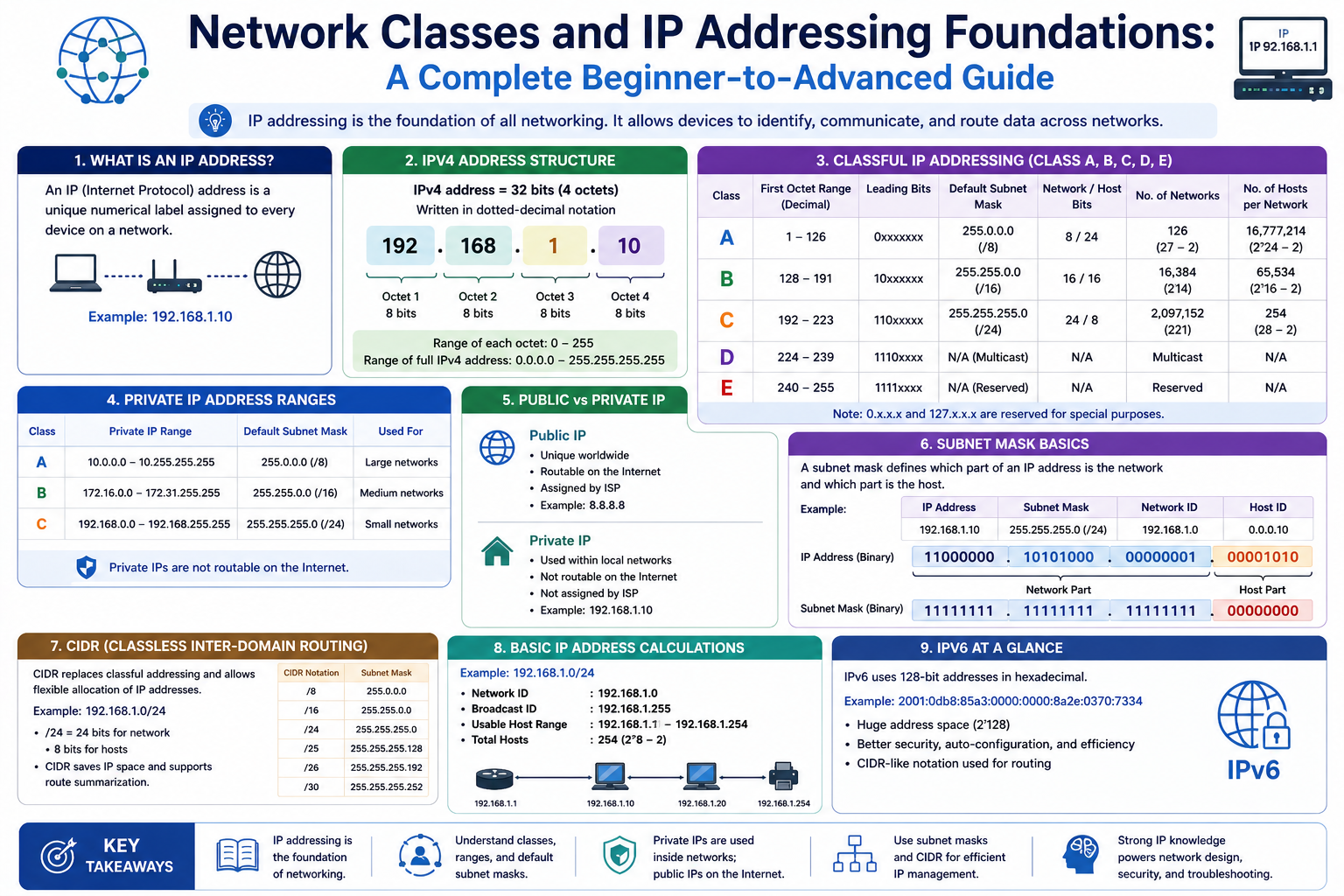
Network classes are one of the earliest methods used to organize and manage IP addresses in computer networking. They were introduced to simplify how networks are structured and how devices communicate across them. In simple terms, a network class is a category that groups IP addresses based on the size of the network and the number of devices it can support. This classification system played a major role in the early development of the internet and continues to serve as a foundational concept for understanding modern networking.
To fully understand network classes, it is necessary to first explore the concept of IP addressing, since network classes are built directly on top of how IP addresses are structured and used. Every device connected to a network must have a unique identifier, and that identifier is known as an IP address. Without IP addresses, devices would not be able to locate or communicate with each other.
