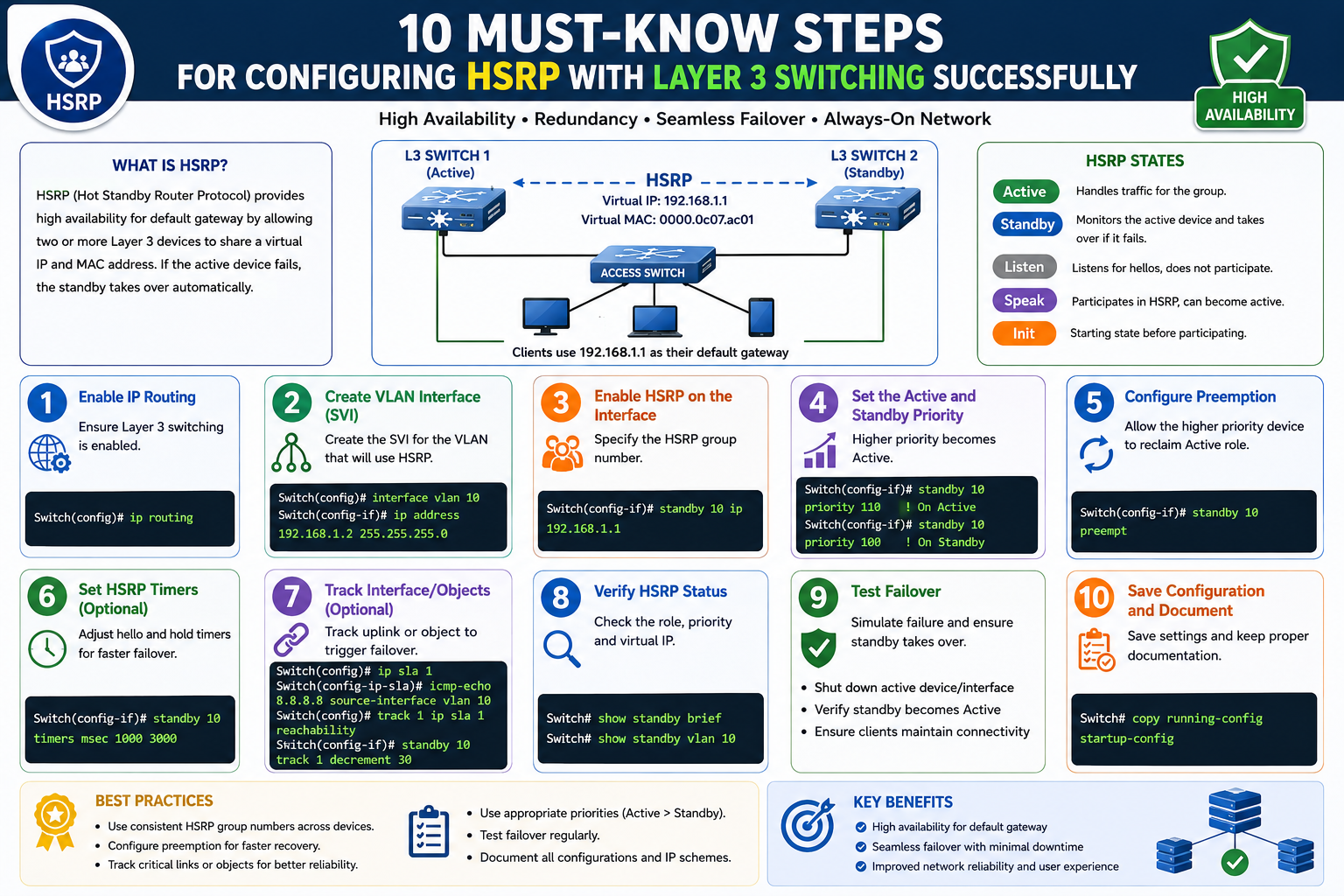
Hot Standby Router Protocol is a first-hop redundancy protocol used in Cisco-based networks to ensure continuous gateway availability for end devices. In Layer 3 switching environments, it plays a critical role in maintaining uninterrupted connectivity when a primary gateway fails. Instead of relying on a single router or switch interface as the default gateway, HSRP introduces a virtual gateway that is shared across multiple devices. This virtual gateway hides physical device dependency from hosts and provides a seamless failover mechanism.
