The Domain Name System, commonly known as DNS, is a fundamental building block of modern networking. It acts as a translation service that converts human-readable domain names into machine-readable IP addresses. Without DNS, users would be required to remember numerical IP addresses for every website or service they wish to access, which would make internet usage extremely inconvenient and inefficient.
Every time a user types a web address into a browser, DNS is triggered behind the scenes. The browser does not inherently understand domain names such as example.com. Instead, it needs an IP address to establish a connection with the server hosting the requested resource. DNS bridges this gap by resolving the domain name into its corresponding IP address.
DNS is designed as a distributed and hierarchical system. Rather than relying on a single central database, DNS information is spread across multiple servers worldwide. This distribution ensures scalability, redundancy, and reliability, making DNS capable of supporting billions of queries every day.
Another important aspect of DNS is its integration with dynamic network environments. In many cases, devices do not have static IP addresses. Technologies like DHCP dynamically assign IP addresses to devices, which may change over time. DNS ensures that even if the underlying IP address changes, users can still access services using the same domain name.
The Structure of DNS Hierarchy
To understand how recursive lookup works, it is essential to first understand the hierarchical structure of DNS. DNS is organized in a tree-like format with different levels, each responsible for a specific part of the domain namespace.
At the top of the hierarchy are root servers. These servers do not store detailed information about every domain but instead act as entry points. They direct queries to the appropriate top-level domain servers.
Below the root servers are the top-level domain servers. These servers manage domains such as .com, .org, .net, and country-specific extensions. They do not provide final answers but instead point to the authoritative servers responsible for specific domains.
At the bottom of the hierarchy are authoritative DNS servers. These servers hold the actual DNS records for domain names. When a query reaches an authoritative server, it can provide the definitive answer, such as the IP address associated with a domain.
This hierarchical approach ensures that DNS queries are handled efficiently and that the system can scale globally without overwhelming any single server.
Understanding DNS Queries
When a DNS query is initiated, it follows a structured path through the DNS hierarchy. The process begins with the client, which could be a computer, smartphone, or any network-enabled device. The client sends a request to a DNS resolver, which is responsible for handling the query.
If the resolver already has the answer stored in its cache, it immediately returns the result to the client. This significantly reduces the time required to resolve frequently accessed domains.
If the resolver does not have the answer, it must query other DNS servers to find the information. This is where recursive and iterative lookup methods come into play. These methods define how the query is processed and how responsibility is distributed between the client and DNS servers.
What is Recursive DNS Lookup
Recursive DNS lookup is a method in which the DNS resolver takes full responsibility for resolving a domain name query. The client sends a request and expects a complete answer. The resolver then performs all necessary steps to obtain that answer.
This approach simplifies the process for the client, as it does not need to interact with multiple DNS servers or interpret partial responses. Instead, it relies entirely on the resolver to handle the complexity of the lookup process.
Recursive lookup is widely used in everyday internet activity. Most users rely on recursive resolvers provided by their internet service providers or public DNS services. These resolvers are optimized to handle large volumes of queries efficiently.
Step-by-Step Process of Recursive Lookup
The recursive lookup process involves several stages, each contributing to the resolution of a domain name.
The process begins when the client sends a query to a DNS resolver. This query typically requests the IP address associated with a specific domain name. The resolver receives the request and begins processing it.
The first step the resolver takes is to check its local cache. If the requested information is already stored, the resolver immediately returns the result to the client. This is the fastest possible outcome and highlights the importance of caching in DNS operations.
If the resolver does not have the information, it proceeds to query a root DNS server. The root server does not provide the final answer but instead directs the resolver to the appropriate top-level domain server based on the domain extension.
The resolver then queries the top-level domain server. This server provides information about the authoritative DNS server responsible for the domain.
Next, the resolver contacts the authoritative DNS server. This server contains the actual DNS records and can provide the IP address associated with the domain name.
Once the resolver obtains the IP address, it returns the complete answer to the client. At the same time, it stores the result in its cache for future use.
The Importance of DNS Caching
Caching plays a critical role in improving the performance of recursive DNS lookup. When a resolver caches a DNS record, it stores the information for a specific period defined by the Time to Live value.
During this period, any subsequent requests for the same domain can be answered directly from the cache without repeating the entire lookup process. This reduces latency and improves the overall user experience.
