VMware ESXi is designed around the principle of efficient hardware utilization, where a single physical server is expected to host multiple virtual machines simultaneously without wasting idle resources. One of the most important techniques enabling this efficiency is memory overcommitment, a strategy where the total memory assigned to virtual machines exceeds the physical memory installed on the host. This concept may initially appear risky, but it is based on the reality that virtual machines rarely consume all of their allocated memory at the same time. Instead, workloads tend to fluctuate, with periods of high and low usage distributed unevenly across systems. ESXi takes advantage of this behavior by intelligently distributing memory resources where they are needed most, ensuring that active workloads continue functioning without interruption even when physical limits are approached.
Why Virtual Machines Rarely Use Allocated Memory Fully
In most virtualized environments, administrators allocate memory to virtual machines based on peak expected demand rather than continuous usage. This means that a virtual machine might be assigned several gigabytes of RAM, but in practice, it may only actively use a portion of that allocation at any given moment. Operating systems themselves are designed to cache data in memory to improve performance, but this cached memory is often considered reclaimable if needed. Applications also tend to operate in bursts rather than constant maximum utilization. This uneven consumption pattern creates an opportunity for the hypervisor to reclaim unused or lightly used memory and redistribute it to workloads that require it more urgently. ESXi leverages this behavior to maintain high consolidation ratios without sacrificing system stability.
Internal Architecture of ESXi Memory Management Layer
The ESXi hypervisor manages memory through a layered architecture that continuously monitors usage across all running virtual machines. At the lowest level, physical memory is divided into uniform blocks called pages. These pages are assigned dynamically to virtual machines based on demand, but they are not permanently locked unless explicitly reserved. ESXi tracks active usage patterns and categorizes memory into different states, such as active, idle, shared, and reclaimable. This classification allows the hypervisor to make informed decisions when memory pressure increases. Instead of immediately restricting workloads, ESXi applies a series of optimization techniques in a defined order, beginning with the least disruptive methods. This hierarchical approach ensures that performance degradation is gradual and controlled rather than sudden.
First-Line Optimization: Transparent Page Sharing Deep Dive
The first major memory optimization technique used by ESXi is Transparent Page Sharing, commonly referred to as TPS. This mechanism is designed to eliminate redundant memory usage by identifying identical memory pages across the system. Since multiple virtual machines often run similar operating systems or applications, they frequently contain identical data structures in memory. TPS scans these memory pages and compares their contents at a granular level. When identical pages are found, ESXi consolidates them into a single shared physical page, and all virtual machines referencing those pages are redirected to this shared copy. This process significantly reduces overall memory consumption without altering the behavior of applications running inside the virtual machines.
Memory Page Structure and Deduplication Mechanics
Memory in ESXi is organized into fixed-size units known as pages, which typically represent the smallest manageable block of memory. Each virtual machine is assigned a set of these pages based on its configured memory allocation. TPS operates by hashing and comparing these pages to detect duplicates. When two or more pages contain identical data, they are merged into a single physical representation. The hypervisor then updates internal references so that all virtual machines point to the same shared page. This mechanism is completely transparent to the guest operating systems, meaning that applications continue to function without awareness of the underlying optimization. Over time, this process can lead to significant memory savings, particularly in environments where many virtual machines run identical or similar workloads.
Evolution of TPS and Modern Security Constraints
In earlier virtualization implementations, TPS was more aggressive and allowed the sharing of memory pages across all virtual machines on the same host. This cross-virtual machine deduplication provided substantial memory savings, especially in environments with homogeneous workloads. However, evolving security concerns led to changes in how this feature operates. Modern ESXi configurations limit or disable cross-virtual machine sharing by default to reduce potential risks associated with memory inference attacks. These concerns revolve around the possibility that shared memory patterns could be analyzed to infer information about other virtual machines. As a result, TPS now primarily focuses on intra-virtual machine deduplication, where memory sharing occurs within the same virtual machine boundaries, preserving isolation while still offering optimization benefits.
