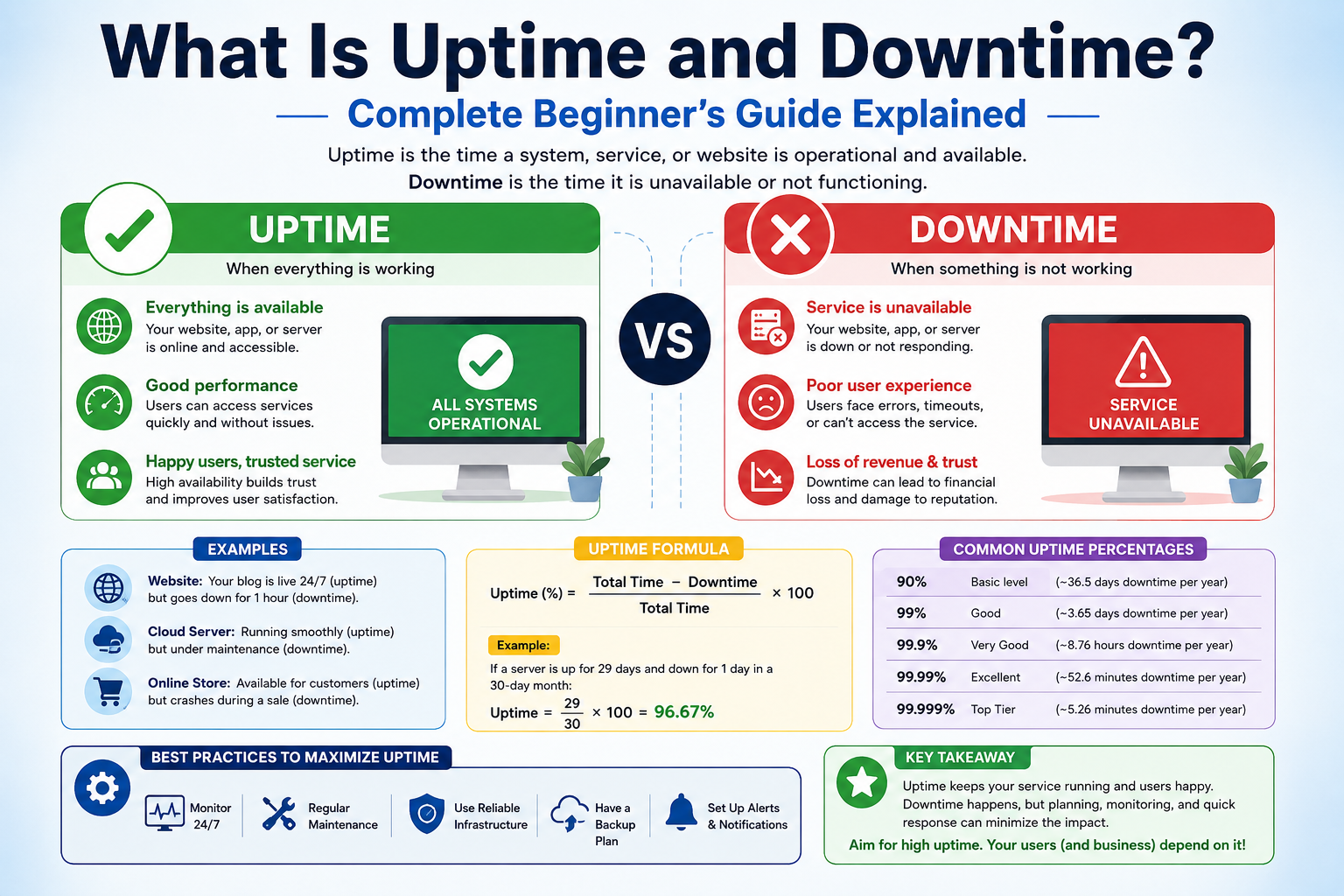
Uptime and downtime are foundational concepts used to describe how reliably a network or system operates over time. Uptime refers to the continuous period during which systems, devices, applications, or entire infrastructures remain fully functional and accessible. During uptime, every connected component performs its intended role without interruption, allowing users, services, and applications to interact seamlessly. It represents a state of normal operation where communication flows properly between devices, data is processed without delay, and services remain consistently reachable. Downtime is the opposite condition, representing any period when systems are partially or completely unavailable. This includes situations where services stop responding, devices become unreachable, or network paths fail, preventing normal communication. Downtime signals that some form of disruption has occurred within the system, whether due to internal faults, external conditions, or configuration-related issues. In modern digital environments, both states are continuously monitored because they directly reflect system health and operational stability.
