of failure before a complete breakdown occurs.
When monitoring tools detect irregular behavior, they trigger predefined responses. These responses may include restarting services, reallocating resources, or shifting workloads to backup components. In more advanced systems, automated decision-making processes determine the best course of action based on the severity of the issue.
Monitoring is not limited to detecting failures after they occur. It also plays a preventive role by identifying patterns that suggest future instability. This allows systems to take corrective action before failures happen, improving overall reliability.
System Continuity Through Automatic Adaptation
A defining characteristic of fault-tolerant systems is their ability to adapt automatically to changing conditions. When a component fails, the system does not wait for manual intervention. Instead, it responds immediately through predefined mechanisms that ensure continuity.
This adaptation process involves redistributing workloads, activating backup components, and adjusting system configurations. The system may shift user requests from one server to another or reroute network traffic through alternative pathways. These adjustments are made dynamically based on current system conditions.
Automatic adaptation reduces downtime and minimizes disruption. Users may not even be aware that a failure has occurred because the system continues to function normally from their perspective. This seamless experience is one of the primary goals of fault tolerance.
Adaptation also includes recovery processes. Once a failed component is repaired or replaced, it can be reintegrated into the system without affecting ongoing operations. The system ensures consistency and stability during both failure and recovery phases.
The Concept of System Dependability and Operational Risk
Fault tolerance is closely related to the concept of system dependability. Dependability refers to how reliably a system performs its intended function over time. A highly dependable system is one that continues to operate correctly even under adverse conditions.
Operational risk is the potential impact of system failure on business or organizational processes. Different systems carry different levels of risk depending on their function. For example, a system used for internal documentation may tolerate short periods of downtime, while a system processing financial transactions may require near-continuous availability.
Organizations assess operational risk when deciding how much fault tolerance to implement. Higher risk systems require stronger fault tolerance mechanisms, while lower risk systems may rely on simpler reliability strategies.
The relationship between dependability and fault tolerance is direct. As fault tolerance increases, system dependability also improves because the system becomes more resilient to failure conditions.
Importance of Continuity in Critical Environments
In environments where continuous operation is essential, fault tolerance becomes a fundamental requirement. These environments include financial systems, healthcare platforms, communication networks, transportation systems, and industrial control systems.
In such environments, even brief interruptions can have serious consequences. Financial systems may experience transaction failures, healthcare systems may delay critical treatments, and transportation systems may face safety risks. Because of this, these systems are designed with multiple layers of redundancy and backup mechanisms.
Continuity ensures that essential services remain available even during unexpected disruptions. This is achieved through carefully designed system structures that prioritize stability and resilience over simplicity.
Failure as a Predictable System Condition
One of the most important principles in fault-tolerant design is the recognition that failure is predictable. Instead of treating failure as an anomaly, it is treated as a normal part of system behavior.
This perspective changes how systems are built. Rather than focusing solely on preventing failure, engineers design systems that assume failure will occur and prepare responses in advance. This includes creating backup components, defining recovery procedures, and establishing monitoring systems.
By treating failure as expected, systems become more resilient and capable of handling real-world conditions without collapsing under pressure. This mindset is central to modern system architecture and reliability engineering.
Maintaining Stability Through Controlled Recovery Processes
When failures occur, recovery must be carefully controlled to avoid further disruption. Fault-tolerant systems use structured recovery processes that restore functionality without affecting ongoing operations.
These processes may involve restoring system state from checkpoints, synchronizing data across components, or gradually reintegrating repaired components into the system. Controlled recovery ensures that the system remains stable during transitions and avoids introducing new errors during the repair process.
Recovery is not only about fixing the failed component but also about ensuring that the system returns to a consistent and reliable state. This consistency is essential for maintaining trust and operational integrity.
Building the Foundation for Advanced Fault Tolerance Techniques
The core principles of fault tolerance form the foundation for more advanced system reliability techniques. Concepts such as redundancy, replication, load distribution, and automatic failover build upon the basic idea of maintaining continuity during failure.
Understanding system behavior, failure inevitability, monitoring, and adaptive response is essential before exploring these advanced techniques. These foundational ideas ensure that more complex mechanisms are effective and properly integrated into system architecture.
Building Reliable Systems Through Fault Tolerance Techniques
Fault tolerance in computing systems is achieved through a collection of structured techniques that work together to ensure continuity during failures. These techniques are not isolated solutions but interconnected methods that form a layered defense against disruption. Each technique addresses a specific aspect of system reliability, such as data protection, workload distribution, or system recovery.
