In today’s digital environment, organizations generate enormous volumes of data every second from applications, devices, transactions, websites, and sensors. Managing this growing data using traditional storage systems has become increasingly difficult due to limitations in structure, scalability, and flexibility. To address this challenge, data lakes have emerged as a modern solution that allows organizations to store and process vast amounts of data efficiently.
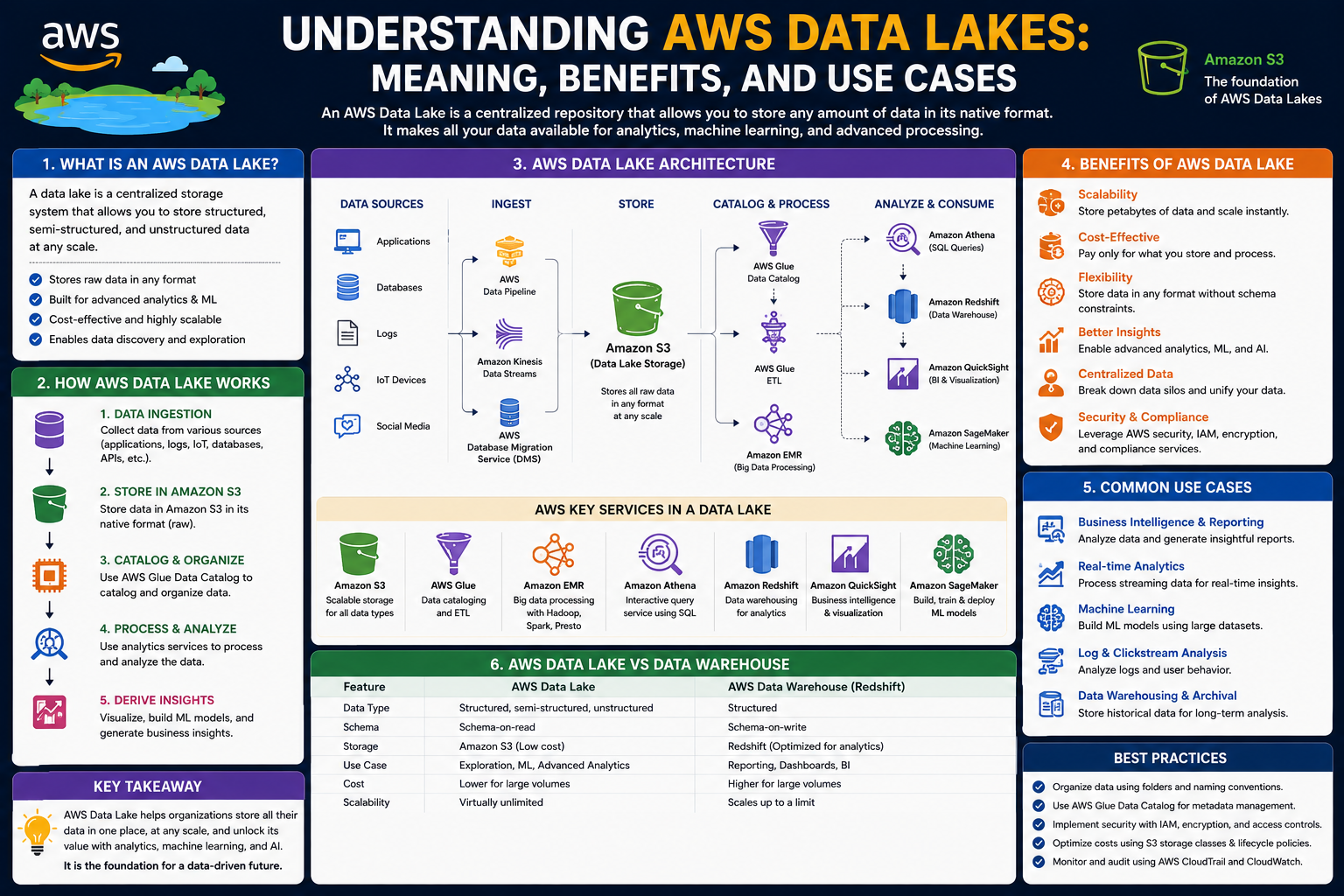
A data lake is a centralized storage system designed to hold raw data in its original format. This includes structured data such as relational tables, semi-structured data like JSON or XML, and unstructured data such as images, videos, and documents. The main advantage of this approach is that data can be stored first without transformation, and analysis can be performed later based on business or technical needs.