The Concept of Availability in Network Environments
Availability is the broader principle that encompasses uptime and downtime, representing the overall ability of a system to remain accessible when needed. In network environments, availability is a critical requirement because most systems are designed to operate continuously without planned interruptions. High availability ensures that users can rely on systems at any time, regardless of workload, location, or time of day. This expectation has grown as digital services have become central to communication, business operations, education, and data exchange. Networks today are expected to function with minimal interruptions, even under heavy usage or unexpected conditions. Maintaining availability requires careful planning that considers system design, redundancy, monitoring, and recovery capabilities. When availability is high, systems appear stable and dependable, while low availability indicates recurring disruptions that may affect overall usability and trust in the system.
Measuring Uptime and Downtime in Operational Systems
In practical terms, uptime is measured as the total duration a system remains fully operational without interruptions. This measurement can be applied to individual devices, network segments, applications, or entire infrastructures. Downtime is measured as any interruption in this operational state, regardless of how short or long the disruption lasts. Even brief interruptions are recorded because they may indicate underlying weaknesses that need attention. These measurements are typically tracked over different time intervals, such as hourly, daily, monthly, or yearly periods, to evaluate long-term reliability. Engineers and administrators analyze these patterns to identify trends and recurring issues. A system that consistently shows high uptime is considered stable, while frequent or prolonged downtime suggests potential design flaws, resource limitations, or maintenance challenges. These metrics help organizations understand system behavior and make informed decisions about improvements.
Importance of Uptime and Downtime in Operational Stability
Uptime and downtime play a significant role in determining the stability of any networked environment. High uptime indicates that systems are functioning reliably and can support ongoing operations without interruption. This stability is essential for environments where continuous access is required, such as communication systems, data processing platforms, and service-based infrastructures. When uptime is maintained at a high level, workflows remain uninterrupted, and users can depend on consistent system performance. Downtime, however, introduces instability. Even short periods of unavailability can disrupt ongoing processes, delay operations, and create uncertainty in system behavior. In environments where timing and responsiveness are critical, downtime can have immediate operational effects. Over time, repeated downtime can also indicate structural issues within the system that need to be addressed at a deeper level.
Operational and Organizational Impact of System Availability
The impact of uptime and downtime extends beyond technical performance and influences broader operational outcomes. In environments that rely heavily on digital systems, continuous availability ensures that workflows proceed without interruption. Employees can access tools, customers can interact with services, and data can be processed without delay. When downtime occurs, these activities are interrupted, leading to delays and reduced efficiency. Even short disruptions can create cascading effects, especially in systems where processes depend on real-time data or continuous connectivity. From an organizational perspective, maintaining uptime is essential for sustaining productivity and ensuring smooth coordination between different operational units. Downtime introduces uncertainty, requiring teams to shift focus toward troubleshooting and recovery instead of regular tasks. This shift in focus can temporarily reduce overall efficiency and create additional workload for technical teams responsible for system restoration.
Technical Factors That Influence System Reliability
Several technical factors directly influence the balance between uptime and downtime in a network environment. One of the most important is hardware reliability. Physical components such as servers, routers, switches, and storage devices form the foundation of any network. Over time, these components experience wear and tear, which can lead to reduced performance or unexpected failure. As hardware ages, the likelihood of faults increases, making systems more vulnerable to downtime. Regular maintenance and timely replacement of aging components help reduce this risk and maintain consistent system behavior. The quality of hardware also plays a role, as more stable and robust components tend to perform more reliably under continuous load.