In traditional network designs, a single router acts as the default gateway for all devices within a subnet. This creates a single point of failure. If that router becomes unavailable due to hardware failure, software issues, or link disruption, all connected hosts lose connectivity outside the local network. HSRP eliminates this limitation by allowing multiple routers or Layer 3 switches to work together as a single logical gateway. One device actively forwards traffic, while others remain on standby, continuously monitoring the active device’s status.
This design introduces a highly resilient architecture where failover occurs automatically without requiring manual intervention or reconfiguration on end devices. The virtual gateway concept ensures that hosts always communicate with the same IP address regardless of which physical device is currently active.
How HSRP Works in Layer 3 Switching Networks
Layer 3 switching environments combine routing and switching capabilities into a single device. In such networks, HSRP is typically implemented at the distribution layer where inter-VLAN routing and gateway services are centralized. Multiple Layer 3 switches participate in an HSRP group to provide redundancy for VLAN gateways.
Each HSRP group is associated with a virtual IP address that acts as the default gateway for all hosts in a subnet. Devices within the group are configured with real IP addresses on their interfaces, but hosts are only aware of the virtual IP. One device is elected as the active router, meaning it is responsible for forwarding packets sent to the virtual IP. Another device is designated as standby, ready to take over if the active router fails. Additional devices may exist in listening mode, depending on configuration size and redundancy design.
The election of the active router is based on priority values assigned to each device. The device with the highest priority becomes active. If priorities are equal, the device with the highest IP address is selected as a tie-breaker. This deterministic process ensures predictable role assignment in the network.
Once roles are assigned, the active router periodically sends hello messages to inform other devices that it is still operational. The standby router listens to these messages and monitors the health of the active device. If hello messages stop arriving within a defined time period, the standby device assumes that the active router has failed and immediately takes over the active role.
Standby Groups and Logical Gateway Formation
HSRP standby groups are logical structures that bind multiple routers or switches together into a single redundancy domain. Each group is assigned a unique identifier, and this identifier links together the virtual IP address, virtual MAC address, and participating devices.
Within a standby group, only one device can be active at a time. This device handles all traffic destined for the virtual gateway. The remaining devices are placed in standby or listening states depending on their priority and configuration. The standby group concept allows multiple redundant systems to coexist within a network while serving different VLANs or subnet segments.
Each standby group operates independently, meaning a single physical device can participate in multiple groups with different roles. For example, one switch can be active for one VLAN while being in standby for another. This capability allows efficient load distribution across redundant devices while maintaining high availability.
The standby group structure also simplifies network design. Instead of configuring redundancy on individual hosts, all redundancy logic is handled at the router or switch level. End devices simply use a single virtual gateway without awareness of underlying redundancy mechanisms.
Virtual IP Address and Gateway Abstraction Layer
The virtual IP address is the cornerstone of HSRP functionality. It represents a logical gateway that remains consistent regardless of which physical device is currently active. All hosts in a subnet are configured with this virtual IP as their default gateway.
When a host sends traffic to an external network, it forwards packets to the virtual IP address. The active router associated with that virtual IP receives and processes the traffic. If a failover occurs, the standby router assumes the same virtual IP, allowing traffic flow to continue without interruption.
This abstraction layer eliminates dependency on physical router interfaces. Instead of binding hosts to a single device, HSRP creates a floating gateway that can move between devices as needed. This ensures uninterrupted service even in cases of hardware failure, software crashes, or network link issues.