Caching also helps reduce the load on DNS infrastructure. By minimizing the number of queries sent to root, TLD, and authoritative servers, caching ensures that these servers are not overwhelmed by repeated requests.
However, caching must be managed carefully. If outdated or incorrect information is stored in the cache, it can lead to resolution errors. Proper cache management and expiration policies are essential to maintain accuracy.
Advantages of Recursive DNS Lookup
Recursive DNS lookup offers several advantages that make it the preferred method for most users and applications.
One of the main benefits is simplicity. The client only needs to send a single query and wait for the response. This reduces the complexity of DNS operations on the client side.
Another advantage is efficiency. Recursive resolvers are designed to handle multiple queries and optimize performance through caching. This allows them to provide fast responses for frequently accessed domains.
Recursive lookup also improves user experience. Since the resolver handles all interactions with other DNS servers, the process is seamless and transparent to the user.
Additionally, recursive resolvers can implement advanced features such as filtering, logging, and security controls. This makes them valuable tools for managing network traffic and enforcing policies.
Limitations of Recursive DNS Lookup
Despite its advantages, recursive DNS lookup has certain limitations that must be considered.
One limitation is the increased workload on the resolver. Since the resolver is responsible for handling all aspects of the lookup process, it must be capable of managing high volumes of queries. This can require significant resources and infrastructure.
Another limitation is dependency. The client relies entirely on the resolver to provide accurate and timely responses. If the resolver experiences issues or becomes unavailable, it can disrupt DNS resolution.
Security is another concern. Recursive resolvers can be targeted by attackers attempting to exploit vulnerabilities or inject malicious data. Ensuring the security of resolvers is critical to maintaining the integrity of DNS operations.
Security Considerations in Recursive Lookup
DNS security is an important aspect of network management. Recursive lookup introduces certain risks due to its reliance on caching and external queries.
One of the most significant threats is cache poisoning. In this type of attack, an attacker attempts to insert false DNS records into a resolver’s cache. If successful, users may be redirected to malicious websites without their knowledge.
Another potential risk is interception of DNS traffic. If DNS queries are not properly secured, attackers may be able to monitor or manipulate the communication between the client and resolver.
To mitigate these risks, several security measures can be implemented. DNSSEC is a widely used technology that adds cryptographic signatures to DNS records. This ensures that responses are authentic and have not been tampered with.
Regular updates and patches are also essential. Keeping DNS software up to date helps protect against known vulnerabilities.
Network-level protections, such as firewalls and access controls, can further enhance security by restricting unauthorized access to DNS infrastructure.
Real-World Application of Recursive Lookup
Recursive DNS lookup is used in virtually every internet interaction. When a user accesses a website, sends an email, or connects to an online service, recursive lookup is typically involved in resolving domain names.
Internet service providers often operate recursive resolvers for their customers. Public DNS services also provide recursive resolution, offering additional features such as improved performance and enhanced security.
Organizations may deploy their own recursive resolvers to manage internal network traffic. This allows them to implement custom policies, monitor usage, and optimize performance.
The widespread use of recursive lookup highlights its importance in ensuring reliable and efficient communication across networks.
Troubleshooting Recursive DNS Issues
When DNS resolution fails, it can prevent access to websites and services. Troubleshooting recursive lookup issues involves identifying and resolving the underlying cause.
One of the first steps is to check network connectivity. The client must be able to communicate with the DNS resolver. Any network disruption can prevent queries from being processed.
Next, the configuration of the DNS resolver should be verified. Incorrect settings can lead to failed or incomplete lookups.
Testing the reachability of the resolver is also important. Tools can be used to confirm that the resolver is accessible and responding to queries.
Checking the DNS cache can help identify issues related to outdated or incorrect records. Clearing the cache may resolve problems caused by stale data.
It is also important to review security configurations. Firewalls or access controls may be blocking DNS traffic, preventing successful resolution.
