Kubernetes is widely used for orchestrating containerized applications, but its learning curve often feels steep because it introduces many interconnected concepts at once. Among these, pods and containers are usually the first point of confusion for new learners. The difficulty comes from the fact that both are part of the same runtime ecosystem, yet they operate at different levels of abstraction. Containers are responsible for running applications, while pods define how those containers should be organized, managed, and executed within a cluster. Kubernetes itself is designed to solve a larger problem: managing distributed applications across multiple machines in a reliable and scalable way. Instead of running applications directly on servers, Kubernetes breaks them into smaller components and manages them through a structured system. This structure is what makes understanding pods and containers essential before moving into more advanced topics like deployments, services, and scaling strategies. Without a clear understanding of these two building blocks, the rest of Kubernetes can feel unnecessarily complex.
Why Modern Applications Depend on Containerization
Before understanding pods, it is important to understand why containers exist in the first place. Modern applications are no longer deployed as single monolithic systems. Instead, they are divided into smaller services that can be developed, deployed, and scaled independently. This approach improves flexibility and makes applications easier to maintain. Containers provide the perfect environment for this architecture because they package everything an application needs to run into a single portable unit. This includes the application code, runtime environment, system libraries, and configuration dependencies. Because everything is bundled together, a container behaves consistently regardless of where it is deployed. This solves one of the biggest traditional problems in software development, where applications worked in one environment but failed in another due to missing dependencies or configuration mismatches. Containers eliminate this inconsistency by ensuring that the runtime environment is identical everywhere.
Another important reason containers are widely used is efficiency. Unlike virtual machines, containers do not require a full operating system for each instance. Instead, they share the host system’s kernel, making them lightweight and faster to start. This efficiency allows organizations to run many containers on a single machine without overwhelming system resources. As a result, containers have become the standard unit of deployment in cloud-native systems.
Understanding Container Images as the Foundation of Execution
Every container begins its life as a container image. A container image is essentially a blueprint that defines how a container should be created. It contains the application code, system libraries, dependencies, and configuration files needed to run the application. When a container is launched, it is created from this image, ensuring that every instance behaves in exactly the same way. This immutability is a key concept in containerization. Once an image is built, it does not change during execution. Instead, if changes are needed, a new image is created and deployed as a new container instance.
Container images are usually stored in centralized repositories known as registries. These registries allow systems to pull images whenever a container needs to be created. In a Kubernetes environment, this process is automated. When a pod is scheduled to run on a node, the container runtime pulls the required image from the registry and creates the container instance. This ensures that applications can be deployed consistently across large clusters without manual intervention.
Another important aspect of container images is versioning. Applications evolve over time, and each version of an application can be stored as a separate image tag. This allows teams to roll back to previous versions if needed or gradually roll out updates across a cluster. This version control mechanism is essential for maintaining stability in production environments where downtime must be minimized.
What a Container Actually Represents in a Running System
A container is the runtime instance created from a container image. It represents a live environment where the application process runs. Once a container is started, it executes the instructions defined in the image and begins performing its designated function, such as serving web requests, processing data, or running background tasks. Each container is isolated from others, meaning it has its own file system, process space, and network configuration. This isolation ensures that containers do not interfere with one another, even when running on the same physical machine.
However, despite this isolation, containers are not completely independent in Kubernetes. They rely on the orchestration layer to define how they should behave, when they should start or stop, and how they should interact with other components. This is where Kubernetes introduces the concept of pods, which provide structure and coordination for containers.
Containers are intentionally designed to be lightweight and disposable. They are not meant to store long-term data or maintain persistent state. Instead, they are expected to be replaced or recreated as needed. This design aligns with modern cloud-native principles where applications are treated as ephemeral components that can be scaled up or down dynamically based on demand.