The virtual IP also simplifies network management. Since all devices share a single gateway address, host configuration remains consistent across the entire subnet. This reduces administrative overhead and minimizes configuration errors.
Virtual MAC Address Mechanism in HSRP
Alongside the virtual IP, HSRP also uses a virtual MAC address to maintain consistency at the data link layer. This MAC address is automatically generated based on predefined Cisco organizational identifiers, HSRP version information, and standby group number.
The virtual MAC address ensures that switches and end devices can continue forwarding frames without disruption during failover events. When a new router becomes active, it assumes the same virtual MAC address as the previous active device. This prevents the need for ARP table updates on connected hosts.
Without a stable MAC address, failover events would require all connected devices to refresh their ARP caches, leading to delays and temporary connectivity loss. The virtual MAC mechanism eliminates this issue and ensures smooth transitions between active devices.
The MAC structure also provides uniqueness across multiple standby groups, allowing multiple redundant gateways to coexist within the same network without conflicts.
HSRP Priority System and Active Router Selection
The priority system is central to HSRP operation. Each device in a standby group is assigned a priority value that determines its role. The device with the highest priority becomes the active router, while the second-highest becomes the standby.
By default, all devices start with the same priority value. This means manual configuration is required to influence role selection. Network administrators typically assign higher priority values to preferred primary devices and lower values to backup devices.
Priority values can be adjusted dynamically to influence failover behavior. This allows control over which device should take over during recovery scenarios or load balancing configurations.
If priorities are identical, the device with the highest IP address is selected as the active router. This fallback mechanism ensures that an active device is always chosen even without explicit configuration.
The priority system also integrates with additional features such as interface tracking, which dynamically adjusts priority values based on interface health.
HSRP Hello and Hold Timer Mechanism
HSRP uses a timer-based system to monitor device availability. Two primary timers are involved: hello timers and hold timers.
Hello timers define how frequently the active router sends status messages to other devices in the standby group. These messages confirm that the active router is operational and capable of forwarding traffic.
Hold timers define the maximum time a standby router will wait without receiving hello messages before assuming that the active router has failed. If no hello messages are received within this interval, the standby router transitions to the active state.
The combination of these timers ensures rapid detection of failures while avoiding unnecessary failovers caused by temporary network delays.
Default timer values are designed to balance stability and responsiveness, but they can be adjusted to meet specific network performance requirements. Lower timer values result in faster failover but may increase sensitivity to transient network issues.
Integration of HSRP with Layer 3 Switching Architecture
In Layer 3 switching networks, HSRP is commonly deployed at the distribution layer to provide redundancy for multiple VLANs. Each VLAN can have its own HSRP group, allowing independent gateway redundancy for different network segments.
Layer 3 switches perform routing between VLANs while simultaneously participating in HSRP groups. This dual functionality enables efficient traffic distribution and high availability at the gateway level.
The integration of HSRP into Layer 3 switching allows networks to scale without sacrificing redundancy. Multiple switches can share routing responsibilities while maintaining seamless failover capabilities for connected devices.
This architecture is widely used in enterprise networks where uptime and performance are critical requirements.
ARP Stability and Network Continuity During Failover
One of the most important aspects of HSRP is maintaining ARP stability during failover events. Since hosts rely on ARP tables to map IP addresses to MAC addresses, any change in the MAC address can cause communication disruptions.
HSRP solves this problem by ensuring that the virtual MAC address remains constant regardless of which device is active. When a failover occurs, the new active router immediately assumes the same MAC address, allowing hosts to continue communication without updating ARP entries.
This mechanism ensures that ongoing sessions, including voice and real-time applications, remain uninterrupted during failover events. It also reduces unnecessary broadcast traffic caused by ARP re-resolution.
HSRP State Progression and Operational Lifecycle
Devices in an HSRP group transition through multiple states during operation. These states define how a device behaves within the redundancy system.
The initial state represents device startup. The learn state allows devices to discover virtual IP information. The listen state enables participation in group communication without forwarding traffic. The speak state involves active participation in election processes. The standby state indicates readiness to take over traffic forwarding. The active state represents full responsibility for forwarding packets.