Introduction to Iterative DNS Lookup
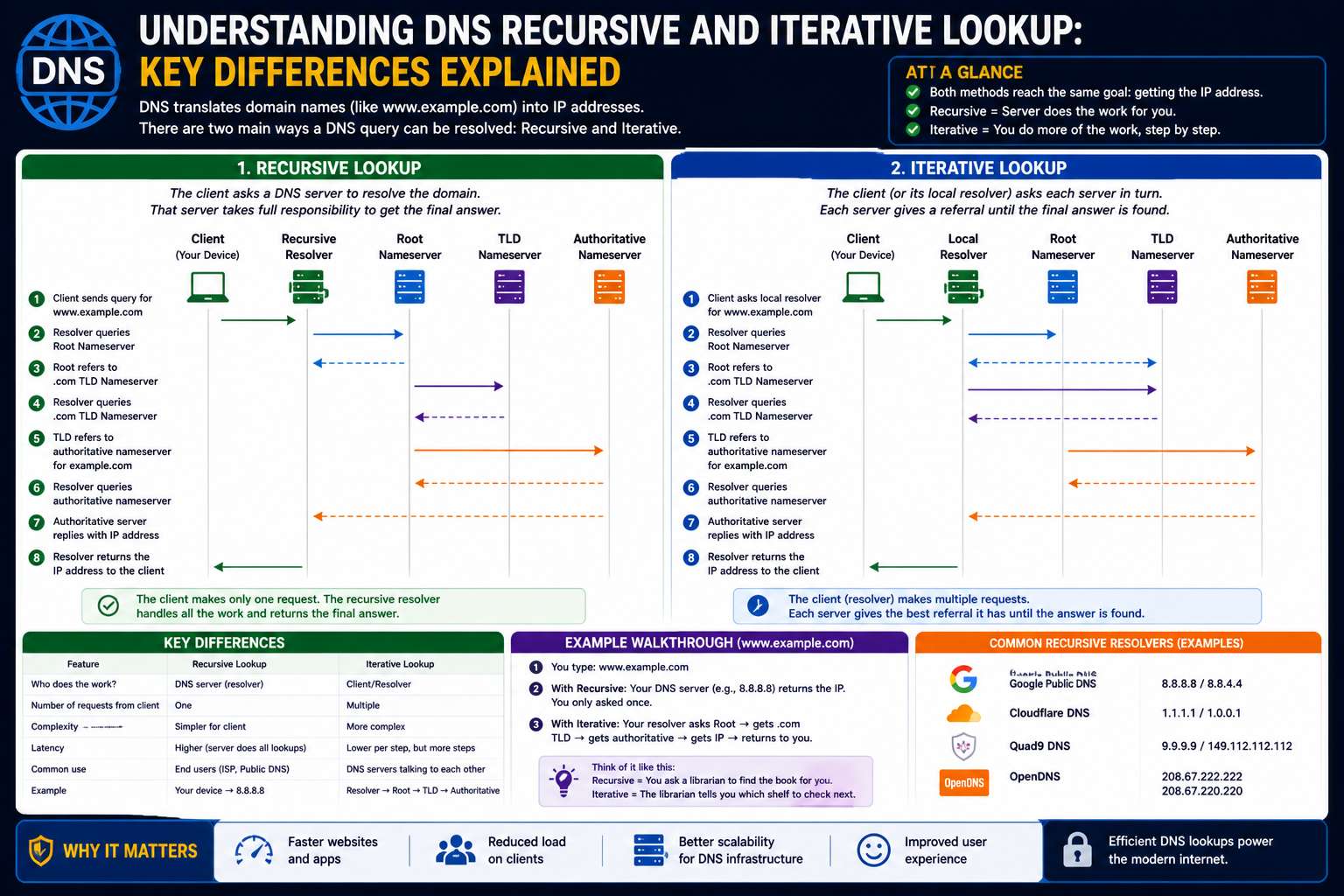
While recursive DNS lookup simplifies the resolution process by assigning full responsibility to a DNS resolver, iterative DNS lookup takes a different approach. In this method, the responsibility of resolving a domain name is shared between the client and multiple DNS servers. Instead of receiving a complete answer in one response, the client receives referrals and must continue querying other servers until it finds the final answer.
Iterative lookup is an essential part of how DNS operates internally. Even when users rely on recursive resolvers, those resolvers often use iterative queries when communicating with other DNS servers. This makes iterative lookup a foundational concept for understanding the deeper mechanics of DNS resolution.
Unlike recursive lookup, where the resolver handles everything, iterative lookup requires the client or resolver to actively participate in each step of the process. This results in a more distributed workload and provides greater transparency into how DNS queries are resolved across the hierarchy.
