In Linux operating systems, every running program is treated as a process, and the operating system is responsible for managing how these processes are created, executed, paused, and terminated. When a user launches a command or application from a terminal, the shell acts as the parent process, and any new processes spawned from it become child processes. This parent-child relationship forms the foundation of process management in Linux and plays a critical role in how system resources are allocated and controlled across multiple running tasks.
The shell is not just an interface for entering commands; it is itself a process that maintains control over the execution environment. When a command is executed, the shell may either run it directly or create a new child process using system calls such as fork and exec. This mechanism allows Linux to maintain strict control over process creation while ensuring that each process operates in an isolated environment.
When a user logs out of a Linux session, the shell process is terminated. At this point, the operating system evaluates all child processes associated with that shell. Depending on how they were started, these child processes may either terminate automatically, continue running in the background, or be reassigned to another parent process, such as the init or systemd process. This reassignment ensures that no process becomes unmanaged or orphaned, which could otherwise lead to resource leaks or instability in the system.
Linux follows a structured approach to process lifecycle management. Each process is assigned a unique process identifier that allows the system to track and control it throughout its lifetime. This identifier is used for scheduling, monitoring, signaling, and termination. Without this structured tracking system, managing multiple simultaneous processes would become impossible in a complex multitasking environment.
A key concept in Linux process management is that processes do not execute continuously. Instead, execution is distributed over time using a scheduling system. If every process were allowed to run without interruption, system performance would degrade rapidly due to CPU overload. Instead, Linux uses time-sharing, where each process is given a small time slice to execute before being paused and replaced by another process.
This time-sharing approach allows multiple applications to appear as if they are running simultaneously, even though the CPU is rapidly switching between them. This illusion of parallelism is essential for modern computing environments, where users expect responsiveness even when many background tasks are running.
To support this behavior, Linux defines different process states that describe what a process is doing at any given moment. These states provide a structured way for the operating system to determine whether a process should run, wait, or terminate. Each state reflects a specific condition in the process lifecycle, such as active execution, waiting for resources, or completion of execution.
Process states also play an important role in debugging and performance analysis. By observing process states, system administrators can identify whether a system is overloaded, whether processes are stuck waiting for resources, or whether there are inefficiencies in scheduling. This makes process state understanding a fundamental skill for system performance tuning and troubleshooting.
Why Linux Uses Multiple Process States
Modern operating systems are built to handle multitasking, where many processes execute in overlapping time intervals. However, a CPU can only execute one instruction stream per core at any given moment. Even in multi-core systems, there is still a finite limit to simultaneous execution. This limitation makes it necessary to carefully manage how processes are scheduled.
To address this challenge, Linux uses a process scheduler that rapidly switches between processes. This switching happens so quickly that users perceive all processes as running simultaneously. However, behind the scenes, only a subset of processes are actively executing at any moment, while others are waiting their turn.
Because processes cannot always execute immediately, they must transition between different states depending on system conditions. These states represent whether a process is actively running, ready to run, waiting for input, or suspended due to external conditions. This classification allows the scheduler to make intelligent decisions about CPU allocation.
Without process states, the operating system would lack visibility into process behavior. It would not be able to determine which processes are ready for execution or which are blocked. This would lead to inefficient CPU usage, increased latency, and poor system responsiveness.
Process states also provide important diagnostic value. When systems experience performance issues, administrators can examine process states to identify bottlenecks. For example, a large number of runnable processes may indicate CPU saturation, while many processes in a sleep state may indicate I/O bottlenecks or external dependency delays.
In addition, process states help maintain system stability. By clearly defining whether a process can be interrupted or not, Linux ensures that critical operations are protected from unsafe termination. This is especially important during disk operations, kernel interactions, and hardware communication.