Software reliability is equally important. Networks depend on operating systems, applications, and services that must work together without conflict. When software is updated or modified, compatibility issues can arise if different components are not aligned properly. These inconsistencies may result in unexpected behavior or service interruptions. In complex environments, even small software changes can have wide-reaching effects if dependencies are not properly managed. Ensuring that software systems remain compatible and properly configured helps maintain stability and reduces the risk of downtime caused by software-related issues.
Network architecture is another critical factor. The way a network is structured determines how well it can handle failures or increased demand. Systems designed with resilience in mind often include multiple pathways for data flow, allowing communication to continue even if one path becomes unavailable. This structure helps prevent single points of failure from affecting the entire system. Without such design considerations, a single malfunctioning component can lead to widespread disruption. Proper architecture planning involves distributing resources effectively, ensuring balanced workloads, and creating alternative routes for data transmission when needed.
Human Factors and Operational Influence on System Stability
Human involvement plays a significant role in maintaining or disrupting network stability. Many downtime events are caused by configuration errors, mismanagement, or unintended changes made during system maintenance. In complex environments, small mistakes can have large consequences, especially when changes affect interconnected systems. For example, incorrect routing configurations or improperly applied updates can disrupt communication across multiple devices. Because of this, structured operational procedures are essential for reducing risk. Clear documentation, standardized workflows, and controlled change processes help minimize the likelihood of errors.
Training and experience also influence system reliability. Skilled personnel are better equipped to handle complex environments and identify potential issues before they escalate. However, even experienced individuals can make mistakes under pressure or during high-stakes operations. This is why redundancy in operational processes is often implemented, ensuring that critical changes are reviewed or verified before being applied. Peer review processes and staged implementation approaches help reduce the impact of human error and contribute to overall system stability.
Environmental and External Influences on Network Performance
External environmental conditions can also affect uptime and downtime, particularly in systems that rely on physical infrastructure. Temperature fluctuations, humidity levels, and power stability all influence the performance of hardware components. If environmental conditions are not controlled, equipment may overheat, malfunction, or shut down unexpectedly. This is especially relevant in environments where large-scale infrastructure is concentrated, such as data processing facilities or communication hubs. To reduce these risks, systems are often placed in controlled environments where temperature and power supply are regulated.
Natural events can also impact system availability. Severe weather conditions, power outages, or physical damage to infrastructure can interrupt network operations. These events are less predictable and often require external recovery efforts. While they cannot always be prevented, their impact can be reduced through redundancy, geographic distribution, and backup systems. By distributing infrastructure across multiple locations, systems can continue operating even if one location is affected by an external disruption. This approach helps maintain overall availability despite localized failures.
Network Load, Traffic Behavior, and System Performance
Traffic load is another important factor influencing uptime and downtime. Networks must handle varying levels of demand depending on user activity, time of day, and system usage patterns. When traffic increases beyond the system’s capacity, performance may degrade, resulting in delays or temporary unavailability. This condition often occurs when systems are not properly scaled to handle peak demand. Efficient traffic management helps distribute load evenly across available resources, reducing strain on individual components. Without proper management, congestion can occur, leading to performance issues that may resemble downtime even if the system remains partially operational.
Traffic behavior is often unpredictable, especially in environments that experience sudden spikes in usage. Systems must be designed to accommodate these fluctuations without compromising stability. This requires careful planning of resource allocation and continuous monitoring of system performance. When traffic is managed effectively, systems can maintain consistent performance even under high demand, contributing to improved uptime and reduced risk of disruption.
Security-Related Influences on System Availability
Security considerations also play a role in system availability. In some cases, systems may experience downtime due to protective measures taken in response to potential threats. Unauthorized access attempts, malicious activity, or system vulnerabilities can force temporary restrictions or shutdowns to prevent further damage. While these measures are necessary to protect data and infrastructure, they can also affect availability. Maintaining a balance between security and accessibility is essential for ensuring both protection and continuous operation.