These transitions ensure that all devices maintain awareness of network status and are prepared for immediate role changes when needed. The structured lifecycle enhances reliability and predictability in redundancy operations.
HSRP Interface Tracking and Dynamic Priority Adjustment in Layer 3 Switching
Interface tracking is one of the most important enhancements in Hot Standby Router Protocol because it introduces intelligence into failover decisions. In a basic HSRP setup, a router or Layer 3 switch remains active as long as it is powered on and its HSRP process is running. However, this does not guarantee that all upstream or downstream paths are healthy. A device may still be active even if one of its critical interfaces has failed, which can create a condition where traffic is technically forwarded but not successfully delivered beyond the local segment.
Interface tracking solves this limitation by monitoring specific interfaces on a router or switch and dynamically adjusting HSRP priority values based on their operational state. When a tracked interface goes down, the system automatically reduces the priority of the active device. This reduction can be configured to a specific decrement value so that failover occurs only when necessary.
For example, if the active device has a priority of 110 and a critical uplink fails, a tracking configuration may subtract 20 points from that priority. This immediately reduces the device’s priority below that of a standby router, triggering a role change. This ensures that HSRP not only responds to device failures but also reacts to partial failures such as uplink or WAN link outages.
Interface tracking is especially important in Layer 3 switching environments where multiple routed interfaces connect different VLANs and upstream networks. Without tracking, a switch could remain active even when it has lost connectivity to core networks, leading to traffic blackholing and inefficient routing behavior.
Designing Priority Values for Predictable Failover Behavior
Priority configuration in HSRP is not just a simple numerical assignment; it is a design strategy that determines how traffic flows under normal and failure conditions. Proper planning of priority values ensures predictable and stable failover behavior across redundant devices.
In a typical setup, the primary device is assigned a higher priority than all backup devices. This ensures it remains the active gateway during normal operation. Backup devices are assigned lower values so they only become active when the primary device fails or loses critical connectivity.
However, priority design becomes more complex when interface tracking is introduced. Since priority can dynamically change, administrators must ensure that decrements caused by interface failures are sufficient to trigger a failover but not so aggressive that minor issues cause unnecessary switching.
For example, if the active device has a priority of 120 and a standby device has a priority of 100, then interface tracking must reduce the active device’s priority below 100 for failover to occur. This requires careful calculation of decrement values based on network topology, link importance, and redundancy goals.
This design approach ensures stability while still allowing fast failover when necessary.
HSRP Preemption and Role Reclamation Behavior
Preemption is a critical feature in HSRP that controls whether a higher-priority device can reclaim the active role after recovering from a failure. Without preemption, once a standby device becomes active, it remains active even if the original primary device comes back online with a higher priority.
When preemption is enabled, a device continuously evaluates its priority against the current active router. If it detects that it has a higher priority, it will take over the active role automatically. This ensures that the most preferred device is always responsible for forwarding traffic.
Preemption is particularly important in environments where specific devices are designed to handle higher performance loads or have better connectivity to upstream networks. In such cases, network design requires traffic to eventually return to the optimal device after recovery.
However, preemption must be carefully controlled because it can cause instability if not properly configured. If a device is frequently rebooting or unstable, enabling preemption may cause repeated role switching, leading to network disruptions. This behavior is often referred to as “flapping,” where active and standby roles continuously change in short intervals.
To prevent this, preemption can be combined with delay timers that allow a device to stabilize before attempting to reclaim the active role.
Preempt Delay Mechanism and Network Stabilization
Preempt delay is a protective mechanism that prevents immediate role switching after a device becomes operational. When a router or switch boots up, it may take time to fully initialize routing processes, establish neighbor relationships, and synchronize network tables. If it immediately takes over as the active router during this phase, it may forward incomplete or incorrect routing information.