Overview of the 5 Linux Process States
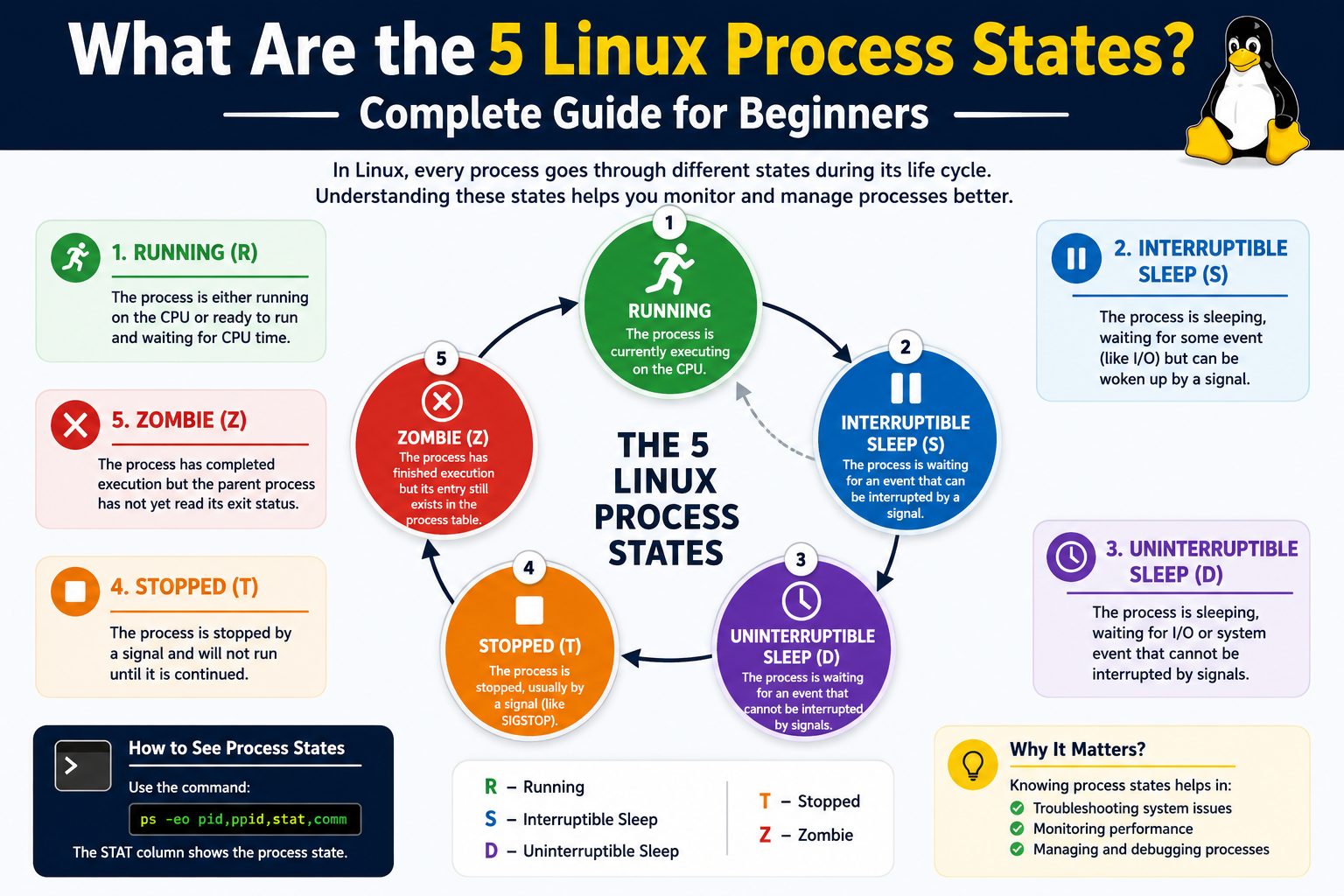
Linux defines five primary process states that describe how a process behaves throughout its lifecycle. These states include running or runnable, interruptible sleep, uninterruptible sleep, stopped, and zombie. Each state represents a specific operational condition and helps the operating system manage processes efficiently.
The running or runnable state refers to processes that are either actively executing or waiting to be executed. These processes are either consuming CPU resources or queued for CPU allocation.
The interruptible sleep state refers to processes that are waiting for external events such as user input, file access, or network responses. These processes are idle and can be interrupted if necessary.
The uninterruptible sleep state refers to processes waiting for critical system resources. These processes cannot be interrupted until the required operation completes, ensuring system stability during sensitive tasks.