Introduction to Pods as the Core Kubernetes Abstraction
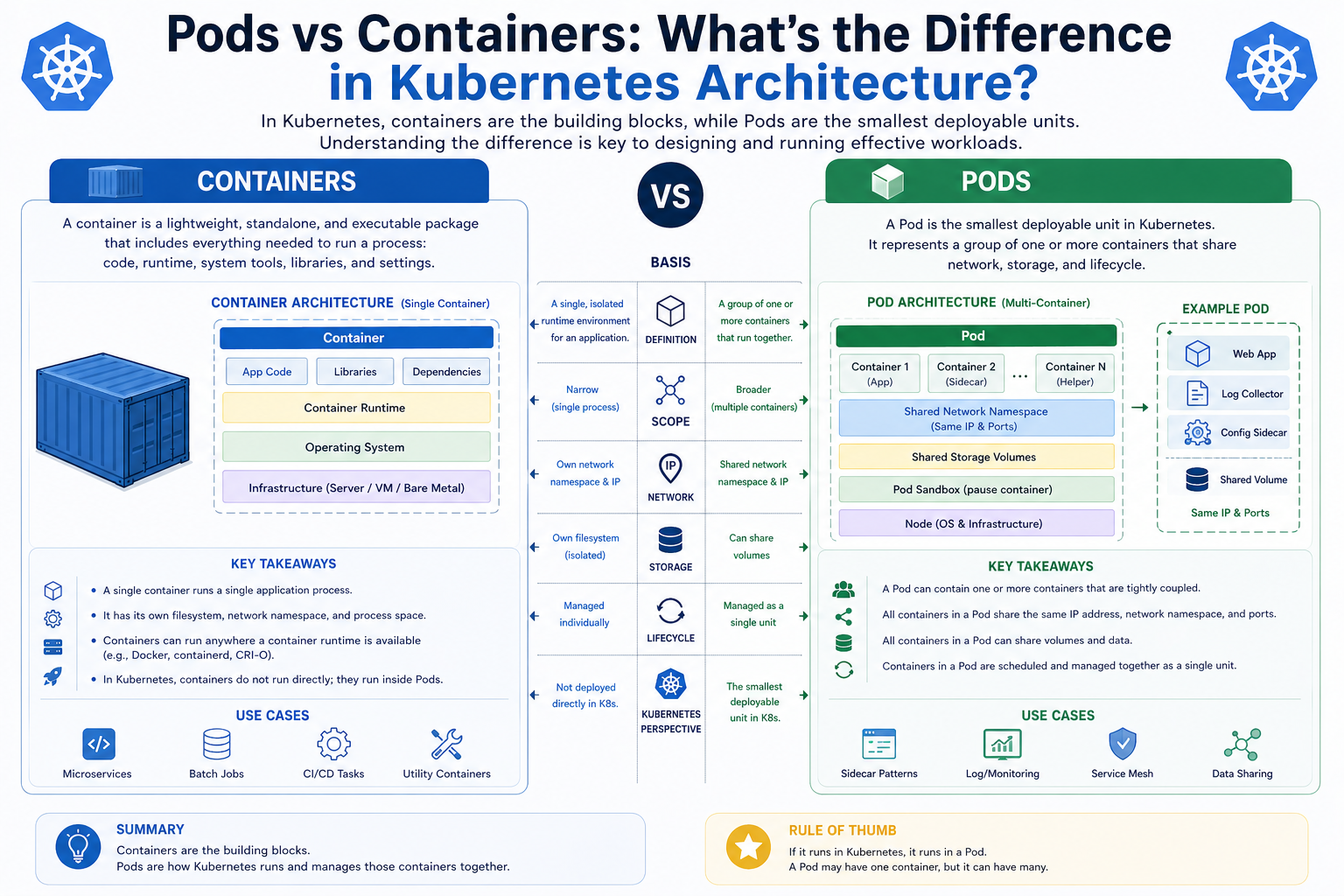
A pod is the smallest and most fundamental unit in Kubernetes. While containers are responsible for running applications, pods are responsible for managing those containers. A pod acts as a wrapper that defines how one or more containers should be deployed and executed together. This abstraction allows Kubernetes to treat multiple containers as a single unit of deployment, scheduling, scaling, and management.
The reason Kubernetes uses pods instead of managing containers directly is because real-world applications often require more than one container to function properly. For example, an application might need a main service container along with a logging or monitoring sidecar container. Instead of managing these containers separately, Kubernetes groups them into a single pod so they can share resources and operate as a unified system.
Each pod has its own unique identity within the Kubernetes cluster. This includes a dedicated IP address and network namespace. Containers inside the same pod share this network identity, allowing them to communicate using localhost. This design simplifies communication between tightly coupled services and reduces the complexity of network configuration.