Preempt delay introduces a waiting period before the device is allowed to participate in active role elections. This ensures that the device is fully operational and stable before it begins forwarding traffic.
A common design approach is to set the delay based on device boot time. If a device typically takes 120 seconds to fully initialize, a delay of approximately 60 seconds can be applied. This ensures that the device only attempts to become active after half of its initialization period has passed, giving sufficient time for routing protocols to converge.
This mechanism is essential in enterprise networks where stability is more important than immediate failover. It prevents unnecessary interruptions caused by partially initialized devices attempting to take over traffic responsibilities too early.
HSRP Convergence Process and Failover Timing Behavior
Convergence in HSRP refers to the time it takes for the standby device to detect failure of the active device and assume control of the virtual gateway. This process is governed by hello and hold timers, interface tracking, and preemption settings.
When the active device fails, it stops sending hello messages. The standby device continues to listen for these messages until the hold timer expires. Once the hold timer reaches its limit, the standby device assumes that the active router is no longer available and transitions to the active state.
The speed of convergence is influenced by timer settings. Shorter hello and hold intervals result in faster failover but increase sensitivity to network instability. Longer intervals improve stability but increase downtime during actual failures.
In optimized network designs, convergence is balanced to achieve minimal downtime while avoiding false failover events. This balance is critical in environments that support real-time applications such as voice and video communication, where even small delays can impact performance.
HSRP Virtual MAC Handling During Role Transition
When a failover occurs, one of the most critical operations is the transfer of the virtual MAC address from the old active device to the new active device. This ensures continuity at the data link layer and prevents disruption in communication between hosts and the gateway.
The new active router immediately assumes responsibility for the virtual MAC address and begins responding to ARP requests and forwarding frames destined for the virtual gateway. Because end devices already have this MAC address stored in their ARP tables, they do not need to perform any updates.
This mechanism eliminates broadcast storms and reduces network overhead during failover events. It also ensures that existing sessions remain intact because packet forwarding continues using the same MAC identifier.
The seamless MAC transition is one of the key reasons HSRP is widely used in enterprise-grade redundant network designs.
HSRP Load Distribution Strategies in Layer 3 Switching
Although HSRP is primarily a redundancy protocol, it can also be used for load distribution across multiple Layer 3 switches. This is achieved by configuring multiple standby groups and assigning different devices as active for different VLANs.
For example, one switch can be configured as the active gateway for VLAN 10 while another switch is active for VLAN 20. Both devices act as a standby for each other’s VLANs. This design allows traffic load to be distributed across multiple devices while maintaining redundancy.
This approach improves resource utilization and prevents one device from becoming overloaded while others remain underutilized. It also increases overall network efficiency while preserving failover capabilities.
Load distribution using HSRP requires careful planning of VLAN segmentation, routing paths, and priority assignments to ensure consistent performance.
HSRP Interaction with Layer 3 Routing Protocols
HSRP operates at the first-hop gateway level and works alongside dynamic routing protocols operating within the network core. While HSRP determines the default gateway for hosts, routing protocols handle path selection between routers and external networks.
This separation of responsibilities allows HSRP to focus solely on gateway redundancy while routing protocols manage end-to-end path optimization. The interaction between these systems ensures that both local gateway availability and global routing efficiency are maintained.
In Layer 3 switching environments, this combination is essential for building scalable and resilient enterprise networks. HSRP ensures that hosts always have a valid gateway, while routing protocols ensure that traffic reaches its destination efficiently.
Failure Scenarios and HSRP Recovery Behavior
HSRP is designed to handle multiple failure scenarios, including device failure, interface failure, and partial network isolation. When a device fails, standby routers immediately detect the absence of hello messages and take over the active role.
In cases of partial failure, such as an uplink failure, interface tracking ensures that priority is reduced and failover is triggered even though the device itself remains operational.
When the failed device recovers, its behavior depends on the reemption configuration. If preemption is enabled, the device may reclaim the active role after stabilization. If it is disabled, the current active device continues to forward traffic until it also fails or is manually reconfigured.