The stopped state refers to processes that have been suspended manually or programmatically. These processes are not executing and remain paused until explicitly resumed.
The zombie state refers to processes that have completed execution but remain in the process table because their parent process has not yet acknowledged their termination.
Each of these states plays a unique role in process lifecycle management and contributes to overall system efficiency and reliability.
Process Scheduling and CPU Allocation in Linux
The Linux kernel uses a scheduling system to manage how processes receive CPU time. The scheduler is responsible for deciding which process runs next, how long it runs, and when it should be paused. This decision-making process is continuous and highly dynamic.
Since multiple processes often compete for CPU time, the scheduler maintains a run queue containing all processes that are ready to execute. From this queue, the scheduler selects processes based on priority levels, fairness policies, and system load conditions.
Once a process is selected, it is assigned to a CPU core and allowed to execute for a fixed time slice. After this time slice expires, or if the process becomes blocked, it is moved to another state. This continuous switching between processes is known as context switching.
Context switching is essential for multitasking, but it also introduces overhead. Each switch requires saving the state of the current process and loading the state of the next process. Despite this overhead, it is necessary to maintain system responsiveness and fairness.
In modern Linux systems, advanced scheduling algorithms are used to optimize performance. These algorithms aim to balance system load, reduce latency, and ensure fair CPU distribution among processes of different priorities.
Running and Runnable Process State Explained
The running and runnable states are often discussed together because they represent closely related conditions in process execution. A running process is actively executing on a CPU core. It is performing computations, executing instructions, or handling system calls.
A runnable process, on the other hand, is ready to execute but is waiting for CPU availability. It has all the necessary resources except for processor time. These processes are placed in the run queue and will be executed when a CPU core becomes available.
The distinction between running and runnable is important in system performance analysis. A system with many running processes indicates active CPU usage, while a system with many runnable processes may indicate CPU contention.
In virtualized environments, runnable processes are more common due to shared CPU resources. Multiple virtual machines may compete for limited physical CPU capacity, leading to scheduling delays.
Monitoring these states helps identify performance bottlenecks and ensures efficient resource allocation across applications.
Interruptible Sleep State in Linux
The interruptible sleep state occurs when a process is waiting for an external event before it can continue execution. In this state, the process does not consume CPU resources and remains idle until the required condition is met.
Processes enter interruptible sleep when they are waiting for input/output operations, user interaction, or network responses. For example, a database query waiting for results or a terminal waiting for user input will typically enter this state.
One important feature of interruptible sleep is that the process can be awakened by system signals. This allows it to be terminated or modified while waiting, providing flexibility and control.
Once the required event occurs, the process transitions back to the runnable state, where it waits for CPU scheduling. This state is highly efficient because it minimizes CPU usage while maintaining responsiveness.
Uninterruptible Sleep State in Linux
The uninterruptible sleep state is a more restrictive version of sleep where the process is also waiting for an event, but cannot be interrupted by signals. This state is used during critical system operations where an interruption could cause instability or data corruption.
Processes in this state are typically involved in low-level system operations such as disk I/O, hardware communication, or kernel-level processing. Because these operations are sensitive, the process must complete its task before any interruption is allowed.
If the required resource becomes unavailable, the process may remain in this state for an extended period. In such cases, system performance may degrade, and the process may appear unresponsive.
This state is important for maintaining system integrity, but prolonged uninterruptible sleep can indicate underlying system issues such as hardware failure or network storage problems.
Why Uninterruptible Sleep Can Be Problematic
While uninterruptible sleep ensures system stability, it can sometimes create challenges in system management. Processes stuck in this state cannot be easily terminated, which may lead to resource exhaustion if multiple processes accumulate.
In severe cases, recovery may require a system reboot or hardware reset. However, these actions are typically avoided unless necessary due to their disruptive nature.
Understanding this state is essential for diagnosing system hangs and identifying hardware or kernel-related issues.
Importance of Sleep States in System Efficiency
Sleep states play a vital role in optimizing CPU usage and improving overall system performance. Instead of continuously consuming CPU cycles, processes remain idle until they are needed.
Interruptible sleep allows flexibility and responsiveness, while uninterruptible sleep ensures stability during critical operations. Together, these states create a balanced system capable of handling complex multitasking workloads efficiently.