In practical system design, fault tolerance is implemented by combining multiple strategies rather than relying on a single method. This is because different types of failures require different responses. A hardware failure may need redundancy, while a performance bottleneck may require load distribution. A data corruption issue may require replication or backup restoration. The strength of a fault-tolerant system lies in how well these methods integrate and complement each other.
The goal of these techniques is not only to keep systems running during failures but also to ensure that performance remains stable and consistent. Users should experience minimal disruption even when internal components are under stress or have failed entirely.
Redundancy as a Core Structural Principle
Redundancy is one of the most fundamental techniques in fault-tolerant design. It involves duplicating critical system components so that a backup is available if the primary component fails. These components can include servers, network connections, storage devices, or power supplies.
In a redundant system, the backup component may remain inactive or operate in a standby mode until it is needed. When a failure occurs, the system switches to the redundant component, allowing operations to continue without interruption. This transition is typically automated to ensure speed and reliability.
Redundancy can exist at multiple levels. Hardware redundancy ensures physical components have backups. Network redundancy provides alternate communication paths. Software redundancy allows multiple instances of applications to run simultaneously. Each level strengthens system resilience by reducing dependency on a single component.
The effectiveness of redundancy depends on synchronization between primary and backup components. If the backup is not updated or aligned with the primary system, switching may cause inconsistencies. Therefore, redundant systems often include synchronization mechanisms to ensure both components remain consistent.
Replication for Data Consistency and Protection
Replication focuses on maintaining multiple copies of data across different locations or systems. This ensures that even if one data source becomes unavailable, another copy can be used without delay. Replication plays a critical role in maintaining data availability and integrity.
There are different approaches to replication depending on system requirements. In tightly synchronized systems, data is replicated immediately across all locations. This ensures consistency but may introduce performance overhead. In loosely synchronized systems, replication occurs with slight delays, improving performance but allowing temporary differences between copies.
Replication is especially important in environments where data loss cannot be tolerated. It protects against storage failures, corruption, or accidental deletion. By maintaining multiple copies, systems reduce the risk of permanent data loss.
Replication also supports recovery processes. When a failed system is restored, replicated data can be used to rebuild its state. This ensures continuity and reduces downtime during recovery operations.
Clustering for Distributed System Operation
Clustering involves connecting multiple systems so they function as a unified computing resource. Each system in the cluster shares responsibility for processing tasks and maintaining service availability. If one system fails, others in the cluster automatically take over its workload.
Clusters are designed to improve both performance and reliability. By distributing tasks across multiple nodes, clusters prevent any single system from becoming overloaded. This improves response times and system stability under heavy workloads.
In a fault-tolerant cluster, all nodes continuously monitor each other. If one node becomes unresponsive or fails, the remaining nodes detect the issue and redistribute tasks accordingly. This ensures that services remain available even during partial system failures.
Clusters can be configured in different ways depending on system requirements. Some clusters operate in active-active mode, where all nodes handle traffic simultaneously. Others operate in active-passive mode, where backup nodes remain idle until needed.
Load Balancing for Efficient Resource Utilization
Load balancing is a technique used to distribute workloads evenly across multiple systems or resources. Its primary goal is to prevent any single component from becoming overwhelmed while others remain underutilized.
In fault-tolerant environments, load balancing plays a dual role. It improves performance during normal operation and enhances resilience during failures. When a system becomes unavailable, the load balancer automatically redirects traffic to healthy components.
Load balancing works by continuously monitoring system performance and distributing requests based on current conditions. This ensures that workloads are dynamically adjusted as system demand changes.
In addition to improving performance, load balancing reduces the impact of failures. If one server fails, the load balancer ensures that its workload is transferred to other servers without disrupting service continuity.
Failover Mechanisms for Automatic Recovery
Failover is the process of automatically switching from a failed component to a backup system. It is one of the most important mechanisms in fault-tolerant design because it ensures continuity without manual intervention.
When a failure is detected, the system initiates failover procedures. These procedures activate backup components that are prepared to take over operations. The transition is designed to be as seamless as possible to avoid service disruption.
Failover systems rely on continuous monitoring and state synchronization. The backup system must be kept up to date with the primary system so that it can resume operations without data loss or inconsistency.
Failover can occur at different levels, including application-level failover, server-level failover, and network-level failover. Each level addresses different types of system failure scenarios.
High Availability as a Complementary Strategy
High availability is closely related to fault tolerance but focuses on minimizing downtime rather than eliminating it entirely. High availability systems aim to ensure that services remain accessible for as much time as possible, even during failures.