Inter-VM vs Intra-VM Sharing Behavior
The distinction between inter-virtual machine and intra-virtual machine memory sharing is important in understanding modern TPS behavior. Intra-VM sharing refers to deduplication that occurs within a single virtual machine, where identical memory pages inside the same guest operating system are consolidated. This type of sharing is considered safe and remains enabled in most configurations. Inter-VM sharing, on the other hand, involves deduplicating memory across different virtual machines running on the same host. While this approach can provide greater memory savings, it is now restricted due to isolation requirements. The shift toward stronger isolation reflects the increasing importance of security in virtualized infrastructure, especially in multi-tenant environments where different workloads may not share trust boundaries.
Performance Implications of Page Sharing
Transparent Page Sharing generally has minimal performance overhead because it operates in the background and does not directly interfere with active workloads. However, the process of scanning, comparing, and consolidating memory pages does consume CPU cycles at the hypervisor level. In well-balanced environments, this overhead is negligible compared to the memory savings achieved. In highly dynamic environments with frequent memory changes, the effectiveness of TPS may vary, as constantly changing memory pages are less likely to remain identical for long periods. Despite these limitations, TPS still contributes to overall system efficiency by reducing redundant memory usage and improving consolidation ratios.
Workload Patterns That Benefit from TPS
Certain types of workloads benefit more from Transparent Page Sharing than others. Environments that deploy multiple instances of the same operating system, such as standardized server templates, tend to see higher memory deduplication rates. Similarly, virtual desktop infrastructures where many users run identical desktop images can benefit significantly from shared memory pages. Application servers running similar software stacks also contribute to increased duplication opportunities. In contrast, highly diverse workloads with unique memory usage patterns across virtual machines tend to see less benefit, as fewer identical pages exist for consolidation. The effectiveness of TPS is therefore closely tied to workload uniformity within the virtualized environment.
Limitations of Page Sharing in Contemporary Environments
While Transparent Page Sharing remains a valuable optimization technique, its effectiveness has decreased in some modern environments due to evolving technology trends. Encryption technologies, memory randomization techniques, and security hardening features in operating systems reduce the likelihood of identical memory pages being created across systems. Additionally, workloads are increasingly heterogeneous, with varied application stacks running on shared infrastructure. These factors reduce the opportunities for deduplication. As a result, TPS is no longer relied upon as the primary memory optimization method but instead functions as one component within a broader set of memory management strategies implemented by ESXi.
Role of TPS in Multi-Stage Memory Reclamation
Transparent Page Sharing represents the initial stage in ESXi’s multi-layered memory reclamation system. When the host has sufficient memory available, TPS alone may be enough to maintain stability and efficiency. However, as memory pressure increases, additional techniques are introduced to reclaim further resources. These subsequent stages include more dynamic and sometimes more invasive methods that ensure continued operation even under constrained conditions. TPS plays a foundational role by reducing baseline memory consumption, which in turn delays the need for more aggressive reclamation techniques. This staged approach allows ESXi to balance performance, stability, and resource utilization in complex virtualized environments.