This flexible recovery model allows network administrators to design failover behavior that aligns with operational requirements and stability goals.
Optimizing HSRP for Enterprise Layer 3 Switching Environments
Optimizing HSRP requires balancing redundancy, performance, and stability. Key considerations include selecting appropriate priority values, configuring interface tracking, tuning hello and hold timers, and applying preemption delays where necessary.
Layer 3 switching environments benefit from the distributed redundancy design, where multiple switches share gateway responsibilities across VLANs. This reduces single-device dependency and improves scalability.
Proper optimization ensures that failover events occur quickly without causing instability or unnecessary switching. It also ensures that network resources are efficiently utilized and that critical services remain continuously available.
Advanced HSRP Design Models for Enterprise Layer 3 Switching Architectures
Hot Standby Router Protocol in advanced Layer 3 switching environments is not limited to simple active and standby roles. In enterprise-grade networks, HSRP becomes part of a larger high-availability architecture that spans multiple distribution switches, redundant uplinks, and segmented VLAN designs. The goal is not only gateway redundancy but also predictable traffic engineering, controlled failover behavior, and optimized utilization of network infrastructure.
In advanced deployments, multiple HSRP groups are distributed across Layer 3 switches to support different VLANs and subnet domains. This allows engineers to design active-active or active-standby topologies depending on business requirements. Instead of relying on a single device to handle all gateway responsibilities, load distribution is achieved by assigning different primary roles to different switches across different VLANs.
This design approach improves resilience because failure in one device does not affect all network segments equally. It also improves efficiency by ensuring that forwarding responsibilities are shared across multiple devices rather than concentrated in a single gateway.
HSRP in Scalable Multi-Distribution Layer Environments
In large enterprise networks, multiple distribution switches are often deployed in pairs or clusters. HSRP enables these devices to act as a unified gateway system while maintaining physical independence. Each distribution switch participates in one or more standby groups depending on VLAN segmentation.
As networks scale, the number of HSRP groups increases significantly. Each group maintains its own virtual IP, virtual MAC, and priority structure. This allows fine-grained control over traffic paths and redundancy behavior.
Scalability in HSRP design depends heavily on consistent configuration practices. If priority values, timers, or tracking rules are inconsistent across groups, failover behavior may become unpredictable. Therefore, enterprise environments typically follow standardized templates for HSRP deployment across all distribution layers.
This structured approach ensures that even as network size increases, failover logic remains consistent and manageable.
Active-Active Gateway Design Using Multiple HSRP Groups
Although HSRP is inherently an active-standby protocol, it can be used to achieve an active-active forwarding model through strategic configuration of multiple groups. In this design, one Layer 3 switch acts as the active gateway for certain VLANs, while another switch handles different VLANs as active.
For example, Switch A may be active for VLANs 10, 20, and 30, while Switch B is active for VLANs 40, 50, and 60. Each switch acts as a standby for the other’s VLAN groups. This creates a balanced distribution of gateway responsibilities while maintaining redundancy.
This model improves overall bandwidth utilization and reduces the risk of overloading a single device. It also allows better alignment with physical network topology, ensuring that traffic exits the network through the most optimal path.
However, careful planning is required to ensure that failover scenarios do not unintentionally concentrate traffic on a single device during outages.
HSRP Failover Behavior in Complex Redundant Topologies
In advanced network designs, failover behavior is influenced by multiple factors beyond simple device availability. These include interface tracking conditions, routing protocol convergence, uplink redundancy, and inter-switch communication health.
When a failure occurs, HSRP evaluates both device status and interface conditions before initiating role changes. If interface tracking is enabled, a device may lose active status even if it remains operational. This ensures that only fully functional paths are used for traffic forwarding.
In multi-layer redundant topologies, failover may occur in stages. First, HSRP detects gateway failure and transitions roles. Then, routing protocols adjust upstream paths. Finally, end-to-end traffic stabilizes as the network converges.