Security measures such as monitoring, access control, and system updates help reduce the likelihood of disruptions caused by external threats. When security systems are properly integrated into network design, they support both protection and stability. However, if security systems are misconfigured or overly restrictive, they may unintentionally block legitimate traffic, leading to service interruptions. Careful configuration and continuous review of security policies help maintain both safety and availability.
System Dependencies and Interconnected Structures in Networks
Modern networks often consist of multiple interconnected systems that rely on each other to function. These dependencies mean that a failure in one component can affect others connected to it. When a dependent system becomes unavailable, related services may also experience disruption. This interconnected structure makes it important to understand how different components interact within the network. Identifying dependencies helps in designing systems that are more resilient to failures.
In complex environments, mapping these relationships allows for better planning and faster recovery when issues occur. By understanding which systems rely on others, engineers can prioritize recovery efforts and minimize the spread of disruption. This approach helps contain problems within specific areas instead of allowing them to affect the entire system.
Introduction to System Disruptions in Network Environments
Network downtime occurs when systems, services, or devices become partially or completely unavailable. These disruptions can vary in scale, ranging from brief interruptions affecting a small number of users to large-scale outages that impact entire infrastructures. Understanding the causes of downtime is essential for maintaining stable operations in any networked environment. While some disruptions are predictable and preventable, others occur unexpectedly due to complex interactions between hardware, software, human actions, and external conditions. In modern digital systems, even small interruptions can have noticeable effects because many services rely on continuous connectivity and real-time data exchange. This makes it important to examine the various sources of disruption in detail.
Hardware-Related Causes of Downtime
One of the most common causes of downtime is hardware failure. Physical components such as servers, routers, switches, storage devices, and power supplies are subject to wear and tear over time. As these components age, their performance gradually declines, increasing the likelihood of malfunction. Heat, electrical fluctuations, and continuous usage can also contribute to hardware degradation. When a critical component fails, it can interrupt communication paths or stop services entirely. In some cases, redundancy systems may take over automatically, but if backup systems are not available or properly configured, downtime can still occur. Hardware issues can be sudden or gradual, making monitoring and preventive maintenance essential for reducing unexpected disruptions.
Power-related hardware issues are also a significant factor. If power supplies are unstable or backup systems fail, entire sections of a network may shut down. This is especially critical in environments where continuous operation is required. Proper power distribution systems and backup mechanisms help reduce the risk of outages caused by electrical failures. Cooling systems also play an important role, as overheating can lead to hardware shutdowns or permanent damage. Without proper environmental control, hardware reliability decreases significantly, increasing the likelihood of downtime.
Software Failures and Configuration Issues
Software-related problems are another major source of downtime in network systems. Modern networks rely on multiple layers of software, including operating systems, applications, and network management tools. When these components are not properly aligned or updated, conflicts can occur. Software updates may introduce changes that are incompatible with existing systems, leading to unexpected behavior or service interruptions. Even small errors in configuration files can have wide-reaching effects, especially in large and interconnected environments.
Configuration errors are particularly common causes of downtime. A single incorrect setting can disrupt communication between devices or block access to critical services. These errors often occur during system updates, maintenance activities, or manual adjustments. Because networks are highly sensitive to configuration changes, even minor mistakes can lead to significant disruptions. Proper validation and testing procedures help reduce these risks, but they cannot eliminate them entirely. Continuous monitoring and rollback mechanisms are often used to restore systems quickly when configuration-related issues arise.
Software bugs also contribute to downtime. Despite testing and development processes, some issues only appear under real-world conditions. These bugs can cause systems to crash, slow down, or behave unpredictably. In complex environments, identifying the root cause of software-related downtime can take time because multiple components may be involved. This makes debugging and system analysis an important part of maintaining stability.