Why Pods Exist as an Abstraction Layer Above Containers
Pods exist to solve a fundamental orchestration problem. Managing containers individually at scale would be inefficient and error-prone. Applications often consist of multiple interdependent components that need to be deployed together, scaled together, and managed together. Pods provide a way to group these components logically.
By introducing pods, Kubernetes can apply policies at a higher level instead of dealing with individual containers. This includes scheduling decisions, resource allocation, restart policies, and networking rules. When Kubernetes schedules a pod, it automatically ensures that all containers inside it are deployed together on the same node. This guarantees consistency in execution and avoids fragmentation of application components.
Another reason pods are necessary is that they define shared execution context. Containers inside a pod share the same storage volumes, network interface, and lifecycle. This shared environment allows containers to work closely together without needing complex external configuration. For example, one container might generate data while another processes it, and both can communicate efficiently within the same pod.
Declarative Configuration and How Pods Are Defined
Kubernetes uses a declarative approach to define pods. Instead of manually instructing the system step by step, users describe the desired state of the system, and Kubernetes ensures that state is achieved. A pod definition typically includes metadata such as the pod name, labels for identification, and a specification section that defines containers and their behavior.
Inside the specification, each container is defined along with its image, resource requirements, and runtime configuration. This includes instructions such as CPU limits, memory allocation, environment variables, and security policies. Kubernetes continuously monitors the system and ensures that the running state matches the desired configuration. If a deviation occurs, such as a container failure, Kubernetes takes corrective action automatically.
This declarative model is one of the reasons Kubernetes is highly scalable. It reduces the need for manual intervention and allows systems to self-heal when issues occur. Instead of directly managing infrastructure, administrators define what they want, and Kubernetes handles how to achieve it.
Resource Management and Allocation Within Pods
One of the most important responsibilities of a pod is managing system resources for its containers. Each container within a pod can specify how much CPU and memory it requires. These values are used by Kubernetes during scheduling to determine which node in the cluster is best suited to run the pod. This ensures that workloads are distributed efficiently and no single node becomes overloaded.
Resource limits are also used to prevent containers from consuming more resources than allowed. This is critical in multi-tenant environments where multiple applications share the same infrastructure. Without resource limits, a single poorly optimized application could degrade the performance of the entire system. Pods enforce these boundaries to maintain system stability and fairness across workloads.
Resource requests, on the other hand, define the minimum resources required for a container to operate effectively. Kubernetes uses this information to ensure that containers are scheduled onto nodes that can meet their minimum requirements. This helps avoid performance issues caused by insufficient resources.
Ephemeral Nature and Lifecycle Behavior of Pods
Pods are designed to be temporary rather than permanent. This means they are expected to be created, run, and replaced rather than modified in place. If changes are required, the existing pod is typically deleted and replaced with a new one that includes updated specifications. This immutability ensures consistency and reduces complexity in managing application states.
The lifecycle of a pod is managed by Kubernetes controllers, which monitor the state of the system and ensure that the desired number of replicas is always running. If a pod fails, it is automatically recreated. If demand increases, additional pods can be created to handle the load. This dynamic lifecycle management is what enables Kubernetes to provide high availability and scalability.
Containers inside pods follow similar lifecycle rules. They start when the pod is created and stop when the pod is terminated. If a container crashes, Kubernetes can restart it based on the defined restart policy. This ensures that applications remain available even in the presence of failures.
Networking Model Inside Pods and Communication Patterns
Networking is another area where pods play a critical role. Each pod is assigned a unique IP address, and all containers within that pod share this address. This means that containers inside the same pod can communicate with each other using localhost, as if they were running on the same machine. This simplifies inter-container communication significantly.
Outside the pod, communication is handled through Kubernetes networking components that route traffic between pods and services. This abstraction allows developers to focus on application logic rather than low-level networking details. Pods provide a clean boundary for networking, ensuring that each application component has a predictable communication interface.
This model also supports scalability. Since each pod has its own IP address, multiple instances of the same application can run simultaneously without conflicts. Kubernetes handles routing and load balancing between these instances automatically.
Shared Storage and Execution Context in Pods
Pods also allow containers to share storage volumes. This shared storage is useful for scenarios where multiple containers need access to the same data. For example, one container might write logs or generate files, while another container processes or reads them. By sharing storage at the pod level, Kubernetes enables efficient data exchange without requiring external systems.