This layered failover process ensures that redundancy is not just local but extends across the entire network architecture.
HSRP Convergence Optimization in High-Speed Networks
Convergence time is a critical factor in enterprise networks where downtime must be minimized. Optimizing HSRP convergence involves tuning hello timers, hold timers, and interface tracking thresholds.
Shorter hello intervals allow faster failure detection but increase control traffic overhead. Longer intervals reduce overhead but delay failover response. Similarly, hold timers must be carefully balanced to avoid premature failover due to temporary packet loss.
In high-speed networks, convergence optimization also involves aligning HSRP behavior with underlying routing protocols. If routing convergence is slower than HSRP failover, temporary routing inconsistencies may occur. If HSRP is slower, hosts may experience unnecessary downtime.
Therefore, convergence tuning is a coordinated process that considers both gateway redundancy and routing stability.
HSRP Troubleshooting in Layer 3 Switching Environments
Troubleshooting HSRP requires a systematic approach to identify issues in role assignment, failover behavior, and communication between devices. One of the most common issues is incorrect priority configuration, which can result in unexpected active device selection.
Another frequent issue is interface tracking misconfiguration. If tracking thresholds are too aggressive, minor link fluctuations can cause unnecessary failovers. If they are too lenient, failover may not occur when required.
Timer mismatches between devices can also lead to instability. If hello and hold timers are not synchronized across all participating devices, false failure detection may occur.
In Layer 3 switching environments, additional complexity arises from VLAN segmentation and trunking configurations. Misconfigured VLANs can prevent HSRP messages from reaching all group members, resulting in split-brain scenarios where multiple devices believe they are active simultaneously.
Effective troubleshooting involves verifying interface states, examining HSRP role assignments, and ensuring consistent configuration across all participating devices.
Split-Brain Scenarios and HSRP Stability Risks
A split-brain condition occurs when multiple devices simultaneously assume the active role within the same HSRP group. This typically happens due to a communication breakdown between devices, often caused by VLAN misconfiguration, trunk failures, or spanning tree issues.
When split-brain occurs, duplicate virtual gateways may exist in the network, leading to inconsistent routing behavior and packet loss. End devices may send traffic to different active gateways depending on MAC learning behavior, resulting in unpredictable connectivity.
Preventing split-brain scenarios requires strong Layer 2 and Layer 3 design discipline. Proper trunk configuration, consistent VLAN propagation, and reliable inter-switch connectivity are essential for maintaining HSRP integrity.
In well-designed networks, split-brain conditions are rare but must always be considered during troubleshooting and architecture planning.
HSRP Interaction with Redundant Uplink and Core Network Design
HSRP does not operate in isolation; it interacts closely with uplink redundancy and core routing design. In Layer 3 switching environments, distribution switches often connect to core routers using multiple redundant links.
When HSRP failover occurs, upstream routing must adapt to ensure traffic continues to flow correctly. If uplinks are asymmetrically designed, failover may result in suboptimal routing paths.
Interface tracking plays a crucial role in aligning HSRP behavior with uplink status. If an uplink fails, HSRP can trigger a gateway change to ensure traffic exits through a fully functional path.
This coordination between gateway redundancy and uplink redundancy is essential for maintaining end-to-end network reliability.
Real-World Enterprise Deployment Patterns for HSRP
In enterprise environments, HSRP is commonly deployed in hierarchical network architectures consisting of access, distribution, and core layers. At the distribution layer, HSRP provides gateway redundancy for all access layer switches.
Each VLAN is assigned to a specific HSRP group, and distribution switches share active and standby responsibilities. This allows traffic to be distributed across multiple devices while maintaining consistent failover behavior.
In larger environments, multiple distribution pairs may exist, each serving different geographic locations or business units. HSRP ensures that each segment maintains independent gateway redundancy while remaining part of a unified network architecture.