Human Error as a Major Contributor to Downtime
Human error remains one of the most frequent causes of network disruptions. Even in well-designed systems, mistakes made during operation or maintenance can lead to unexpected downtime. These errors may include incorrect configuration changes, accidental deletion of critical files, or improper execution of commands. In environments with complex infrastructure, the impact of a small mistake can spread quickly across multiple systems.
Operational pressure can increase the likelihood of human error. In fast-paced environments, administrators may need to perform tasks quickly, increasing the chance of oversight. Miscommunication between team members can also result in conflicting changes being applied to the system. Because human actions are inherently variable, it is not possible to eliminate this risk completely. However, structured processes such as approval workflows, documentation standards, and controlled access help reduce the frequency and impact of such errors.
Training and experience also influence how often human error occurs. Less experienced personnel may be more prone to mistakes, while experienced professionals are generally more familiar with system behavior. However, even experienced individuals can make errors under stress or during complex operations. This is why many organizations rely on multiple layers of verification before applying critical changes to network systems.
Network Design Limitations and Architectural Weaknesses
The structure of a network plays a major role in determining its resilience to downtime. Poorly designed networks are more likely to experience widespread disruptions when a single component fails. A lack of redundancy is one of the most common design weaknesses. When systems do not have backup paths or alternative resources, any failure can directly impact availability. In contrast, well-designed networks include multiple routes for data flow, allowing systems to continue functioning even when one path becomes unavailable.
Another design-related issue is bottlenecking. When too much traffic flows through a single point in the network, that point can become overloaded, leading to delays or service interruptions. This often occurs in systems that have not been properly scaled to handle increased demand. As usage grows, infrastructure must be expanded accordingly to maintain performance. Without proper scaling, systems become more vulnerable to downtime during peak usage periods.
Single points of failure are also a major concern in network design. These occur when a critical component has no backup or alternative. If that component fails, the entire system may become unavailable. Identifying and eliminating single points of failure is an essential part of designing resilient networks. This often involves distributing resources and implementing redundancy across multiple layers of the system.
Environmental Disruptions and Physical Infrastructure Risks
External environmental conditions can significantly affect network availability. Physical infrastructure such as data centers and communication facilities depends on stable environmental conditions to operate effectively. Temperature fluctuations can cause overheating, while humidity can damage sensitive equipment. If environmental controls fail, hardware may shut down or become damaged, leading to downtime.
Natural events also pose a risk to network infrastructure. Severe weather conditions, flooding, earthquakes, and storms can physically damage equipment or disrupt power and connectivity. These events are often unpredictable and may affect large regions simultaneously. To reduce the impact of environmental disruptions, systems are often distributed across multiple geographic locations. This allows operations to continue even if one location is affected.
Power grid instability is another environmental factor that can lead to downtime. If power supply becomes inconsistent or is interrupted, network systems may shut down unexpectedly. Backup power systems such as generators and battery units help reduce this risk, but they are not always sufficient for long-term outages. Ensuring stable power supply is a key part of maintaining continuous system availability.
Traffic Overload and Network Congestion Issues
High levels of network traffic can also lead to downtime or performance degradation. When systems are required to handle more requests than they were designed for, resources become strained. This can result in slower response times, dropped connections, or temporary unavailability. Traffic overload often occurs during peak usage periods or unexpected spikes in demand.
Network congestion is a related issue where data packets experience delays due to limited available bandwidth. When too many devices attempt to communicate simultaneously, the network becomes saturated. This can affect performance even if the system remains technically operational. In extreme cases, congestion can escalate into full downtime if critical services are unable to function properly.
Proper capacity planning helps reduce the risk of traffic-related issues. By estimating expected usage and designing systems accordingly, networks can better handle fluctuations in demand. Load distribution techniques also help ensure that no single component becomes overwhelmed.