Introduction to Advanced Linux Process States
After understanding how running, runnable, and sleep states function in Linux, it becomes important to explore the remaining process states that deal with process control, suspension, and termination. These include the stopped state and zombie state, which play a critical role in how processes are paused, resumed, and cleaned up by the operating system.
While sleep states deal with waiting for resources, stopped and zombie states represent more explicit control over process execution and lifecycle completion. These states are essential for system administration, debugging, and managing application behavior in both user-space and kernel-space environments.
Understanding these states also helps in diagnosing unusual system behavior, such as unresponsive applications, lingering processes, or resource leaks caused by improperly terminated programs.
Stopped Process State in Linux
The stopped state in Linux refers to a process that has been deliberately paused and is not currently executing any instructions. Unlike sleep states, where processes wait for events or resources, a stopped process is explicitly suspended, usually by a user or system signal.
A common way to stop a process is by using keyboard shortcuts such as Control+Z in a terminal. When this action is performed, the running foreground process is moved into a suspended state, meaning it is removed from execution but still exists in memory and retains its state.
In this condition, the process does not consume CPU resources and remains completely inactive until it is resumed. This makes the stopped state useful for temporarily pausing long-running tasks without terminating them.
The operating system marks stopped processes with a specific state indicator so that they can be easily identified and managed. These processes can later be resumed either in the foreground or background, depending on user preference.
How Process Suspension Works in Linux
When a process is stopped, the Linux kernel receives a signal that instructs it to pause execution. This signal is typically SIGSTOP or SIGTSTP. Once received, the kernel immediately halts the process and updates its state in the process table.
Unlike sleep states, a stopped process does not wait for external resources. Instead, it is completely frozen, preserving its memory state, register values, and execution context. This allows the process to resume exactly where it left off.
The process remains in this suspended state until it receives a SIGCONT signal, which instructs the kernel to resume execution. At that point, the process returns to the runnable state and waits for CPU scheduling.
This mechanism allows users and system administrators to control process execution without terminating applications. It is especially useful in terminal environments where multiple tasks need to be managed interactively.
Foreground and Background Process Control
Linux provides powerful process control capabilities through foreground and background execution modes. A foreground process is one that actively interacts with the terminal and receives user input directly. In contrast, a background process runs without blocking the terminal, allowing other commands to be executed simultaneously.
When a process is running in the foreground, it can be suspended using Control+Z. Once suspended, it becomes a stopped process and can be moved to the background using job control commands.
Background execution is useful for long-running tasks such as file transfers, system updates, or data processing operations. These tasks can continue running without blocking user interaction in the terminal.
The ability to switch between foreground and background states provides flexibility in multitasking environments and improves productivity in command-line workflows.
Resuming Stopped Processes
A stopped process can be resumed in two primary ways. It can either be brought back to the foreground or continued in the background. When resumed in the foreground, the process regains control of the terminal and resumes interaction with the user.
When resumed in the background, the process continues execution without terminal interaction. This allows the user to continue working on other tasks while the process runs independently.
The transition from stopped to running state is handled by sending a continuation signal to the process. Once this signal is received, the process returns to the runnable state and awaits CPU scheduling.
This flexibility makes process control in Linux highly dynamic and efficient for managing multiple concurrent tasks.
Introduction to Zombie Process State
The zombie state is one of the most misunderstood process states in Linux. A zombie process is not an active or running process. Instead, it is a process that has completed execution but remains in the process table because its parent process has not yet collected its exit status.
When a process finishes execution, it sends a termination signal to the operating system. However, the system does not immediately remove the process entry. Instead, it retains a minimal record so that the parent process can retrieve information about its termination.
If the parent process fails to read this information, the child process remains in the zombie state. This ensures that no process information is lost during termination.
Zombie processes do not consume CPU resources or memory for execution. However, they do occupy entries in the process table, which is a limited system resource.
Why Zombie Processes Exist
Zombie processes exist as part of a structured process termination system. When a process exits, it may have important information such as exit codes, resource usage statistics, or error states. This information is preserved temporarily until the parent process retrieves it.
This mechanism ensures proper communication between child and parent processes. Without it, important diagnostic information could be lost immediately upon process termination.