This shared context extends beyond storage and networking. Pods also define shared environment variables, configuration settings, and security contexts. This ensures that all containers within a pod operate under consistent conditions, reducing the chances of configuration mismatches or runtime errors.
How Kubernetes Orchestrates Containers Through Pods
Kubernetes does not manage containers directly in isolation; instead, it relies on pods as the primary scheduling and execution unit. When an application is deployed, Kubernetes takes the pod specification and determines where it should run within the cluster. This decision is handled by the scheduler, which evaluates available nodes based on resource availability, constraints, and workload distribution. Once a node is selected, the pod is assigned to it, and the container runtime on that node is responsible for starting the containers defined in the pod. This layered architecture ensures that Kubernetes remains scalable and consistent, even when managing thousands of containers across multiple machines. The pod acts as a contract that defines exactly how containers should behave, while Kubernetes ensures that this contract is fulfilled across the cluster.
This orchestration model is designed to abstract infrastructure complexity. Instead of worrying about individual machines or processes, users define desired application behavior, and Kubernetes handles execution. Pods serve as the bridge between declarative configuration and actual runtime execution. This separation of concerns allows developers to focus on application logic rather than system-level management.
The Role of the Kubernetes Scheduler in Pod Placement
The scheduler plays a critical role in determining where pods run. It evaluates multiple factors before assigning a pod to a node. These factors include CPU and memory availability, node health, affinity rules, and taints or tolerations. The goal is to ensure that workloads are distributed efficiently and that no single node becomes overloaded.
Once a pod is scheduled, it remains bound to that node unless it is deleted or rescheduled due to failure. This immutability is important because it ensures stability in application execution. If a node becomes unavailable, Kubernetes automatically creates a replacement pod on another node to maintain the desired state. This process is part of Kubernetes’ self-healing capability, which ensures high availability even in dynamic environments.
Pods also allow scheduling constraints to be defined explicitly. For example, a pod can be configured to run only on nodes with specific hardware characteristics or within certain geographic zones in a distributed cluster. This level of control allows organizations to optimize performance and comply with operational requirements.
Container Runtime and How Pods Translate Into Running Processes
Once a pod is assigned to a node, the container runtime takes over. The runtime is responsible for pulling container images, creating container instances, and managing their execution lifecycle. Common runtimes include container engines that follow standardized interfaces for running containers.
When a pod is created, the runtime pulls the required images from a registry and initializes containers based on the pod specification. Each container runs in isolation but shares certain resources with other containers in the same pod. The runtime ensures that containers start in the correct order and that they adhere to the configuration defined in the pod.
This translation from pod specification to running containers is automatic. Users do not need to manually start or manage containers. Instead, Kubernetes continuously reconciles the desired state with the actual state, making adjustments whenever discrepancies occur.
Sidecar, Ambassador, and Adapter Patterns in Pod Design
Pods support advanced architectural patterns that help structure complex applications. One of the most common is the sidecar pattern, where an additional container runs alongside the main application container to provide supporting functionality. This could include logging, monitoring, or data synchronization tasks. Because all containers in a pod share the same network and storage context, sidecar containers can easily interact with the main container.
Another pattern is the ambassador pattern, where a container acts as a proxy for external communication. This container handles requests to external services and abstracts connectivity logic away from the main application. Similarly, the adapter pattern transforms data or communication formats between different systems, allowing applications to integrate with external services more easily.
These patterns demonstrate the flexibility of pods as a deployment unit. Instead of limiting applications to a single container, Kubernetes allows multiple containers to work together within the same execution environment. This modular approach simplifies complex system design.
Networking Behavior and Shared Identity in Pods
Networking in Kubernetes is built around the concept of flat networking, where every pod receives a unique IP address. This design eliminates the need for traditional network address translation between containers. All containers within a pod share the same network namespace, meaning they can communicate using localhost.
This shared networking model simplifies communication between containers that need to work closely together. For example, a logging container can immediately access data generated by the main application container without requiring external network calls. This reduces latency and improves performance.
Outside the pod, Kubernetes uses services to manage communication between different pods. Services provide stable endpoints that route traffic to dynamically changing pod instances. This ensures that even if pods are replaced or scaled up, external communication remains consistent.
Storage Management and Volume Sharing in Pods
Pods also support shared storage through volumes. A volume is a directory that is accessible to all containers within a pod. Unlike container file systems, which are ephemeral and disappear when a container is deleted, volumes can persist data beyond the lifecycle of individual containers.