Security Threats and Their Impact on Availability
Security-related incidents can also cause downtime in network environments. Malicious activities such as denial-of-service attacks can overwhelm systems and make them unavailable to legitimate users. In other cases, security vulnerabilities may force administrators to temporarily shut down systems to prevent further damage. These protective measures, while necessary, can result in service interruptions.
Unauthorized access attempts may also lead to downtime if systems need to be isolated or repaired. In some situations, compromised systems must be taken offline for investigation and recovery. Security updates and patches may require temporary service interruptions as well, especially if they involve critical system components.
Balancing security and availability is a key challenge in network management. Strong security practices help protect systems from external threats, but they must be implemented carefully to avoid unnecessary disruptions. Continuous monitoring and proactive defense mechanisms help reduce the likelihood of security-related downtime.
Dependency Failures in Interconnected Systems
Modern networks are highly interconnected, meaning that many systems depend on each other to function. When one system fails, others that rely on it may also become unavailable. This chain reaction can amplify the impact of a single issue, leading to broader downtime across the network. Dependency failures are particularly challenging because they may not be immediately visible, making it harder to identify the root cause.
Understanding system dependencies is essential for reducing the impact of such failures. By mapping relationships between different components, engineers can identify critical points within the network. This allows for better planning and faster recovery when issues arise. In some cases, isolating dependencies or creating alternative pathways can help prevent cascading failures.
Complex dependencies also make troubleshooting more difficult. When multiple systems are involved, identifying the original source of a problem requires careful analysis. Monitoring tools and system logs are often used to trace the sequence of events leading to downtime. This helps in restoring functionality and preventing similar issues in the future.
Understanding the Goal of High Availability in Networks
High availability refers to the ability of a network or system to remain operational and accessible for extended periods with minimal interruptions. The primary goal of network management is to maximize uptime while reducing downtime as much as possible. In modern environments, systems are expected to operate continuously, supporting communication, data processing, and application services without interruption. Achieving this level of reliability requires a combination of planning, design, monitoring, and maintenance. High availability is not the result of a single solution but rather a combination of strategies that work together to ensure stability. These strategies must address hardware reliability, software stability, environmental control, and operational procedures in a coordinated manner.
Role of Redundancy in Maintaining System Availability
Redundancy is one of the most important principles used to reduce downtime and improve system reliability. It involves creating backup components or systems that can take over when primary components fail. In a network environment, redundancy can be applied to hardware, software, power systems, and communication paths. For example, multiple servers can be used to provide the same service so that if one server fails, another can continue handling requests without interruption. Similarly, redundant network paths ensure that data can still flow even if one connection becomes unavailable.
Redundancy is not limited to physical components. It also applies to data storage and system processes. Multiple copies of critical data can be maintained in different locations to prevent data loss during failures. This approach ensures continuity even in unexpected situations. While redundancy increases system reliability, it also requires careful planning because managing duplicate systems adds complexity. Proper synchronization and coordination between redundant components are essential to ensure smooth operation when failover occurs.
Importance of Load Distribution in Network Stability
Load distribution plays a key role in maintaining consistent system performance and preventing downtime caused by overload. In a network environment, traffic is often distributed across multiple servers or devices to ensure that no single component becomes overwhelmed. When traffic is evenly distributed, systems can handle higher volumes of requests without performance degradation.
Load distribution mechanisms continuously monitor system usage and adjust traffic flow based on current conditions. When one component experiences high demand, traffic is redirected to other available components. This helps maintain balance across the system and reduces the risk of congestion. Without load distribution, systems are more likely to experience bottlenecks, which can lead to delays or temporary unavailability.
Effective load distribution also improves scalability. As demand increases, additional resources can be added to the system without disrupting existing operations. This allows networks to grow while maintaining stable performance levels. In dynamic environments where usage patterns change frequently, load distribution is essential for maintaining reliability.
System Monitoring and Performance Tracking
Continuous monitoring is a critical part of maintaining uptime and reducing downtime. Monitoring systems collect real-time data about network performance, including traffic levels, response times, resource usage, and error rates. This information helps administrators understand how the system is behaving under different conditions.