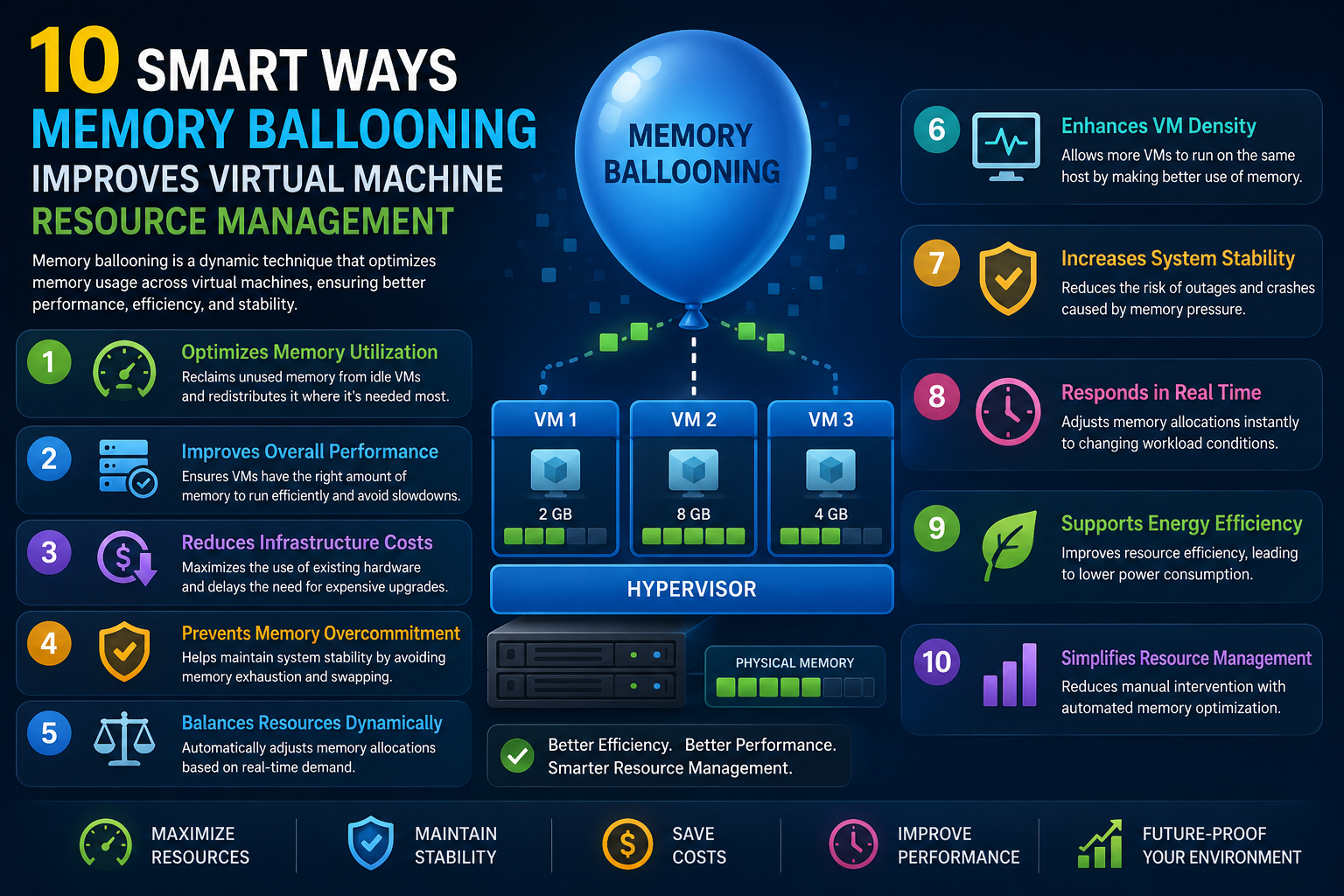
Memory Ballooning in VMware ESXi and Its Role in Dynamic Memory Reclamation
Memory ballooning is one of the most important adaptive memory management techniques used by VMware ESXi to handle situations where physical memory becomes constrained. Unlike static memory allocation methods, ballooning operates dynamically inside virtual machines, allowing the hypervisor to reclaim memory that is no longer actively required by guest workloads. This mechanism is designed to respond to memory pressure in real time, ensuring that available physical RAM is redistributed efficiently across competing virtual machines. The key advantage of ballooning is that it prioritizes reclaiming unused or lightly used memory rather than immediately affecting active application workloads. This makes it one of the most efficient early-stage memory reclamation techniques in virtualized environments.