Shared volumes are useful in scenarios where multiple containers need to read and write data collaboratively. For example, one container might generate logs or output files, while another container processes or archives that data. Because both containers share the same storage space, data exchange becomes efficient and straightforward.
Kubernetes supports different types of volumes, including temporary storage and persistent storage that survives pod restarts. Persistent storage is particularly important for stateful applications that require data durability. Even though pods themselves are ephemeral, storage can be configured to persist independently.
Pod Lifecycle Management and Restart Policies
Pods are designed with a defined lifecycle that includes creation, running, and termination phases. Once a pod is created, it remains active until it completes its task or is explicitly deleted. If a container within a pod fails, Kubernetes can restart it based on the restart policy defined in the pod specification.
Restart policies determine how Kubernetes handles container failures. A policy might specify that containers should always restart, never restart, or restart only under certain conditions. This flexibility allows applications to be tailored for different operational requirements.
When a pod is terminated, it is not modified in place. Instead, Kubernetes replaces it with a new instance if needed. This ensures consistency and avoids configuration drift. The system continuously monitors pods to ensure they match the desired state defined by the user.
Health Monitoring and Self-Healing Mechanisms
Kubernetes includes built-in mechanisms to monitor the health of pods and containers. These mechanisms include readiness checks and liveness checks. Readiness checks determine whether a container is ready to accept traffic, while liveness checks determine whether a container is still functioning correctly.
If a liveness check fails, Kubernetes can automatically restart the container. If a readiness check fails, the container is temporarily removed from service routing until it becomes healthy again. This ensures that only healthy containers receive traffic, improving application reliability.
Self-healing is a core feature of Kubernetes. If a node fails or becomes unreachable, pods running on that node are automatically rescheduled to healthy nodes. This process happens without manual intervention, ensuring continuous availability.
Scaling Behavior and Pod Replication
Scaling in Kubernetes is achieved by creating multiple instances of the same pod. These instances are distributed across the cluster to balance load and improve performance. When demand increases, additional pods can be created automatically. When demand decreases, excess pods can be removed.
This horizontal scaling approach allows applications to handle varying levels of traffic efficiently. Instead of increasing the resources of a single container, Kubernetes spreads the workload across multiple identical pods. Each pod operates independently, but all pods share the same configuration and behavior.
This replication model also improves fault tolerance. If one pod fails, others continue to serve traffic without disruption. This redundancy is essential for building resilient distributed systems.
Configuration Management Inside Pods
Pods support configuration through environment variables, configuration files, and secrets. Environment variables allow dynamic values to be passed into containers at runtime. Configuration files can be mounted into containers using volumes, enabling more complex configuration structures. Secrets provide a secure way to store sensitive information such as credentials or API keys.
These configuration mechanisms allow applications to be flexible and environment-independent. The same container image can be used across development, testing, and production environments with different configurations applied through the pod specification.
This separation of configuration from application code is a key principle in modern cloud-native design. It allows applications to be deployed consistently while still adapting to different environments.
Security Context and Access Control Within Pods
Security is an important aspect of pod design. Pods allow security contexts to be defined, which control how containers run at the operating system level. This includes user permissions, privilege escalation settings, and access controls.
By defining security policies at the pod level, Kubernetes ensures that containers run with the minimum required privileges. This reduces the risk of security vulnerabilities and limits potential damage from compromised applications.
Security contexts also control capabilities such as file system access and network permissions. These controls help enforce isolation between applications running in the same cluster.
Inter-Pod Communication and Service Abstraction Layer
While containers within a pod communicate directly, communication between different pods is handled through services. Services provide stable network endpoints that abstract away the dynamic nature of pods. Since pods can be created and destroyed frequently, services ensure that applications can still communicate reliably.
This abstraction layer is essential for building scalable systems. Instead of relying on fixed IP addresses, applications interact with services that automatically route traffic to healthy pods. This ensures continuity even during scaling events or failures.
Services also support load balancing, distributing traffic evenly across multiple pod instances. This improves performance and ensures that no single pod becomes a bottleneck.
Resource Isolation and Multi-Tenancy in Kubernetes
Kubernetes clusters often run multiple applications belonging to different teams or environments. Pods provide resource isolation to ensure that these applications do not interfere with each other. Resource quotas and limits prevent any single pod from consuming excessive resources.