These systems typically use redundancy, clustering, and failover techniques to achieve their goals. However, they may allow brief interruptions during recovery processes. This makes high availability a more flexible and cost-effective approach compared to full fault tolerance.
In many real-world environments, high availability and fault tolerance are used together. High availability ensures quick recovery, while fault tolerance ensures continuous operation during failures.
Monitoring and Detection in Fault-Tolerant Systems
Monitoring systems are essential for detecting failures and triggering appropriate responses. They continuously collect data from system components and analyze performance indicators to identify abnormalities.
These indicators include response time, system load, memory usage, network latency, and error frequency. When these metrics exceed normal thresholds, the monitoring system flags potential issues.
Early detection is important because it allows systems to respond before a complete failure occurs. In many cases, systems can take corrective action when warning signs appear, preventing downtime altogether.
Monitoring also provides historical data that can be used to improve system design. By analyzing past failures, engineers can identify weaknesses and enhance system resilience.
State Management and System Synchronization
State management refers to how a system maintains information about its current operations. In fault-tolerant systems, maintaining accurate state information is essential for smooth recovery and failover.
When a system component fails, its state must be transferred to a backup component. This ensures that operations can continue from the same point without data loss or inconsistency.
Synchronization mechanisms keep system components aligned by continuously updating them with the latest information. This includes user sessions, transaction data, and application states.
Without proper synchronization, failover systems may restart operations incorrectly, leading to errors or inconsistencies. Therefore, state management is a critical part of fault-tolerant architecture.
Distributed Architecture for System Resilience
Distributed architecture involves spreading system components across multiple physical or logical locations. This reduces the risk of a single failure affecting the entire system.
In a distributed system, different components handle different tasks while communicating with each other to maintain coordination. If one location fails, other locations continue operating independently.
This structure improves both reliability and scalability. It allows systems to handle larger workloads while also providing protection against localized failures.
Distributed systems are commonly used in large-scale environments where high availability and fault tolerance are essential requirements.
Balancing Performance and Reliability
One of the challenges in fault-tolerant design is balancing performance with reliability. Techniques such as replication and redundancy improve reliability but may introduce additional processing overhead.
For example, synchronizing data across multiple systems can reduce performance due to communication delays. Similarly, maintaining multiple backup systems requires additional resources.
System designers must carefully evaluate these tradeoffs to achieve optimal performance without compromising reliability. The balance depends on system requirements, cost constraints, and acceptable risk levels.
Integration of Fault Tolerance Techniques in System Design
Fault tolerance is most effective when all techniques work together as part of a unified system design. Redundancy provides backup components, replication ensures data consistency, clustering improves distribution, load balancing manages workload, and failover enables automatic recovery.
Each technique supports the others, creating a layered defense against system failure. This integration ensures that even if multiple issues occur simultaneously, the system can continue functioning.
A well-designed fault-tolerant system does not rely on a single protective measure. Instead, it combines multiple strategies to create a resilient and adaptive infrastructure capable of handling real-world challenges.
Designing Fault-Tolerant Systems from the Ground Up
Fault tolerance is most effective when it is integrated into a system from the earliest design stages. It is not something that can be added as an afterthought without limitations. System architects must anticipate where failures can occur and design mechanisms that reduce or eliminate their impact. This involves studying system dependencies, identifying critical components, and ensuring that alternative pathways exist for every essential function.
A key part of this design process is understanding how different system layers interact. Modern computing environments are structured in multiple layers, including hardware, operating systems, applications, and network infrastructure. A failure in any layer can potentially affect the entire system if dependencies are not carefully managed. Fault-tolerant design aims to reduce these dependencies or introduce backup mechanisms that take over when needed.
Architects also evaluate system criticality during the design phase. Systems that support essential operations require stronger fault tolerance mechanisms than systems used for less important tasks. This evaluation helps determine how much redundancy, replication, and failover capability should be included.
Identifying and Eliminating Single Points of Failure
A single point of failure is any component whose malfunction can bring down an entire system. Identifying these points is one of the most important steps in building fault-tolerant systems. These weak points can exist in hardware, software, network connections, or even configuration settings.
Once identified, these vulnerabilities are addressed through redundancy or architectural redesign. For example, if a system relies on a single server, additional servers can be introduced to distribute the workload. If a network relies on a single communication path, alternative routes can be added to ensure connectivity remains intact during failures.
Eliminating single points of failure often requires rethinking system structure. Instead of centralizing critical functions in one location, responsibilities are distributed across multiple components. This reduces dependency and improves resilience.
However, removing all single points of failure is not always practical. It increases system complexity and cost. Therefore, architects prioritize eliminating failure points that would have the most significant impact on operations.