How VMware Tools Enable Balloon Driver Functionality
Memory ballooning depends on the presence of VMware Tools installed inside each virtual machine. VMware Tools includes a specialized component known as the balloon driver, which acts as an intermediary between the guest operating system and the ESXi hypervisor. When the host experiences memory pressure, ESXi signals the balloon driver to begin inflating inside specific virtual machines. This process is not visible to applications running inside the guest operating system, but it directly influences how memory is allocated internally. The balloon driver essentially behaves like a controlled memory consumer inside the virtual machine, requesting memory pages from the guest operating system so that those pages can be reclaimed by the hypervisor and reassigned to other workloads.
Mechanics of Balloon Inflation and Memory Reclamation
When ESXi determines that additional memory is needed, it communicates with the balloon driver inside selected virtual machines. The balloon driver begins to allocate memory within the guest operating system, effectively “inflating” like a balloon. As it consumes memory pages, the guest operating system is forced to identify which memory pages are least critical or currently unused. These pages are then reclaimed by the operating system and made available to the balloon driver. Once collected, ESXi reclaims these memory pages from the virtual machine and reallocates them to other virtual machines experiencing higher demand. This process ensures that memory is not wasted on idle or unnecessary data structures while maintaining system stability.
Guest Operating System Response to Balloon Activity
When ballooning occurs inside a virtual machine, the guest operating system reacts based on its internal memory management policies. Most modern operating systems maintain a cache of frequently accessed data to improve performance, but this cached memory is typically considered low priority. During balloon inflation, the operating system is encouraged to release cached or inactive pages first. In some cases, if memory pressure becomes more intense, the operating system may begin swapping internal memory pages to its own virtual disk space. However, this is a last-resort behavior within the guest and is separate from hypervisor-level swapping. The effectiveness of ballooning depends heavily on how well the guest operating system can distinguish between critical and non-critical memory usage.
Non-Disruptive Nature of Ballooning in Normal Conditions
Under typical conditions, memory ballooning is considered a non-disruptive technique because it primarily targets unused or low-priority memory pages. Applications running inside virtual machines generally continue functioning without interruption because their actively used memory remains untouched. This allows ESXi to reclaim memory without causing noticeable performance degradation in most workloads. The hypervisor only initiates ballooning when memory demand exceeds available physical resources, making it a reactive mechanism rather than a constantly active process. When used appropriately, ballooning helps maintain system balance while avoiding more aggressive memory reclamation methods that can negatively impact performance.
Memory Ballooning as an Early Warning Indicator
One of the most important aspects of ballooning is its role as an early indicator of memory pressure within a virtualized environment. When ballooning activity becomes frequent or sustained across multiple virtual machines, it signals that the host is operating close to its physical memory limits. This condition often indicates that the environment is overcommitted beyond safe thresholds or that workloads are not properly balanced across available hosts. Monitoring balloon activity allows administrators to detect memory pressure before it escalates into more severe conditions that require compression or swapping. In this way, ballooning acts not only as a reclamation mechanism but also as a diagnostic tool for capacity planning.
Relationship Between Ballooning and Memory Overcommitment
Memory ballooning is directly tied to the concept of memory overcommitment in ESXi environments. Overcommitment allows virtual machines to be allocated more memory than physically exists on the host, relying on the assumption that not all virtual machines will fully utilize their allocation simultaneously. When this assumption no longer holds and multiple virtual machines begin demanding significant memory resources at the same time, ballooning becomes necessary. It serves as a corrective mechanism that redistributes memory based on actual usage rather than allocated capacity. Without ballooning, overcommitted environments would quickly become unstable under fluctuating workloads.