How Iterative Lookup Differs Conceptually
The main difference between recursive and iterative lookup lies in how queries are handled. In iterative lookup, each DNS server provides the best possible answer it can. If it does not have the requested information, it does not continue searching on behalf of the client. Instead, it returns a referral to another DNS server that is closer to the answer.
This means the client must interpret the response and decide what to do next. The process continues until the client reaches an authoritative DNS server that can provide the final answer.
This approach gives more control to the client but also increases complexity. The client must be capable of handling multiple queries and understanding DNS responses.
Step-by-Step Process of Iterative Lookup
The iterative lookup process involves several stages, each contributing to the gradual resolution of a domain name.
The process begins when the client sends a query to a DNS resolver. If the resolver does not have the answer cached, it initiates the lookup process using iterative queries.
The resolver first contacts a root DNS server. The root server does not provide the IP address but instead returns a referral to the appropriate top-level domain server.
The resolver then sends a query to the top-level domain server. This server responds with a referral to the authoritative DNS server for the domain.
Next, the resolver queries the authoritative DNS server. This server provides the final answer, which includes the IP address associated with the domain name.
If at any point a server does not have the requested information, it returns the best possible referral. The resolver continues following these referrals until it either finds the answer or exhausts all available options.
Role of Root Servers in Iterative Lookup
Root servers play a crucial role in iterative DNS lookup. They act as the starting point for resolving domain names when no cached information is available.
When a query reaches a root server, it does not attempt to resolve the domain name fully. Instead, it examines the top-level domain portion of the query and provides a referral to the corresponding TLD server.
This design ensures that root servers are not overloaded with requests. By delegating responsibility to TLD servers, they help distribute the workload across the DNS hierarchy.
Role of Top-Level Domain Servers
Top-level domain servers are responsible for managing specific domain extensions. When they receive a query, they provide information about the authoritative servers responsible for the requested domain.
These servers do not store detailed records for every domain. Instead, they act as intermediaries, guiding queries toward the appropriate authoritative servers.
This step is essential in narrowing down the search and ensuring that queries are directed efficiently through the DNS hierarchy.
Role of Authoritative DNS Servers
Authoritative DNS servers hold the actual DNS records for domain names. When a query reaches an authoritative server, it can provide the definitive answer.
In iterative lookup, reaching the authoritative server is the final step in the resolution process. Once the IP address is obtained, it is returned to the client.
Authoritative servers are critical for maintaining accurate and reliable DNS information. They ensure that domain names are correctly mapped to their corresponding IP addresses.
Iterative Resolution and Referrals
A key feature of iterative lookup is the use of referrals. Each DNS server provides guidance on where to look next if it does not have the answer.
These referrals are essential for navigating the DNS hierarchy. They allow the client to move closer to the authoritative server with each query.
The iterative nature of this process means that the client must handle multiple responses and continue querying until the resolution is complete.
This approach distributes the workload across multiple servers and avoids placing too much responsibility on any single component.
Caching in Iterative Lookup
Caching is also important in iterative lookup, although it functions slightly differently compared to recursive lookup.
When a resolver performs iterative queries, it can store the responses it receives. This includes both final answers and intermediate referrals.
Caching intermediate results can improve efficiency by reducing the number of queries required for future lookups. For example, if the resolver already knows the address of a TLD server, it can skip querying the root server.
Client-side caching may also occur, depending on the system configuration. This further enhances performance by minimizing repeated queries.
However, as with recursive lookup, caching must be managed carefully to avoid using outdated information.
Advantages of Iterative DNS Lookup
Iterative DNS lookup offers several advantages that make it valuable in certain scenarios.
One advantage is distributed workload. Since each server only provides the information it has, no single server is responsible for the entire resolution process.
This reduces the risk of bottlenecks and allows the system to scale more effectively.
Another advantage is transparency. The client has visibility into each step of the resolution process and can control how queries are handled.
Iterative lookup can also provide flexibility. Clients can choose which servers to query and how to handle referrals, allowing for customized resolution strategies.
Limitations of Iterative DNS Lookup
Despite its benefits, iterative lookup has some limitations.
One limitation is increased complexity. The client must be capable of handling multiple queries and interpreting DNS responses.