This modular deployment approach allows networks to scale without compromising reliability or performance.
HSRP Performance Considerations in High-Traffic Networks
Performance optimization in HSRP environments involves ensuring that failover events do not introduce noticeable latency or packet loss. This is particularly important in networks supporting real-time applications such as voice, video, and transactional systems.
Key performance considerations include minimizing convergence time, balancing load across active devices, and ensuring that interface tracking does not introduce unnecessary failover triggers.
Additionally, hardware capability plays a role in performance. Devices participating in HSRP must be capable of handling peak traffic loads during failover scenarios, where a single device may temporarily handle increased traffic volume.
Proper capacity planning ensures that failover events do not degrade network performance.
HSRP Evolution and Design Relevance in Modern Networks
Although newer redundancy protocols exist, HSRP remains widely used due to its simplicity, reliability, and tight integration with Layer 3 switching infrastructure. Its design has evolved to support more efficient failover mechanisms, improved convergence behavior, and better scalability in large networks.
Modern implementations focus on optimizing HSRP alongside other network technologies rather than replacing it. It continues to serve as a foundational protocol for first-hop redundancy in enterprise environments where stable gateway behavior is essential.
Its continued relevance is driven by its predictable behavior, ease of configuration, and compatibility with complex network architectures.
Conclusion
Hot Standby Router Protocol remains one of the most practical and widely implemented first-hop redundancy mechanisms in Layer 3 switching environments. Its primary strength lies in its ability to provide continuous gateway availability without requiring any changes on end devices. By introducing a virtual IP address and virtual MAC address shared across multiple routers or multilayer switches, HSRP removes the dependency on a single physical gateway and replaces it with a resilient, logical infrastructure layer that can survive failures transparently.
In modern enterprise networks, where uptime expectations are extremely high, HSRP continues to serve as a foundational component of high availability design. It ensures that users experience uninterrupted connectivity even when the underlying hardware or links fail. The active and standby model, combined with priority-based election, creates a predictable and controlled redundancy system that is easy to manage and scale across large infrastructures.
One of the most important aspects of HSRP is its adaptability within Layer 3 switching architectures. Distribution layer switches often handle inter-VLAN routing and act as default gateways for multiple network segments. HSRP allows these devices to operate in coordinated redundancy pairs or groups, ensuring that gateway services remain available at all times. This design significantly reduces single points of failure and improves overall network resilience.
Advanced features such as interface tracking and preemption further enhance HSRP’s effectiveness. Interface tracking allows the protocol to react not only to device failures but also to link-level failures, ensuring that traffic is always routed through the most optimal path. Preemption ensures that the preferred device can reclaim the active role once it becomes fully operational again, maintaining alignment with network design priorities. When combined with carefully tuned timers and priority values, these features allow engineers to create highly responsive and stable failover environments.
However, achieving optimal HSRP performance requires careful planning. Poorly configured priorities, inconsistent timer settings, or misaligned tracking thresholds can lead to instability or unnecessary failovers. In complex networks, even small configuration inconsistencies can result in unpredictable behavior such as split-brain conditions or routing inefficiencies. Therefore, standardized design practices and consistent implementation across all network layers are essential.
HSRP also plays a key role in supporting modern application demands. Real-time services such as voice, video, and transactional systems depend heavily on stable gateway behavior. Even minor disruptions can impact user experience. By ensuring rapid failover with minimal packet loss, HSRP helps maintain service continuity in environments where performance and reliability are critical.
As network infrastructures continue to evolve, HSRP remains relevant because of its simplicity, reliability, and deep integration with Layer 3 switching technologies. While newer redundancy mechanisms and architectural models exist, HSRP continues to be widely deployed due to its proven stability and predictable behavior in enterprise-scale environments.
Ultimately, HSRP represents more than just a redundancy protocol. It is a core building block of resilient network design. When implemented correctly, it enables seamless failover, efficient traffic management, and high availability across complex Layer 3 switching infrastructures.