Monitoring tools allow early detection of potential issues before they escalate into major disruptions. For example, if a server begins to show signs of overload, alerts can be generated to notify administrators. This enables proactive action, such as redistributing traffic or increasing resources. Without monitoring, problems may go unnoticed until they result in downtime.
Performance tracking also helps establish baseline behavior for systems. By understanding normal operating conditions, deviations can be identified more easily. This makes troubleshooting more efficient and reduces the time required to diagnose issues. Over time, performance data can also be used to identify trends and improve system design.
Preventive Maintenance and System Upkeep
Preventive maintenance involves regularly checking and updating system components to reduce the likelihood of failure. This includes updating software, replacing aging hardware, cleaning physical equipment, and verifying system configurations. Regular maintenance helps ensure that systems remain in good working condition and reduces the risk of unexpected downtime.
Software updates are an important part of maintenance. They often include bug fixes, security improvements, and performance enhancements. However, updates must be applied carefully to avoid introducing new issues. Testing updates in controlled environments before deployment helps reduce risks.
Hardware maintenance is equally important. Components such as cooling systems, power supplies, and storage devices must be regularly inspected to ensure proper functioning. Over time, physical components degrade, and replacing them before failure helps maintain system stability. Preventive maintenance reduces the likelihood of sudden failures and extends the lifespan of network infrastructure.
Disaster Recovery Planning and System Restoration
Disaster recovery planning focuses on restoring system functionality after a major disruption. This includes events such as hardware failure, software corruption, security incidents, or environmental damage. A well-prepared recovery plan outlines the steps required to restore systems quickly and efficiently.
Recovery strategies often include backup systems and data replication. By maintaining copies of critical data in separate locations, systems can be restored even if the primary environment is unavailable. Recovery procedures also define roles and responsibilities, ensuring that each team member knows what actions to take during an outage.
The speed of recovery is an important factor in minimizing downtime. Systems are often designed with recovery time objectives that define how quickly services should be restored after a failure. Faster recovery reduces the overall impact of downtime and helps maintain operational continuity. Regular testing of recovery plans ensures that procedures remain effective and up to date.
Business Continuity and Operational Resilience
Business continuity focuses on maintaining essential operations during and after disruptions. While disaster recovery deals with restoring systems, business continuity ensures that critical functions can continue even when systems are partially affected. This may involve using alternative systems, manual processes, or temporary solutions to maintain operations.
Operational resilience is closely related to business continuity. It refers to the ability of a system or organization to adapt to changing conditions and continue functioning despite disruptions. Resilient systems are designed to absorb failures and recover quickly without significant impact on users. This requires flexible design, redundancy, and strong coordination between different components.
In network environments, business continuity planning ensures that essential services remain available even during outages. This reduces the impact of downtime and helps maintain user confidence. It also supports long-term stability by ensuring that critical operations are not completely dependent on a single system or location.
Security Integration for Stable Network Operations
Security plays a direct role in maintaining system availability. Secure systems are less likely to experience disruptions caused by unauthorized access or malicious activity. Security measures such as access control, encryption, and intrusion detection help protect systems from external threats.
However, security must be carefully integrated into system design. Overly restrictive security measures can unintentionally block legitimate access, leading to service interruptions. Balancing protection and accessibility is essential for maintaining both safety and uptime. Regular updates and monitoring help ensure that security systems remain effective without interfering with normal operations.
Incident response procedures are also important for minimizing downtime caused by security events. When a threat is detected, quick and coordinated action helps contain the issue and restore normal operations. Well-defined response strategies reduce the time systems remain affected and limit the overall impact of security-related disruptions.
Scalability and Capacity Planning in Network Design
Scalability refers to the ability of a system to handle increasing levels of demand without performance degradation. Proper capacity planning ensures that systems can accommodate growth in traffic, users, and data volume. Without scalability, systems may become overloaded, leading to downtime or reduced performance.