What Is a Data Lake
A data lake is a large-scale repository that stores raw and unprocessed data from multiple sources. Unlike traditional systems, it does not require data to follow a predefined schema before being stored. This makes it highly flexible for modern data-driven applications.
The concept can be understood through a simple analogy. Just as a natural lake collects water from different rivers and streams, a data lake collects data from various sources into one central location. Once stored, the data can be processed, transformed, and analyzed whenever required.
This approach is particularly useful for data scientists, analysts, and machine learning engineers who need access to large datasets in their original form for exploration and modeling.
Key Characteristics of Data Lakes
Data lakes are designed to handle large volumes of diverse data efficiently. One of their most important features is scalability, which allows them to grow as data increases without performance issues. They also offer flexibility by supporting multiple data formats without requiring strict structure.
Another important characteristic is cost efficiency. Since data lakes typically use cloud-based storage systems, organizations can store massive datasets at relatively low cost. They also support advanced analytics by enabling users to process raw data in different ways depending on requirements.
Data Lakes Versus Data Warehouses
Although data lakes and data warehouses are both used for storing data, they serve different purposes and follow different approaches.
A data warehouse stores structured and processed data that is ready for analysis and reporting. It is designed for predefined queries and business intelligence use cases. Data must be cleaned and organized before being stored, which makes it more rigid but highly reliable.
In contrast, a data lake stores raw data in its original form without requiring transformation beforehand. It is more flexible and supports a wider range of use cases, including machine learning, real-time analytics, and exploratory data analysis. While a warehouse is structured and controlled, a data lake is open and adaptable.
Architecture of a Cloud-Based Data Lake
A modern data lake architecture includes several components that work together to manage the flow of data from ingestion to analysis.
At the foundation is a scalable storage layer where all raw data is stored. On top of this layer, data ingestion tools collect information from multiple sources such as databases, applications, and streaming platforms.
Once data is ingested, processing tools are used to clean, transform, and organize it. A cataloging system helps manage metadata so that datasets can be easily discovered and understood. Analytics tools allow users to query the data using SQL-like languages or advanced processing frameworks. Finally, visualization tools present insights in the form of dashboards and reports.
Data Flow in a Data Lake System
The flow of data in a data lake typically follows several stages. It begins with data ingestion, where information is collected from various internal and external sources. This data is then stored in a centralized repository without modification.
After storage, data may be processed or transformed depending on the use case. This step helps prepare data for analysis. Metadata is then organized using cataloging systems, making it easier to locate and manage datasets.
Once organized, data can be analyzed using query engines or analytics platforms. The final stage involves visualization, where insights are presented through charts, dashboards, and reports that support decision-making.
Best Practices for Data Lake Design
Effective data lake design requires proper structure even though the system itself stores raw data. A common best practice is dividing storage into different layers. Raw data is stored in its original form, transformed data is processed for specific use cases, and curated data is refined for analysis. Logs and monitoring data are stored separately for auditing purposes.
Data validation should be applied during ingestion to ensure quality and consistency. Proper metadata management is also important to make datasets searchable and understandable. These practices help maintain order and usability in large-scale data environments.
Cost Optimization in Data Lakes
Managing costs is an important aspect of operating a data lake. Since large volumes of data are stored, organizations must use storage efficiently. One method is implementing tiered storage, where frequently used data is kept in high-performance storage while older data is moved to lower-cost storage.
Automated lifecycle policies help manage this process by shifting data based on usage patterns. Compression techniques and removal of redundant data also reduce storage expenses. Monitoring tools provide visibility into usage, helping organizations optimize resources effectively.