This can require more processing power and more sophisticated software compared to recursive lookup.
Another limitation is latency. Since the client must perform multiple queries, the resolution process may take longer, especially if caching is not used effectively.
Network overhead is also a consideration. Multiple queries generate additional network traffic, which can impact performance in certain environments.
Real-World Use of Iterative Lookup
Iterative lookup is commonly used by DNS resolvers when communicating with other DNS servers. Even though end users typically rely on recursive resolvers, those resolvers often use iterative queries internally.
This combination of recursive and iterative methods allows DNS to operate efficiently at scale. Recursive lookup simplifies the process for clients, while iterative lookup distributes the workload across the DNS infrastructure.
In some specialized environments, clients may perform iterative queries directly. This is more common in advanced networking scenarios or when building custom DNS solutions.
Security Considerations in Iterative Lookup
Iterative lookup also has security implications that must be considered.
One potential risk is exposure to malicious referrals. If a DNS server provides incorrect information, the client may be directed to an unauthorized or harmful server.
Another concern is interception of DNS traffic. Since multiple queries are involved, there are more opportunities for attackers to monitor or manipulate the communication.
To address these risks, security measures such as DNSSEC can be implemented. This ensures that DNS responses are verified and have not been altered.
Network protections, including encryption and access controls, can further enhance security and protect against unauthorized access.
Troubleshooting Iterative DNS Issues
When issues arise in iterative lookup, troubleshooting requires a systematic approach.
The first step is to verify network connectivity. The client must be able to reach each DNS server involved in the process.
Next, the configuration of the resolver should be checked. Incorrect settings can lead to failed queries or improper handling of referrals.
Testing individual DNS servers can help identify where the resolution process is breaking down. By querying each server manually, it is possible to pinpoint the source of the issue.
Checking cached data is also important. Stale or incorrect cache entries can cause resolution errors.
Finally, reviewing security settings can help identify any restrictions or blocks that may be interfering with DNS traffic.
Introduction to the Comparison
After understanding both recursive and iterative DNS lookup in detail, the next step is to examine how they differ and where each approach fits in real-world networking. Both methods ultimately achieve the same goal, which is resolving a domain name into an IP address, but they differ significantly in how they distribute responsibility, handle queries, and optimize performance.
These differences are not just theoretical. They directly impact how networks perform, how quickly users can access resources, and how secure DNS operations remain in modern environments. By comparing these two methods closely, it becomes easier to understand why both exist and how they complement each other.
Core Difference in Query Responsibility
The most fundamental distinction between recursive and iterative lookup lies in who is responsible for completing the DNS query.
In recursive lookup, the DNS resolver takes full responsibility for finding the final answer. The client sends a single request and waits for a complete response. The resolver handles all intermediate steps, including querying root servers, top-level domain servers, and authoritative servers.
In iterative lookup, the responsibility is shared. The client or resolver must query multiple servers step by step. Each server provides the best possible answer it can, often in the form of a referral to another server. The client then follows these referrals until the final answer is obtained.
This difference affects not only how queries are processed but also how systems are designed and optimized.
Client Involvement and Complexity
Client involvement is another major point of comparison between the two approaches.
Recursive lookup minimizes client involvement. The client only needs to send a request and wait for the result. This simplicity makes recursive lookup ideal for everyday devices such as personal computers, smartphones, and other user-facing systems.
Iterative lookup requires greater client participation. The client must handle multiple queries and interpret responses from different DNS servers. This increases complexity and requires more advanced logic within the client or resolver.
Because of this, iterative lookup is typically used behind the scenes by DNS resolvers rather than directly by end users.
Query Flow and Communication Pattern
The flow of communication differs significantly between recursive and iterative lookup.
In recursive lookup, the communication pattern is straightforward. The client communicates with a single resolver, and the resolver communicates with other DNS servers as needed. The client does not see or interact with these intermediate steps.
In iterative lookup, the communication is more distributed. The client or resolver communicates with multiple DNS servers directly. Each interaction provides new information that guides the next step in the process.
This difference in communication patterns has implications for performance, network traffic, and system design.
Performance and Latency Considerations
Performance is a critical factor in DNS resolution, and both methods have their own strengths and weaknesses in this area.