Impact of Excessive Ballooning on System Performance
While ballooning is designed to be non-disruptive, excessive or constant ballooning can lead to performance degradation. When balloon drivers are frequently active across multiple virtual machines, it indicates sustained memory pressure on the host. In such scenarios, guest operating systems may be forced to release memory that is still useful, potentially impacting application performance. Additionally, the overhead of managing frequent balloon operations can consume CPU cycles at the hypervisor level. Over time, this can reduce overall system efficiency and create performance bottlenecks. Persistent ballooning is often a sign that infrastructure scaling or workload redistribution is required.
Limitations of Ballooning in Memory-Intensive Applications
Memory ballooning is not equally effective across all types of workloads. Applications that consistently consume large amounts of active memory, such as database systems or in-memory analytics platforms, may not release significant reclaimable memory when ballooning occurs. In these cases, the guest operating system has limited flexibility to free up memory without affecting application performance. As a result, ballooning may have minimal impact in such environments, forcing ESXi to rely on more aggressive techniques like compression or swapping. This limitation highlights the importance of understanding workload characteristics when designing virtualized infrastructure.
Interaction Between Ballooning and Other Memory Techniques
Ballooning operates as part of a broader hierarchy of memory reclamation techniques within ESXi. When memory pressure increases, ESXi first attempts to reclaim memory through less intrusive methods such as page sharing. If additional memory is required, ballooning is activated. Only when these methods are insufficient does the hypervisor move on to compression and swapping. This layered approach ensures that ballooning is used as a middle-ground solution, balancing performance and efficiency. Its position in the hierarchy reflects its importance as a primary mechanism for reclaiming memory without immediate performance penalties.
CPU Overhead Associated with Balloon Operations
Although ballooning is primarily a memory management technique, it does introduce some CPU overhead at both the hypervisor and guest levels. The process of inflating and deflating balloon drivers requires coordination between ESXi and the guest operating system, which consumes processing resources. In environments with frequent balloon activity, this overhead can become more noticeable, especially on hosts with high consolidation ratios. However, under normal operating conditions, the CPU impact remains relatively low compared to the benefits of reclaiming unused memory. The efficiency of ballooning depends on maintaining a balance between memory savings and processing overhead.
Monitoring Balloon Activity in Virtualized Environments
Ballooning activity can be monitored using both hypervisor-level tools and performance metrics exposed through management interfaces. At the host level, administrators can observe memory statistics that indicate how much memory is currently being reclaimed through ballooning. Within individual virtual machines, balloon driver activity can also be tracked to understand how memory is being redistributed internally. Sustained ballooning activity across multiple hosts often indicates that the environment is approaching memory saturation. Monitoring these trends allows administrators to proactively adjust resource allocations, migrate workloads, or expand physical memory capacity before performance issues escalate.
Role of Ballooning in Resource Optimization Strategy
Memory ballooning plays a critical role in ensuring that virtualized environments operate efficiently under variable workloads. By dynamically reclaiming unused memory from virtual machines, ESXi can maintain higher consolidation ratios without immediately requiring additional physical hardware. This makes ballooning an essential component of cost-effective infrastructure design. However, its effectiveness depends on proper workload distribution and adequate physical memory provisioning. When used in conjunction with other memory management techniques, ballooning helps maintain stability, optimize resource utilization, and support scalable virtualization architectures in enterprise environments.
Memory Compression in VMware ESXi as a Secondary Reclamation Layer
Memory compression in VMware ESXi operates as a middle-stage response when earlier techniques like Transparent Page Sharing and memory ballooning are no longer sufficient to relieve memory pressure on the host. At this point, the hypervisor is under moderate to high stress, and it must begin optimizing memory at a deeper level to avoid resorting to disk-based swapping. Compression works by identifying memory pages that are not currently active but still in use and reducing their size through compression algorithms before storing them in a specialized in-memory cache. This allows ESXi to temporarily retain more data in physical memory than would otherwise be possible, effectively increasing usable memory capacity without immediately impacting disk performance.