This isolation is critical in multi-tenant environments where multiple workloads share the same infrastructure. It ensures fairness and stability across the system.
Pods also support namespace-based isolation, allowing logical separation of resources within a cluster. This helps organize applications and manage access control effectively.
How Pods Enable Modern Cloud-Native Architecture
Pods are foundational to cloud-native architecture because they enable modular, scalable, and resilient application design. By grouping containers into logical units, Kubernetes simplifies deployment and management of complex systems.
This design allows applications to be broken into microservices, each running in its own container or group of containers. Pods provide the structure needed to manage these microservices effectively.
The combination of containers and pods enables a flexible architecture that can adapt to changing workloads, failure conditions, and scaling requirements.
Evolving from Basic Pods to Production-Grade Kubernetes Workloads
As Kubernetes usage moves from learning environments into production systems, the role of pods becomes significantly more sophisticated. In simple setups, a pod may contain a single container running a basic application. In production environments, however, pods are designed as carefully structured units that support resilience, scalability, observability, and security at enterprise scale. The shift is not just about running containers, but about designing systems that can survive failure, scale under pressure, and integrate seamlessly with other services. Pods act as the foundation of this design, but their behavior is shaped by controllers, policies, and infrastructure constraints that extend far beyond basic container execution.
At this level, understanding pods means understanding how they behave in clusters with hundreds or thousands of nodes, where workloads are constantly moving, scaling, and restarting. The abstraction that initially seems simple becomes the core building block of distributed systems engineering.
ReplicaSets and the Role of Pod Duplication in Scalability
One of the most important concepts in production Kubernetes environments is replication. A single pod is not sufficient to handle real-world traffic for most applications. Instead, multiple identical pods are created and managed as a group. This is achieved through higher-level controllers such as ReplicaSets, which ensure that a specified number of pod instances are always running.
Replication is not just about performance; it is also about resilience. If one pod fails due to hardware issues, software crashes, or network interruptions, other pods continue serving traffic without disruption. Kubernetes automatically replaces failed pods to maintain the desired state. This ensures that the system remains stable even under unpredictable conditions.
Replication also enables horizontal scaling. Instead of increasing the size of a single container, Kubernetes spreads workload across multiple pod instances. This approach aligns with cloud-native design principles where systems scale out rather than scale up. It allows applications to handle sudden spikes in demand without requiring manual intervention.
Deployments and Controlled Updates to Pod Versions
While ReplicaSets manage the number of pods, Deployments manage how those pods are updated over time. In real-world systems, applications are not static. They evolve through version updates, configuration changes, and security patches. Deployments provide a controlled mechanism for rolling out these changes without disrupting service availability.
When a new version of an application is introduced, Kubernetes does not replace all pods at once. Instead, it gradually replaces old pods with new ones, ensuring that the system remains operational throughout the update process. This strategy is often referred to as rolling updates.
This controlled replacement is crucial in production environments where downtime is unacceptable. If a new version introduces issues, Kubernetes can roll back to the previous version by restoring the earlier pod configuration. This ability to manage application evolution safely is one of the key strengths of Kubernetes.
Stateful vs Stateless Pod Design Considerations
Not all applications behave the same way, and Kubernetes must support both stateless and stateful workloads. Stateless applications do not retain data between requests, meaning any pod instance can handle any request without dependency on previous interactions. These applications are easier to scale because pods can be created or destroyed freely without affecting system behavior.
Stateful applications, on the other hand, require persistent data storage and stable identity. These applications include databases, messaging systems, and distributed storage systems. In Kubernetes, stateful workloads require additional configuration to ensure that data remains consistent and accessible even when pods are restarted or moved.
To support this, Kubernetes introduces specialized patterns where pods maintain persistent storage bindings and stable network identities. This ensures that even though pods are ephemeral, the data they rely on is not lost during lifecycle changes.
Pod Identity and Networking Stability in Large Clusters
In large Kubernetes clusters, maintaining consistent communication between services becomes critical. Each pod is assigned a unique IP address, but these IPs are not permanent. When pods are recreated, they may receive different IP addresses. This creates a challenge for communication between services that depend on stable endpoints.