Recursive lookup is generally faster for the client. Since the resolver handles all queries and often uses caching, the client receives a response quickly. Cached results can significantly reduce lookup times, sometimes delivering answers in milliseconds.
Iterative lookup may introduce higher latency. Because multiple queries are required, the resolution process can take longer, especially if caching is not used effectively. Each step adds additional network delay.
However, iterative lookup distributes the workload across multiple servers, which can improve overall system efficiency. By preventing any single server from becoming a bottleneck, iterative lookup contributes to the scalability of DNS infrastructure.
DNS Caching Differences
Caching plays a crucial role in both recursive and iterative lookup, but it is implemented differently in each method.
In recursive lookup, caching is primarily handled by the resolver. Once a resolver obtains a DNS record, it stores it locally for a specified duration. Future queries for the same domain can be answered directly from the cache, improving speed and reducing external queries.
In iterative lookup, caching can occur at multiple levels. Resolvers may cache intermediate results such as the addresses of root and top-level domain servers. Clients may also cache responses depending on their configuration.
This layered caching approach can improve efficiency, but it also requires careful management to ensure accuracy and prevent stale data from causing issues.
Scalability and Resource Distribution
Scalability is a key consideration in large-scale networks, and both lookup methods contribute to it in different ways.
Recursive lookup centralizes the resolution process within the resolver. This can simplify client design but places a heavier burden on the resolver. To handle large volumes of queries, resolvers must be robust and capable of scaling horizontally.
Iterative lookup distributes the workload across multiple DNS servers. Each server handles a portion of the process, reducing the load on any single component. This distributed approach supports the global scalability of DNS.
In practice, DNS systems use a combination of both methods. Recursive resolvers handle client requests, while iterative queries are used internally to communicate with other DNS servers.
Reliability and Fault Tolerance
Reliability is another important factor when comparing recursive and iterative lookup.
Recursive lookup depends heavily on the availability and performance of the resolver. If the resolver fails or becomes overloaded, clients may experience delays or be unable to resolve domain names.
Iterative lookup provides greater fault tolerance. Since the process involves multiple servers, the client or resolver can potentially query alternative servers if one fails. This redundancy improves the resilience of DNS resolution.
However, iterative lookup also introduces more points of potential failure, as each step in the process relies on successful communication with different servers.
Security Implications
Security is a major concern in DNS operations, and both lookup methods have unique risks and considerations.
In recursive lookup, one of the primary threats is cache poisoning. Since resolvers store DNS records, attackers may attempt to insert false information into the cache. If successful, users can be redirected to malicious websites without their knowledge.
Recursive resolvers are also attractive targets for denial-of-service attacks. Overloading a resolver can disrupt DNS resolution for many users.
In iterative lookup, the risk shifts toward malicious referrals and interception of queries. Since the client or resolver communicates with multiple servers, there are more opportunities for attackers to interfere with the process.
To mitigate these risks, several security measures can be implemented. DNSSEC provides authentication for DNS responses, ensuring that the data has not been tampered with. Encryption techniques can protect DNS queries from interception, and network-level controls can restrict access to trusted servers.
Use Cases for Recursive Lookup
Recursive lookup is widely used in everyday internet activity. Most end users rely on recursive resolvers provided by internet service providers or public DNS services.
This method is ideal for environments where simplicity and speed are important. By offloading the complexity of DNS resolution to the resolver, it allows client devices to operate efficiently without needing advanced DNS capabilities.
Organizations also use recursive resolvers within their networks to manage internal DNS traffic. This allows them to implement policies, monitor usage, and optimize performance.
Use Cases for Iterative Lookup
Iterative lookup is primarily used within DNS infrastructure rather than by end users. DNS resolvers use iterative queries to communicate with root, top-level domain, and authoritative servers.
In this process, each server does not fully resolve the query but instead provides a referral to another server that is closer to the desired information. For example, when a resolver queries a root server, it receives a response pointing it to the appropriate top-level domain server, such as those responsible for .com or .org domains. The resolver then continues this step-by-step process until it reaches the authoritative server that holds the final IP address.
This approach is efficient because it distributes responsibility across multiple layers of the DNS hierarchy. Each server only needs to maintain knowledge about its specific zone, which reduces the load and complexity on individual systems. It also improves reliability, as failures in one part of the system do not necessarily disrupt the entire resolution process. Additionally, iterative queries allow for caching at different levels, enabling resolvers to store previously obtained referrals or answers and reuse them for future requests, thereby speeding up subsequent lookups.