How ESXi Identifies Compressible Memory Pages
The compression process begins when ESXi evaluates memory pages that are considered idle or less frequently accessed. These pages are not immediately discarded because they may still be needed by running applications, but they are not actively being used at that moment. The hypervisor analyzes these pages and determines whether they contain data patterns that can be efficiently compressed. Pages with repetitive or predictable structures are ideal candidates for compression. Once identified, these pages are passed through a compression algorithm that reduces their size while preserving their original state. The compressed version is then stored in a dedicated memory cache on the host.
Compressed Memory Cache and Its Function in ESXi
The compressed memory cache acts as an intermediate storage layer within the ESXi host. Instead of writing memory pages directly to disk, which would significantly degrade performance, ESXi stores compressed pages in this cache to maintain faster access times. When a virtual machine requests access to a compressed memory page, the hypervisor decompresses it on demand and restores it to its original form. This process is faster than disk retrieval but slower than direct memory access, making it a trade-off between performance and resource availability. The size of this cache is limited, meaning that ESXi must carefully manage which pages are compressed and how long they remain stored.
Performance Impact of Memory Compression on Virtual Machines
While memory compression is less disruptive than swapping, it still introduces measurable performance overhead. Compression and decompression require CPU cycles, which are consumed by the hypervisor rather than guest applications. When workloads frequently access compressed memory pages, the repeated decompression process can lead to increased latency. This is particularly noticeable in environments with high memory churn, where active workloads constantly move between compressed and uncompressed states. Although compression helps avoid more severe performance degradation caused by swapping, it is not entirely transparent to the system and should be considered a warning sign of sustained memory pressure.
Why Compression Is Preferred Over Swapping
ESXi uses memory compression as a last-resort technique before resorting to disk swapping because of the significant performance difference between memory and storage. Even with modern high-speed storage systems, disk access is orders of magnitude slower than RAM access. By keeping compressed pages in memory rather than moving them to disk, ESXi minimizes latency and maintains better responsiveness for virtual machines. Compression effectively extends the usable capacity of physical memory without incurring the full penalty of disk-based operations. However, its effectiveness is limited by CPU availability and cache size constraints.
Transition from Compression to Swapping Under Extreme Pressure
When memory compression reaches its limits, and the host continues to experience high memory demand, ESXi is forced to transition to swapping. At this stage, there are no sufficient reclaimable or compressible pages left in memory, and the system must move inactive memory pages to disk-based swap files. This transition represents a critical threshold in memory management, as it introduces significant performance degradation. Swapping is only used when all other optimization techniques have been exhausted. The shift from compression to swapping is a clear indicator that the host is under severe memory pressure and that immediate corrective action may be required.
Understanding Virtual Machine Swap Files in ESXi
Each virtual machine in ESXi is assigned a dedicated swap file at the time of power-on. This file is typically sized according to the virtual machine’s configured memory allocation. The swap file serves as a backup location for memory pages that cannot be retained in physical RAM. When swapping occurs, ESXi moves inactive memory pages from physical memory into this swap file. Because these files reside on storage devices rather than RAM, access times are significantly slower. The presence of swap activity indicates that the hypervisor is operating beyond its optimal memory capacity and relying on disk storage to maintain functionality.
Difference Between Hypervisor Swapping and Guest OS Swapping
It is important to distinguish between hypervisor-level swapping and guest operating system swapping. Hypervisor swapping is managed by ESXi and affects memory allocation at the virtual machine level, while guest OS swapping occurs inside the virtual machine itself when the operating system decides to move memory pages to its own virtual disk. Hypervisor swapping typically occurs when physical memory is exhausted, whereas guest swapping occurs when the operating system within the virtual machine experiences memory pressure. Both forms of swapping negatively impact performance, but hypervisor swapping is often more visible at the infrastructure level.