Redundancy Implementation and Operational Strategy
Redundancy is implemented by duplicating essential system components so that backups are available when primary components fail. These duplicates may be active or passive depending on system design.
In active redundancy, all components operate simultaneously and share workload. This improves performance while providing immediate backup capability. In passive redundancy, backup components remain idle until needed. This reduces resource usage but may introduce a slight delay during failover.
Choosing between active and passive redundancy depends on system requirements. Systems requiring instant recovery often use active redundancy, while systems with limited resources may rely on passive setups.
Redundancy also applies to different system levels. Hardware redundancy ensures physical components such as power supplies or disk drives have backups. Network redundancy ensures alternative communication paths exist. Application redundancy ensures services can run on multiple instances.
Proper implementation of redundancy requires synchronization between primary and backup components. Without synchronization, switching between components may result in inconsistent system behavior or data loss.
Replication and Data Integrity Management
Replication ensures that data is stored in multiple locations so that it remains accessible even if one location fails. It is a critical component of fault-tolerant systems because data loss can have severe consequences for system continuity.
Replication strategies vary depending on system design. In synchronous replication, data is copied across all locations at the same time. This ensures strong consistency but may slow down system performance due to communication delays. In asynchronous replication, data is copied with a delay, improving performance but allowing temporary inconsistencies.
Maintaining data integrity during replication is essential. Systems must ensure that all copies of data remain accurate and up to date. If inconsistencies occur, reconciliation processes are used to restore consistency across replicas.
Replication also plays a key role in disaster recovery. If an entire system or location fails, replicated data can be used to restore operations quickly without significant data loss.
Clustering and Distributed Processing Models
Clustering connects multiple systems so they operate as a single logical unit. Each system in the cluster contributes to processing tasks and shares responsibility for maintaining system availability.
Clusters improve fault tolerance by ensuring that if one node fails, others continue operating without interruption. The system automatically redistributes workloads among remaining nodes, maintaining service continuity.
Clusters also enhance performance by enabling parallel processing. Tasks are distributed across multiple nodes, reducing the load on individual systems and improving response times.
Different clustering models exist depending on system requirements. Active-active clusters allow all nodes to process tasks simultaneously, while active-passive clusters keep backup nodes in standby mode until needed.
Cluster coordination requires communication between nodes to ensure consistent system behavior. This coordination includes monitoring node health, synchronizing data, and managing workload distribution.
Load Balancing and Traffic Distribution Control
Load balancing distributes incoming requests or workloads across multiple systems to prevent overload on any single component. It plays an essential role in both performance optimization and fault tolerance.
Load balancers monitor system health and direct traffic based on availability and capacity. If one system becomes overloaded or fails, the load balancer redirects traffic to healthier systems.
This dynamic distribution ensures that system resources are used efficiently. It also prevents bottlenecks that could degrade performance or cause system instability.
Load balancing can be implemented at different levels, including network, application, and transport layers. Each level provides different capabilities for managing traffic flow.
In fault-tolerant systems, load balancing works closely with redundancy and clustering to ensure uninterrupted service even during failures.
Failover Systems and Automatic Recovery Mechanisms
Failover is the automatic process of switching from a failed component to a backup system. It is a critical mechanism that ensures continuity without requiring manual intervention.
When a failure is detected, the system initiates failover procedures that activate backup components. These components must be fully prepared to take over operations immediately.
Failover systems rely on continuous monitoring and synchronization to ensure that backups remain updated. This allows the system to switch seamlessly without losing data or disrupting ongoing processes.
Failover can occur at multiple levels, including server failover, application failover, and network failover. Each type addresses different failure scenarios.
The speed and reliability of failover processes determine how effectively a system can maintain continuity during disruptions.
Tradeoffs Between Fault Tolerance and System Efficiency
While fault tolerance improves system reliability, it introduces tradeoffs in terms of cost, complexity, and performance. Maintaining redundant systems requires additional hardware and software resources.
Replication and synchronization processes can introduce latency, affecting system speed. Load balancing and failover mechanisms also require continuous monitoring and coordination, which adds processing overhead.
System designers must balance these tradeoffs based on operational requirements. Highly critical systems prioritize reliability over cost and performance, while less critical systems may reduce redundancy to improve efficiency.
In some cases, achieving full fault tolerance may not be practical due to resource limitations. Instead, systems are designed to achieve an acceptable level of resilience based on risk assessment.