The zombie state acts as a transitional phase between active execution and complete removal from the system.
Role of Parent Processes in Cleanup
In Linux, every process has a parent process responsible for managing its lifecycle. When a child process terminates, it is the responsibility of the parent to acknowledge its termination and collect its exit status.
This process is known as reaping. Once reaped, the child process is removed from the process table and no longer appears in system monitoring tools.
If the parent process fails to perform this action, the child process remains in a zombie state. This may happen if the parent process is poorly designed, frozen, or terminated unexpectedly.
In cases where the parent process terminates before the child, the child process is typically adopted by a system-level process, which then takes responsibility for cleanup.
How Zombie Processes Affect System Resources
Although zombie processes do not consume CPU or memory resources, they still occupy entries in the process table. The process table has a finite size, and excessive zombie processes can lead to resource exhaustion.
If too many zombie processes accumulate, the system may become unable to create new processes. This can lead to application failures or system instability.
For this reason, monitoring and managing zombie processes is an important aspect of system administration.
Identifying Zombie Processes
Zombie processes can be identified using system monitoring tools that display process states. These processes are typically marked with a specific state indicator that distinguishes them from running or sleeping processes.
They appear as completed processes that still retain a process identifier but show no active execution behavior. Their presence indicates that the parent process has not yet cleaned them up.
System administrators often investigate the parent process when zombies are detected to determine whether it is functioning correctly.
Handling Zombie Processes
Zombie processes cannot be directly terminated because they are already in a completed state. Instead, the solution involves addressing the parent process.
If the parent process is functioning correctly, it will eventually reap the zombie process automatically. However, if it is not responding, it may need to be restarted or terminated.
Once the parent process is removed or fixed, the system automatically assigns orphaned processes to a system-level process that handles cleanup.
This ensures that zombie processes do not persist indefinitely.
Signals and Process Control in Linux
Linux uses signals as a mechanism to communicate with processes. Signals are asynchronous notifications sent to processes to indicate events such as termination requests, interruptions, or state changes.
Different signals serve different purposes. Some signals request graceful termination, while others force immediate termination or pause execution.
Signals are essential for process control because they allow external entities such as users or system administrators to influence process behavior without direct intervention.
For example, signals are used to stop, resume, terminate, or restart processes depending on system requirements.
Common Signal-Based Process Actions
Signals are used extensively in process management. A termination signal instructs a process to stop execution and release resources. A stop signal suspends execution without termination. A continue signal resumes a suspended process.
These signals provide fine-grained control over process behavior and allow administrators to manage system workloads effectively.
Understanding how signals interact with process states is essential for troubleshooting and controlling system behavior in Linux environments.
Relationship Between Process States and System Stability
Process states such as stopped and zombie are not just technical classifications; they are essential components of system stability and control. Stopped processes allow controlled suspension of tasks, while zombie processes ensure proper termination tracking.
Together with running and sleep states, they form a complete lifecycle model that allows Linux to manage thousands of processes efficiently.
Without these states, the operating system would struggle to maintain order, leading to inefficient resource usage and unpredictable system behavior.
Introduction to the Full Linux Process Lifecycle
Every process in Linux follows a complete lifecycle that begins when it is created and ends when it is fully removed from the system. This lifecycle is not linear but instead involves multiple transitions between different process states depending on system conditions, resource availability, and user actions.
A process typically starts in a creation phase when the system assigns it a unique process identifier and allocates memory resources. From there, it enters the runnable state where it waits for CPU scheduling. Once scheduled, it transitions into the running state and begins executing instructions.
During execution, a process may enter different waiting states depending on what it requires. It may wait for input, disk operations, or network responses, causing it to move into interruptible or uninterruptible sleep states. If manually paused, it may enter a stopped state. Finally, once execution is complete, it transitions into a terminated state and may temporarily become a zombie until fully cleaned up.
Understanding this lifecycle is essential because it explains how Linux manages thousands of processes simultaneously while maintaining system stability and performance.
Process State Transitions in Real Time
In real-world Linux systems, process states are constantly changing. A single process may transition between running, sleeping, and runnable states multiple times within seconds, depending on system load and external events.