Overall, iterative lookup plays a critical role in maintaining the scalability and decentralized nature of the DNS system. It ensures that the resolution process remains organized, efficient, and capable of handling the vast number of queries generated by users around the world every second.
This method is essential for the scalability and efficiency of DNS. By distributing the workload across multiple servers, it ensures that the system can handle large volumes of queries.
Iterative lookup may also be used in specialized applications where greater control over the resolution process is required. For example, network engineers and developers may use iterative queries for testing and troubleshooting DNS behavior.
Troubleshooting Differences Between the Two Methods
Troubleshooting DNS issues requires an understanding of both recursive and iterative lookup.
In recursive lookup, issues often arise from problems with the resolver. These may include misconfiguration, cache errors, or connectivity issues. Troubleshooting typically involves checking the resolver’s settings, clearing the cache, and verifying network connectivity.
In iterative lookup, issues may occur at any step in the process. Identifying the problem requires examining each stage of the query path, including root servers, top-level domain servers, and authoritative servers.
Diagnostic tools can be used to trace the resolution process and identify where it fails. This helps pinpoint the source of the issue and determine the appropriate solution.
Practical Example Comparing Both Methods
To illustrate the difference, consider a user attempting to access a website.
In recursive lookup, the user’s device sends a request to a resolver. The resolver handles all interactions with other DNS servers and returns the final IP address. The user sees only the initial request and final response.
In iterative lookup, the resolver queries a root server, then a top-level domain server, and finally an authoritative server. Each step involves a separate query and response. The resolver follows referrals until it obtains the final answer.
Although the end result is the same, the process differs significantly in terms of responsibility, communication, and complexity.
Why Both Methods Are Necessary
Recursive and iterative lookup are not competing approaches but complementary ones. Each method serves a specific purpose within the DNS ecosystem.
Recursive lookup is designed to simplify the process for the client, typically a user’s device or browser. When a recursive query is made, the DNS resolver takes on the full responsibility of finding the correct IP address. It communicates with multiple DNS servers on behalf of the client, following the chain of queries until the final answer is obtained. This reduces the complexity for the client, allowing it to send a single request and receive a complete response without needing to understand the inner workings of DNS resolution.
On the other hand, iterative lookup distributes the workload across multiple DNS servers. Instead of one resolver doing all the work, each server provides the best possible answer it has at the time, often in the form of a referral to another server that is closer to the final result. This method improves efficiency and scalability within the DNS infrastructure, as it prevents any single server from becoming overloaded with requests. It also allows different parts of the DNS hierarchy, such as root servers and authoritative servers, to operate independently while still contributing to the overall resolution process.
Together, these two approaches create a balanced and resilient system. Recursive lookup enhances user convenience and speed from the client’s perspective, while iterative lookup ensures the DNS system remains distributed, scalable, and robust under heavy global demand.
Recursive lookup provides simplicity and efficiency for clients, making it suitable for everyday use. Iterative lookup supports scalability and distribution, ensuring that DNS infrastructure can handle global demand.
By combining these methods, DNS achieves a balance between performance, reliability, and scalability. This hybrid approach allows the system to function effectively in a wide range of environments.
Conclusion
Recursive and iterative DNS lookup are two fundamental methods that work together to enable efficient domain name resolution. While they share the same goal, they differ in how they handle queries, distribute responsibility, and optimize performance.
Recursive lookup simplifies the process for clients by delegating all tasks to a DNS resolver. This approach improves user experience and leverages caching to deliver fast responses. However, it places greater responsibility on the resolver and introduces certain security challenges.
Iterative lookup, on the other hand, distributes the workload across multiple DNS servers. It provides greater control and transparency but requires more complex handling of queries. This method plays a critical role in maintaining the scalability and resilience of DNS infrastructure.
Understanding the differences between these two approaches is essential for anyone studying networking or working with DNS systems. It provides insight into how the internet functions at a fundamental level and highlights the importance of efficient and secure name resolution.
By mastering these concepts, learners and professionals can better design, manage, and troubleshoot DNS systems, ensuring reliable connectivity in an increasingly connected world.