Cost Considerations in Fault-Tolerant Design
Implementing fault tolerance increases system cost due to the need for additional infrastructure, maintenance, and management. Redundant systems require extra hardware, replication requires additional storage, and monitoring systems require continuous operation.
Organizations must evaluate whether the benefits of fault tolerance justify the cost. In critical systems, the cost of downtime is often higher than the cost of implementing fault tolerance, making it a necessary investment.
In less critical systems, organizations may choose partial fault tolerance strategies to balance cost and reliability.
Cost considerations also include long-term maintenance. Fault-tolerant systems require regular testing, updates, and monitoring to ensure that backup systems remain functional.
Role of System Management in Maintaining Fault Tolerance
System management is essential for maintaining fault-tolerant environments. Administrators are responsible for configuring redundancy, monitoring system health, and ensuring that failover mechanisms function correctly.
They also manage updates, backups, and system synchronization to maintain consistency across components. Regular testing is necessary to ensure that backup systems activate correctly during failure scenarios.
System management also involves analyzing system performance and identifying potential weaknesses. This helps improve fault tolerance over time and ensures that systems remain resilient as they evolve.
Fault Tolerance in Large-Scale and Critical Environments
In large-scale environments, fault tolerance becomes even more important due to the complexity and scale of operations. Systems may span multiple locations, data centers, or geographic regions.
These environments require advanced fault tolerance strategies, including distributed architecture, multi-region replication, and global load balancing. These mechanisms ensure that even large-scale failures do not disrupt system availability.
Critical environments such as healthcare, financial services, transportation, and industrial systems rely heavily on fault tolerance. In these cases, even brief interruptions can have significant consequences.
To address this, systems are designed with multiple layers of redundancy and continuous failover capabilities. This ensures that essential operations continue without interruption.
Evolution of Fault Tolerance in Modern Systems
Fault tolerance continues to evolve as systems become more complex and interconnected. Modern systems increasingly rely on automation, predictive analytics, and intelligent monitoring to improve resilience.
Automation reduces the need for manual intervention during failures. Predictive systems analyze patterns to detect potential failures before they occur. Intelligent monitoring improves response accuracy and speed.
These advancements make fault-tolerant systems more efficient and adaptive. As technology continues to develop, fault tolerance will remain a fundamental principle in ensuring system reliability and continuity.
Conclusion
Fault tolerance stands as one of the most important principles in the design and operation of modern computing systems. It is the foundation that allows networks, applications, and infrastructures to remain functional even when unexpected failures occur. Rather than focusing on preventing every possible error, fault tolerance accepts that failure is inevitable and builds systems capable of continuing operation despite those failures. This mindset shift is what makes today’s large-scale, interconnected digital environments possible.
It becomes clear that fault tolerance is not a single feature but a combination of many carefully coordinated techniques. Redundancy ensures that backup components are always available when needed. Replication protects critical data by maintaining multiple synchronized copies. Clustering allows systems to operate as unified groups where workloads can shift dynamically. Load balancing ensures that no single system becomes overwhelmed, while failover mechanisms guarantee automatic recovery when failures occur. Each of these techniques plays a distinct role, but their true strength comes from how they work together as a unified strategy.
In real-world environments, fault tolerance directly influences system reliability, user experience, and business continuity. Systems that support essential services must be designed to handle failure without interrupting operations. Even brief downtime can lead to significant consequences in sectors such as finance, healthcare, transportation, and communication. For this reason, fault tolerance is not optional in critical systems; it is a core requirement.
However, achieving fault tolerance is not without challenges. It introduces additional complexity, cost, and resource requirements. Maintaining redundant systems, synchronizing data across multiple locations, and continuously monitoring system health all require careful planning and ongoing management. There is also a balance that must be maintained between performance and reliability. Systems that prioritize extreme fault tolerance may require additional processing overhead, while those that focus on efficiency may reduce redundancy. Designing a system involves finding the right equilibrium based on operational needs and risk tolerance.
Another important insight is that fault tolerance is not static. It evolves alongside technology and system demands. Modern systems increasingly rely on automation, predictive analysis, and intelligent monitoring to improve resilience. These advancements allow systems to detect potential failures before they occur and respond more efficiently when disruptions happen. As computing environments continue to grow in scale and complexity, fault tolerance will become even more deeply integrated into system architecture.
Ultimately, fault tolerance reflects a fundamental truth about technology: no system is perfect, but systems can be designed to be resilient. By anticipating failure, distributing responsibility, and building recovery mechanisms into the core architecture, engineers create systems that are capable of sustaining operation under real-world conditions. This resilience is what enables modern digital infrastructure to support the continuous, reliable services that societies and industries depend on every day.