For example, a web server process may start in a runnable state, become running when handling a request, move into interruptible sleep while waiting for a database response, and then return to runnable once the data is available.
These transitions happen extremely quickly and are managed by the Linux scheduler. The scheduler ensures that no process monopolizes CPU resources and that all processes receive fair execution time.
State transitions are not random. They are triggered by system events, user actions, hardware responses, and kernel-level decisions. This dynamic behavior allows Linux to handle complex workloads efficiently.
How Linux Monitors Process States
Linux provides multiple tools for monitoring process behavior and state changes. These tools allow system administrators to analyze CPU usage, memory consumption, and process status in real time.
One of the most commonly used tools is process status reporting, which displays detailed information about all active processes. This includes process identifiers, parent-child relationships, CPU usage, and current state.
Another widely used tool is real-time process monitoring, which provides a continuously updating view of system activity. This tool helps identify processes that consume high CPU resources or remain stuck in specific states.
System monitoring tools also display process state indicators using single-letter codes that represent each state. These codes make it easier to quickly identify whether a process is running, sleeping, stopped, or in a zombie state.
Understanding Process State Indicators
Linux uses shorthand symbols to represent process states in monitoring tools. Each symbol corresponds to a specific state and provides a quick way to interpret system behavior.
A running or runnable process is typically represented by a specific symbol that indicates active execution or readiness. Interruptible sleep is represented by another symbol that shows the process is waiting for an event, but can be interrupted. Uninterruptible sleep has its own indicator showing that the process is waiting on critical system resources.
Stopped processes are marked with a symbol indicating suspension, while zombie processes are marked with a symbol showing completed execution but incomplete cleanup.
These indicators are essential for system analysis because they provide immediate insight into what each process is doing without requiring deeper inspection.
CPU Usage and Process State Correlation
Process states are directly related to CPU usage patterns. Running processes consume CPU resources actively, while runnable processes are queued and waiting for execution. Sleep states consume minimal or no CPU resources.
A system with high CPU usage typically has many running processes or a large number of runnable processes waiting for CPU time. In contrast, a system with many sleeping processes may indicate that processes are waiting for I/O operations rather than CPU execution.
Understanding this relationship helps in diagnosing performance issues. For example, if CPU usage is high but system responsiveness is low, it may indicate excessive runnable processes or inefficient scheduling.
Memory Usage and Process Behavior
Process states also influence memory usage patterns. Running and runnable processes typically consume active memory resources because they require immediate access to data and instructions.
Sleeping processes retain memory but do not actively use CPU resources. However, if many processes are in a sleep state, they can collectively consume significant memory.
Zombie processes consume minimal memory but still occupy process table entries, which can indirectly affect system capacity if they accumulate in large numbers.
Understanding how memory interacts with process states is important for optimizing system performance and preventing resource exhaustion.
Common Causes of Process State Issues
Several system conditions can lead to abnormal process state behavior. High CPU load can cause excessive runnable processes, leading to delays in execution. Hardware or network issues can cause processes to become stuck in uninterruptible sleep.
Poorly designed applications may fail to handle signals correctly, resulting in processes that do not terminate properly or remain in a zombie state. User actions, such as improper process suspension, can also lead to stopped processes that are forgotten and left inactive.
Kernel-level issues or driver failures can also cause processes to hang in specific states, making system recovery more difficult.
Identifying the root cause of these issues requires careful analysis of process behavior and system logs.
Troubleshooting High CPU and Runnable Process Load
When a system shows a large number of runnable processes, it often indicates CPU saturation. This means the system does not have enough processing capacity to handle all active tasks efficiently.
In such cases, system administrators may need to identify resource-heavy processes and optimize or terminate them. Load balancing across multiple cores or systems may also help reduce pressure on the CPU.
Virtualized environments are particularly prone to this issue because multiple virtual machines compete for shared physical resources.
Monitoring tools help identify which processes are contributing most to CPU load and whether they are truly necessary for system operation.
Troubleshooting Stuck or Unresponsive Processes
Processes stuck in uninterruptible sleep are often the most difficult to diagnose. Since they cannot be interrupted, they may remain in this state until the underlying issue is resolved.