Capacity planning involves analyzing current usage patterns and predicting future demand. Based on this analysis, additional resources can be allocated to support expected growth. This may include adding more servers, increasing bandwidth, or optimizing system architecture. Scalable systems are better equipped to handle sudden increases in demand without interruption.
Elastic systems that can adjust resources dynamically are particularly effective in maintaining uptime. These systems automatically allocate additional capacity when needed and reduce resources during periods of low demand. This flexibility helps maintain stable performance under varying conditions.
Continuous Improvement and System Optimization
Maintaining high uptime requires ongoing improvement and optimization of network systems. As technology evolves and usage patterns change, systems must be regularly evaluated and adjusted. Continuous improvement involves analyzing performance data, identifying weaknesses, and implementing enhancements.
Optimization efforts may include improving network routing, upgrading hardware, refining configurations, and enhancing monitoring systems. Each improvement contributes to overall system stability and reduces the likelihood of downtime. Continuous evaluation ensures that systems remain efficient and capable of handling current and future demands.
Feedback loops are also important in optimization processes. By reviewing system performance after changes are implemented, administrators can determine whether improvements were effective. This iterative approach helps refine system design over time and supports long-term reliability.
Importance of Operational Awareness and Coordination
Effective coordination between technical teams is essential for maintaining uptime. Clear communication ensures that system changes are properly managed and that potential risks are identified early. Operational awareness involves understanding how different components interact within the system and how changes in one area may affect others.
Coordination also plays a key role during incident response. When downtime occurs, multiple teams may need to work together to resolve the issue. Clear roles and responsibilities help ensure that recovery efforts are efficient and organized. Without coordination, recovery may take longer and increase the overall impact of the disruption.
Maintaining awareness of system status, dependencies, and ongoing changes helps reduce unexpected issues. This proactive approach allows teams to identify potential risks before they result in downtime, contributing to overall system stability and reliability.
Conclusion
Maintaining a stable and reliable network environment depends on understanding and managing both uptime and downtime effectively. These two conditions define the operational health of any system, reflecting how consistently services remain available and how often interruptions occur. While uptime represents continuous functionality and accessibility, downtime highlights periods where systems fail to perform as expected. The balance between these two states is what determines the overall reliability of modern network infrastructures.
Across network environments, availability has become a core requirement rather than an optional feature. As systems increasingly support critical communication, data exchange, and operational processes, even minor disruptions can have significant effects. This makes it essential to focus not only on preventing downtime but also on building systems that can recover quickly when failures occur. Reliability is achieved through a combination of design strategies, operational discipline, and continuous improvement.
One of the most important aspects of maintaining high uptime is building systems with resilience in mind. This includes implementing redundancy, distributing workloads, and ensuring that no single point of failure can disrupt the entire system. When networks are designed with backup components and alternative pathways, they are better equipped to handle unexpected issues without major interruptions. In addition, proper capacity planning ensures that systems can handle varying levels of demand without becoming overloaded.
Equally important is the role of monitoring and maintenance. Continuous observation of system performance allows early detection of potential issues before they escalate into downtime. Regular maintenance, software updates, and hardware inspections further reduce the likelihood of sudden failures. These proactive measures help maintain system health and extend the operational life of network components.
Human factors also play a significant role in system reliability. Many disruptions occur due to configuration errors or operational mistakes, making structured processes and proper training essential. Clear procedures, controlled changes, and coordinated teamwork help minimize these risks and ensure that systems remain stable during updates and maintenance activities.
Security considerations further influence uptime, as systems must be protected from threats without compromising accessibility. A well-balanced security approach ensures that protection mechanisms do not interfere with legitimate operations while still defending against malicious activity.
Ultimately, achieving consistent uptime and minimizing downtime is an ongoing process rather than a one-time effort. It requires continuous evaluation, adaptation, and improvement as technologies evolve and system demands increase. By combining strong design principles, effective monitoring, disciplined operations, and proactive maintenance, network environments can maintain high levels of availability and deliver reliable performance over time.