Performance Degradation Caused by Disk-Based Swapping
Swapping introduces the most significant performance impact in the ESXi memory management hierarchy. Because disk storage is much slower than physical memory, any virtual machine experiencing swap activity will exhibit noticeable latency and reduced responsiveness. Applications may experience delays, timeouts, or degraded throughput depending on the intensity of swapping. In high-performance environments, even minimal swap activity can have a disproportionate impact on user experience. This is why swapping is considered a last-resort mechanism and is avoided whenever possible through proactive memory management strategies.
Relationship Between Compression and CPU Utilization
Memory compression increases CPU utilization on the ESXi host because compression and decompression processes are computationally intensive. While this trade-off is acceptable in short bursts of memory pressure, sustained compression activity can lead to CPU contention. When CPU resources become constrained, both memory and processing performance can degrade simultaneously. This dual-resource pressure can create a cascading effect where virtual machines experience delays not only in memory access but also in general execution. Proper capacity planning is essential to ensure that CPU resources are sufficient to handle occasional compression workloads.
Role of Compression in Preventing Immediate Swelling
One of the most important functions of memory compression is its ability to delay or reduce the need for swapping. By keeping compressed pages in memory, ESXi can continue servicing workloads without immediately resorting to disk-based operations. This buffer period allows administrators time to respond to memory pressure by redistributing workloads, migrating virtual machines, or increasing physical memory capacity. In this way, compression acts as a protective layer that absorbs temporary spikes in demand and prevents sudden performance collapse.
Memory Reservation and Its Impact on ESXi Resource Allocation
Memory reservation in ESXi is a mechanism that guarantees a specific amount of physical RAM is permanently allocated to a virtual machine and cannot be reclaimed by the hypervisor, even under memory pressure. Unlike overcommitted memory configurations, where resources are shared dynamically, reserved memory is locked exclusively for a given virtual machine, ensuring predictable performance for critical workloads. This approach is commonly used for latency-sensitive applications such as databases or real-time processing systems, where memory availability must remain constant. While reservations improve stability for individual workloads, they reduce overall flexibility in the environment because reserved memory cannot be used for other virtual machines. As a result, excessive use of reservations can limit consolidation efficiency and increase the likelihood of memory pressure on other hosts.
Memory Management Interaction with Distributed Resource Scheduling
In larger virtualization environments, ESXi hosts are often grouped into clusters managed by Distributed Resource Scheduling, which dynamically balances workloads across multiple hosts. Memory management techniques such as ballooning, compression, and swapping play an important role in this ecosystem by signaling when a host is approaching resource limits. When memory pressure is detected, workload balancing mechanisms can automatically migrate virtual machines to less-utilized hosts, preventing performance degradation. This interaction ensures that memory-intensive workloads are distributed evenly across available infrastructure, reducing the likelihood of sustained compression or swapping. By combining memory reclamation techniques with automated scheduling, virtual environments maintain both performance efficiency and operational stability even during fluctuating demand.
Best Practices for Preventing Memory Contention in Virtual Environments
Preventing memory contention in ESXi environments requires a proactive approach to capacity planning and workload design. One of the most effective strategies is right-sizing virtual machines based on actual memory usage rather than peak theoretical requirements, ensuring that resources are not unnecessarily overallocated. Regular monitoring of memory metrics such as ballooning activity, compression rates, and swap usage provides early indicators of potential stress conditions. Additionally, distributing workloads across multiple hosts helps avoid localized memory saturation, reducing reliance on aggressive reclamation techniques. Maintaining adequate physical memory headroom is also critical, as it ensures that the system can absorb temporary spikes in demand without triggering compression or swapping. When these practices are consistently applied, ESXi environments remain stable, efficient, and capable of supporting high-density virtualization without performance degradation.
Indicators of Memory Stress in ESXi Environments
Sustained use of memory compression is often an indicator that the ESXi host is operating under memory stress. While occasional compression activity is normal in overcommitted environments, continuous compression suggests that the host is consistently unable to meet memory demand through earlier reclamation techniques. When compression and swapping occur together, it typically signals that the environment is overprovisioned or improperly balanced. Monitoring these indicators is essential for maintaining long-term stability and avoiding performance degradation.