Common causes include disk failures, network storage disconnections, or kernel-level bugs. In such cases, restarting affected services or restoring hardware connectivity may be necessary.
If processes remain stuck for extended periods, a system reboot may be required to restore normal operation.
Understanding why a process enters this state helps prevent recurrence and improve system reliability.
Managing Zombie Processes Effectively
Zombie processes are typically harmless in small numbers but can become problematic if they accumulate. Since they occupy process table entries, excessive zombies can prevent new processes from being created.
The primary method of resolving zombie processes is ensuring that parent processes properly collect termination status from child processes. If the parent process is malfunctioning, restarting or terminating it may resolve the issue.
In well-designed systems, zombie processes are automatically cleaned up quickly and do not pose a long-term issue.
Process Prioritization and Scheduling Behavior
Linux allows processes to be assigned different priorities that influence scheduling decisions. Higher priority processes receive more CPU time, while lower priority processes may experience delays.
This prioritization ensures that critical system tasks are executed efficiently while background tasks run with lower resource impact.
Process states interact closely with priority levels. For example, a high-priority runnable process may be scheduled before lower-priority ones, even if they entered the run queue earlier.
This dynamic scheduling ensures balanced system performance under varying workloads.
Real-World Importance of Process State Knowledge
Understanding Linux process states is essential for system administrators, developers, and IT professionals working with server environments. It allows them to interpret system behavior accurately and respond to performance issues effectively.
Process state knowledge helps in identifying bottlenecks, optimizing resource usage, and ensuring system stability under heavy workloads.
It also plays a key role in debugging applications, especially in environments where multiple services run simultaneously and interact with shared system resources.
Final Understanding of Linux Process Behavior
Linux process management is built on a structured model that uses states to represent every stage of a process lifecycle. These states allow the operating system to efficiently manage CPU scheduling, memory usage, and system stability.
From creation to termination, every process moves through predictable stages that define how it interacts with system resources. This structured approach is what enables Linux to handle large-scale multitasking environments reliably and efficiently.
Conclusion
Linux process states form the foundation of how the operating system manages multitasking, resource allocation, and system stability. Every application, whether it is a simple command-line tool or a complex server application, goes through a well-defined lifecycle that includes creation, execution, waiting, suspension, and termination. These stages are represented through different process states, each serving a specific role in ensuring the system operates efficiently and reliably.
The running and runnable states highlight how Linux handles CPU scheduling by balancing active execution and queued processes. Since a CPU can only execute a limited number of instructions at any given moment, the scheduler continuously rotates processes to ensure fairness and optimal performance. This mechanism allows multiple applications to run smoothly without overwhelming system resources.
Sleep states, including interruptible and uninterruptible sleep, demonstrate how Linux manages waiting processes without wasting CPU cycles. Interruptible sleep ensures flexibility by allowing processes to pause safely while waiting for external events such as input or network responses. Uninterruptible sleep, on the other hand, protects critical system operations from interruption, maintaining data integrity during sensitive tasks like disk operations or kernel-level interactions.
The stopped state introduces controlled process suspension, enabling users to pause and resume tasks without terminating them. This is particularly useful in terminal environments where multitasking is essential. Meanwhile, the zombie state represents a completed process that still awaits cleanup by its parent, ensuring proper retrieval of exit information before full removal from the system.
Together, these states create a complete framework for process lifecycle management. They allow Linux to maintain high performance, stability, and responsiveness even under heavy workloads. Without this structured approach, modern multitasking environments would struggle to function efficiently.
Understanding process states is not only important for theoretical knowledge but also essential for practical system administration. It helps in diagnosing performance issues, identifying resource bottlenecks, and managing system behavior under different conditions. Whether dealing with CPU overload, stuck processes, or system hangs, knowledge of process states provides the insight needed to resolve problems effectively.
In real-world environments, Linux process management ensures that systems remain stable, scalable, and capable of handling complex workloads. By combining scheduling algorithms, signal handling, and state transitions, Linux achieves a balance between performance and reliability.
Ultimately, mastering Linux process states provides a deeper understanding of how operating systems function at their core. It reveals how thousands of processes can coexist, share resources, and execute efficiently without conflict, making it a fundamental concept for anyone working with Linux systems.