To solve this, Kubernetes uses abstraction layers that decouple service identity from pod identity. Instead of communicating directly with pods, applications communicate with services that automatically route traffic to available pod instances. This ensures that even if pods are replaced or scaled, communication remains uninterrupted.
This model allows Kubernetes to maintain flexibility in pod lifecycle management while ensuring stability in application communication patterns. It is one of the key architectural decisions that enables Kubernetes to function effectively at scale.
Advanced Scheduling Techniques for Pods in Distributed Systems
Scheduling pods in a cluster is not just about finding available resources. In advanced environments, scheduling decisions are influenced by multiple constraints that ensure optimal performance and compliance with operational requirements.
Affinity rules allow pods to be placed on specific nodes based on labels or metadata. This is useful when certain workloads need to run close to specific hardware resources or other related pods. Anti-affinity rules ensure that certain pods are not placed on the same node, improving fault tolerance by distributing replicas across different machines.
Taints and tolerations provide another layer of scheduling control. Nodes can be marked with specific conditions that repel certain pods unless they explicitly tolerate those conditions. This mechanism is used to isolate workloads, dedicate nodes to specific applications, or enforce security boundaries.
These scheduling strategies allow Kubernetes to operate efficiently in complex environments where workloads have different performance, security, and compliance requirements.
Observability in Kubernetes Through Pod-Level Metrics
Monitoring and observability are essential in distributed systems, and pods play a central role in generating operational data. Each pod produces metrics that reflect its performance, resource usage, and health status. These metrics are used to detect anomalies, optimize performance, and trigger scaling decisions.
Liveness and readiness probes provide real-time insights into pod health. Liveness probes determine whether a container is still functioning, while readiness probes determine whether it is ready to serve traffic. These checks ensure that only healthy pods receive requests.
In addition to health checks, pods also generate logs and telemetry data that help operators understand application behavior. This data is aggregated and analyzed to detect performance bottlenecks, identify failures, and improve system reliability.
Observability transforms pods from simple execution units into measurable components of a larger system, enabling continuous improvement and proactive maintenance.
Security Hardening Strategies at the Pod Level
Security in Kubernetes is not applied only at the network or cluster level; it is also enforced within individual pods. Each pod can define a security context that controls how containers operate at the system level. This includes restrictions on user privileges, file system access, and process capabilities.
Running containers with non-root users is a common security practice that reduces the risk of privilege escalation attacks. Pods can enforce this behavior automatically through configuration settings. Additional controls prevent containers from modifying system-level resources or executing unauthorized operations.
Secrets management is also integrated into pod design. Sensitive information such as credentials or encryption keys is injected into pods securely without exposing them in application code. This ensures that sensitive data is protected throughout the application lifecycle.
Security policies applied at the pod level create a layered defense strategy that strengthens overall system resilience.
Multi-Container Pod Architectures in Real Applications
While many pods contain a single container, multi-container pods are common in advanced architectures. These configurations allow multiple containers to work together as a single cohesive unit. Each container has a specific responsibility, and together they form a complete application system.
One container may handle core application logic, while another handles logging, monitoring, or data synchronization. Because all containers share the same network and storage context, they can communicate efficiently without external dependencies.
This design simplifies complex workflows by grouping tightly coupled components together. It also improves performance by reducing communication overhead between related services.
Multi-container pods are especially useful in scenarios where auxiliary tasks must run alongside primary application logic without being deployed as separate services.
Failure Handling and Recovery Mechanisms in Pods
Failure is inevitable in distributed systems, and Kubernetes is designed to handle it gracefully. Pods are constantly monitored, and when failures occur, Kubernetes takes corrective action automatically.
If a container crashes, it can be restarted based on its restart policy. If a pod becomes unhealthy or unresponsive, it can be replaced entirely. If a node fails, all pods running on that node are rescheduled elsewhere in the cluster.
This automated recovery process ensures high availability and reduces the need for manual intervention. It also allows systems to continue functioning even when underlying infrastructure experiences issues.
Failure handling is one of the most important reasons Kubernetes is widely used in production environments.
Resource Optimization and Efficiency in Large-Scale Deployments
In large clusters, resource efficiency becomes critical. Pods play a key role in ensuring that CPU, memory, and storage are used effectively. Resource requests and limits allow Kubernetes to allocate resources intelligently and prevent overconsumption.