Security in Data Lake Systems
Security is critical when dealing with large and sensitive datasets. Access control mechanisms ensure that only authorized users can access specific data. Encryption protects data both during storage and transmission.
Identity and access management systems define roles and permissions, ensuring proper control over who can perform specific actions. Audit logs track all data access activities, providing transparency and helping detect unauthorized behavior. Network security measures also protect data from external threats.
Data Governance and Compliance
Data governance ensures that data is managed properly throughout its lifecycle. It involves maintaining data quality, accuracy, security, and compliance with regulations.
Organizations must follow legal requirements depending on the type of data they handle. For example, healthcare and financial industries have strict data protection laws. Governance practices include classification of data, metadata management, access control, and lifecycle tracking. These ensure that data remains reliable and compliant.
Importance of Data Lakes in Modern Technology
Data lakes play a significant role in modern IT systems. They are widely used in industries such as finance, healthcare, retail, manufacturing, and telecommunications. Organizations use them to analyze customer behavior, detect fraud, improve operations, and develop predictive models.
They are also essential for machine learning and artificial intelligence because these technologies require large volumes of raw data for training and analysis. As data continues to grow, data lakes provide a scalable solution for managing and extracting value from it.
In addition to these core benefits, data lakes also support real-time analytics, which allows organizations to respond quickly to changing conditions. For example, financial institutions can monitor transactions as they happen and immediately flag suspicious activity, reducing the risk of fraud. Similarly, retail companies can track customer interactions in real time to adjust pricing strategies, promotions, or product recommendations instantly. This level of responsiveness was difficult to achieve with traditional data storage systems.
Data lakes also help organizations break down data silos by combining information from different departments and systems into one unified platform. This improves collaboration and allows teams to work with a more complete view of the data. It also enhances data-driven decision-making across all levels of an organization.
Furthermore, data lakes support advanced technologies such as artificial intelligence, deep learning, and predictive analytics by providing large, diverse datasets required for model training. This enables organizations to build smarter systems that can forecast trends, automate processes, and improve accuracy over time.
Real-World Applications of Data Lakes
In healthcare, data lakes store patient records, medical imaging, and research data to support analysis and treatment planning. In finance, they are used to detect fraud, monitor transactions, and manage risk. Retail companies use data lakes to understand customer behavior and improve personalization. In IoT systems, data from connected devices is stored and analyzed for monitoring and predictive maintenance. These real-world applications demonstrate the versatility of data lakes across industries.
Beyond these primary use cases, data lakes also play a major role in improving operational efficiency and decision-making across organizations. In healthcare, they help researchers analyze large volumes of clinical trials and genetic data, leading to faster medical discoveries and improved treatment methods. Hospitals can also integrate real-time patient monitoring systems with data lakes to identify health risks early and provide timely intervention. In finance, data lakes support advanced analytics models that predict market trends, assess credit risk, and enhance investment strategies by analyzing historical and real-time data simultaneously. Retail businesses benefit further by combining online and offline data to create unified customer profiles, enabling highly targeted marketing campaigns and better inventory management.
In IoT environments, data lakes process continuous streams of sensor data from smart devices, enabling predictive maintenance that reduces downtime and operational costs. Additionally, industries like manufacturing use data lakes to monitor production lines and improve quality control. Government agencies also utilize them for public safety analysis, urban planning, and environmental monitoring. This broad applicability shows how data lakes have become a critical foundation for innovation and data-driven decision-making across nearly every modern industry.
Conclusion
Data lakes have become a fundamental part of modern data management strategies. They provide a flexible, scalable, and cost-effective way to store and analyze large and diverse datasets. Unlike traditional systems, they allow organizations to store raw data first and process it later based on needs.
With proper architecture, security, governance, and cost management, data lakes enable powerful analytics and machine learning capabilities. As the volume of global data continues to grow, data lakes will remain a key technology for building intelligent, data-driven systems.