Importance of Memory Balancing Across Hosts
To reduce reliance on compression and swapping, virtualized environments often use workload balancing techniques to distribute virtual machines across multiple ESXi hosts. By ensuring that no single host becomes overloaded with memory demand, administrators can minimize the likelihood of reaching compression and swapping thresholds. Tools that automate workload distribution help maintain consistent performance levels across the infrastructure. Proper balancing ensures that memory resources are used efficiently without pushing any single host into a high-pressure state.
Memory Compression as Part of ESXi’s Hierarchical Strategy
Memory compression represents a critical stage in ESXi’s hierarchical memory management system. It sits between ballooning and swapping, acting as a buffer that extends the usability of physical memory before performance degradation becomes severe. Each stage in the hierarchy is designed to be progressively more aggressive, with compression serving as the final safeguard before disk-based operations are required. This layered approach ensures that ESXi can adapt to a wide range of memory conditions while minimizing impact on running workloads.
Conclusion
VMware ESXi memory management is not built around a single technique but instead relies on a carefully structured hierarchy of mechanisms that work together to maintain stability under varying workloads. From Transparent Page Sharing to ballooning, compression, and finally swapping, each layer plays a specific role in ensuring that physical memory is used as efficiently as possible without immediately degrading system performance. This layered approach is what allows modern virtualized environments to support high levels of memory overcommitment while remaining operational under pressure.
The early stages of memory optimization, particularly page sharing and ballooning, are designed to be non-disruptive and transparent to running workloads. These mechanisms focus on reclaiming memory that is either duplicated or not actively required, allowing the system to redistribute resources without affecting application behavior. As memory demand increases, ESXi gradually shifts toward more aggressive techniques such as compression, which reduces the memory footprint while still keeping data in physical memory. This stage represents a balance between performance and resource availability, offering a temporary buffer before more costly operations are required.
When all other options are exhausted, swapping becomes the final mechanism of memory reclamation. Although highly effective in preventing system failure, it introduces significant performance penalties due to reliance on disk storage. This is why swapping is considered a last resort and is a clear indicator that the environment is under severe memory pressure. In well-designed infrastructures, swapping should be rare or nonexistent, serving only as an emergency fallback rather than a routine process.
Overall, ESXi memory management reflects a sophisticated balancing act between efficiency, performance, and stability. Each technique is designed to minimize disruption while maximizing resource utilization, ensuring that virtual machines continue operating even under constrained conditions. However, sustained reliance on compression or swapping signals the need for architectural adjustments such as better workload distribution, increased physical memory, or improved capacity planning. Understanding how these mechanisms interact is essential for maintaining a healthy, scalable, and high-performing virtual infrastructure.
Ultimately, the effectiveness of ESXi memory management depends not only on the hypervisor’s built-in mechanisms but also on how well the underlying infrastructure is designed and maintained. Proper sizing of hosts, realistic memory allocation for virtual machines, and continuous monitoring of memory behavior all contribute to a stable environment. When these factors are aligned, ESXi can operate efficiently with high consolidation ratios while keeping performance impact minimal across workloads.
It is also important to recognize that memory behavior in virtual environments is dynamic rather than static. Workloads can change rapidly due to application demand, user activity, or scheduled processing tasks, which means memory pressure can appear unexpectedly even in well-balanced systems. This is why ESXi’s layered approach is so critical, as it allows the system to respond gradually instead of abruptly reacting to spikes in demand.
In practice, maintaining healthy memory performance is less about relying on a single optimization technique and more about ensuring that all layers function together as intended. When page sharing, ballooning, compression, and swapping are working in proper sequence, the environment remains resilient even under stress. However, when the system consistently reaches the later stages of this hierarchy, it becomes a clear signal that architectural improvements are needed to restore balance and prevent long-term performance issues.