This ensures that workloads are distributed evenly across nodes and that no single node becomes a bottleneck. Efficient resource usage also reduces operational costs, especially in cloud environments where resources are billed based on usage.
Kubernetes continuously adjusts scheduling decisions based on resource availability, ensuring optimal performance across the cluster.
Integration of Pods with External Systems and APIs
Modern applications rarely operate in isolation. Pods often interact with external services such as databases, message queues, and third-party APIs. Kubernetes provides mechanisms to securely manage these integrations.
Environment variables, configuration maps, and secret management systems allow pods to connect to external systems without hardcoding sensitive information. This ensures flexibility and portability across environments.
Pods can also be configured to communicate through secure network channels, ensuring that external interactions remain protected and reliable.
The Role of Pods in Microservices Architecture
Microservices architecture divides applications into small, independent services that can be developed and deployed separately. Pods are the natural execution unit for microservices because they encapsulate each service’s runtime environment.
Each microservice typically runs inside its own pod, allowing it to scale independently and evolve without affecting other services. This modular approach improves maintainability and accelerates development cycles.
Pods provide the isolation and structure needed to manage microservices effectively in distributed environments.
How Pods Enable Cloud-Native Transformation
Pods are not just a technical concept; they represent a shift in how applications are designed and deployed. They enable cloud-native architecture by supporting scalability, resilience, automation, and modular design.
By abstracting infrastructure complexity, pods allow developers to focus on building applications rather than managing servers. This transformation has reshaped modern software development and enabled organizations to build highly scalable systems with greater efficiency.
Pods remain at the center of this transformation, acting as the foundational unit that connects containers, infrastructure, and orchestration logic into a unified system.
Final Integration of Pods and Containers in System Thinking
At a conceptual level, containers represent execution, while pods represent organization. Containers run applications, and pods define how those applications should behave in a distributed environment. Together, they form the core of Kubernetes architecture.
Understanding this relationship is essential for designing scalable and resilient systems. It allows engineers to think in terms of distributed components rather than individual machines or processes. This shift in perspective is what enables modern cloud-native applications to function at global scale.
Conclusion
The relationship between pods and containers is one of the most important foundational ideas in Kubernetes, and it shapes how modern cloud-native systems are designed, deployed, and scaled. At a basic level, a container is the actual runtime environment where an application runs, packaged with everything it needs to execute consistently across different systems. It is lightweight, portable, and isolated, making it ideal for modern distributed applications. However, containers alone do not provide enough structure for large-scale orchestration, which is where Kubernetes introduces pods.
A pod is not a replacement for a container but a management layer that organizes one or more containers into a single deployable unit. This distinction is critical because Kubernetes never operates on containers directly; it always works through pods. By grouping containers together, pods provide shared networking, storage, configuration, and lifecycle management. This allows tightly coupled containers to function as a single application component while still maintaining modularity.
One of the key insights from understanding pods is that they define execution context. Containers inside a pod share the same network identity and can communicate using localhost, which simplifies communication patterns. They can also share storage volumes, enabling efficient data exchange without external dependencies. This shared environment is what makes pods powerful in microservices architectures, where multiple small services must interact closely.
Another important takeaway is that pods are ephemeral. They are not designed to be permanently modified or manually managed. Instead, Kubernetes treats them as disposable units that can be created, replaced, or scaled automatically based on system demands. This immutability ensures consistency and supports automated recovery in case of failure. When a pod fails, Kubernetes can recreate it instantly, maintaining the desired system state without human intervention.
Containers, on the other hand, focus on execution. They run the application code, process data, and handle workloads, but they depend on pods to define how they behave in a cluster. This separation of concerns is what allows Kubernetes to scale applications across thousands of machines while maintaining stability and predictability.
In real-world systems, this relationship becomes even more important. Pods enable advanced patterns such as sidecars, multi-container architectures, rolling updates, and distributed scaling strategies. They also provide the foundation for security controls, resource management, and networking abstraction. Without pods, managing containers at scale would be significantly more complex and less reliable.
Ultimately, understanding pods and containers is not just about learning terminology. It is about understanding how modern distributed systems are structured. Containers represent the execution layer, while pods represent the organizational and operational layer that makes orchestration possible. Together, they form the backbone of Kubernetes and enable the flexibility, scalability, and resilience that modern cloud-native applications depend on.