The Structure of IPv4 Addresses
An IPv4 address is made up of 32 bits, which are divided into four equal parts known as octets. Each octet consists of 8 bits. For human readability, these octets are written in decimal format and separated by dots. A typical IPv4 address looks like this:
192.0.12.68
Although this format is easy for humans to read, computers process these addresses in binary form. The same IP address can be represented in binary as:
11000000.00000000.00001100.01000100
Each binary digit represents a state, often referred to as on or off. These states correspond to electrical signals within the computer system. While humans interpret these as numbers, machines interpret them as patterns of voltage that determine how data is processed and transmitted.
The use of binary allows computers to perform calculations and routing decisions efficiently. However, because binary is difficult for humans to read and remember, the dotted decimal format is used as a convenient alternative.
Why IP Addressing Matters in Networking
IP addressing is essential because it provides a structured way to identify devices on a network. Every device, whether it is a computer, smartphone, printer, or server, must have a unique IP address in order to communicate. When data is sent from one device to another, the IP address ensures that the data reaches the correct destination.
In a small network, managing IP addresses might seem straightforward. However, as networks grow larger and more complex, keeping track of all devices becomes increasingly difficult. This is where the concept of organization becomes critical. Without a proper system in place, networks would quickly become chaotic and inefficient.
Network classes were introduced as a way to bring order to this complexity. By grouping IP addresses into predefined categories, network administrators could allocate addresses more effectively and ensure that networks operated smoothly.
Introduction to Network and Host Identification
One of the most important ideas in networking is the division of an IP address into two parts: the network portion and the host portion. The network portion identifies the overall network, while the host portion identifies a specific device within that network.
This division is crucial because it allows routers and other networking devices to determine where data should be sent. When a device transmits data, the network portion of the IP address is used to route the data to the correct network, and the host portion is used to deliver it to the correct device within that network.
For example, consider an IP address like 192.168.1.10. In this case, part of the address represents the network, and the remaining part represents the individual device. The exact boundary between these two portions depends on the network class or subnet configuration.
Understanding where the network portion ends and the host portion begins is key to understanding how network classes function.
The Origin and Purpose of Network Classes
Network classes were introduced in the early 1980s as part of the original internet design. At that time, the internet was much smaller, and the number of connected devices was limited. However, even then, it was clear that a system was needed to organize IP addresses in a logical and scalable way.
The main goal of network classes was to accommodate networks of different sizes. Some organizations required large networks with thousands or even millions of devices, while others only needed small networks with a few devices. A one-size-fits-all approach would not work, so network classes were created to provide different levels of capacity.
Each class was defined by a specific range of IP addresses and a fixed boundary between the network and host portions. This made it easy to determine the structure of an IP address simply by looking at its first octet.
This system allowed for efficient routing because routers could quickly identify the network portion of an address without performing complex calculations. As a result, data could be transmitted across networks more efficiently.
How Binary Representation Supports Network Classes
Binary representation plays a critical role in how network classes function. Each IP address is made up of bits, and these bits are used to determine the class of the address as well as the division between network and host portions.
In classful networking, the first few bits of an IP address indicate its class. For example, certain bit patterns correspond to specific classes, allowing networking devices to quickly identify how the address is structured.
This approach simplifies the process of routing data because devices can make decisions based on the initial bits of the address. Instead of analyzing the entire address, they only need to examine a small portion to determine how to handle the data.
While this method was effective in the early days of networking, it eventually became limiting as networks grew in size and complexity.
Limitations of Early IP Address Allocation
Although network classes provided a structured way to organize IP addresses, they also introduced significant inefficiencies. One of the main issues was the rigid nature of the class boundaries.
Because each class had a fixed size, organizations often received more IP addresses than they actually needed. For example, a company that required a few hundred addresses might be assigned a Class B network, which could support tens of thousands of devices. This resulted in a large number of unused addresses.
At the same time, smaller classes could not accommodate organizations that needed slightly more capacity than what was available. This mismatch between supply and demand led to inefficient use of the available address space.
As the number of internet-connected devices increased, these inefficiencies became more problematic. The rapid growth of the internet highlighted the need for a more flexible system that could allocate addresses more efficiently.
Introduction to IPv6 and Its Impact
To address the limitations of IPv4, a new version of the Internet Protocol was developed, known as IPv6. Unlike IPv4, which uses 32 bits, IPv6 uses 128 bits, providing a vastly larger address space.
An IPv6 address is written in hexadecimal format and consists of eight groups of four hexadecimal digits. For example:
2001:0db8:0000:0000:0000:0000:1428:57ab
To simplify notation, consecutive groups of zeros can be compressed, resulting in:
2001:0db8::1428:57ab
The expanded address space of IPv6 allows for an enormous number of unique addresses, making it possible to support the growing number of devices connected to the internet.
While IPv6 represents the future of networking, IPv4 is still widely used today. As a result, understanding IPv4 and network classes remains essential for anyone working in networking.
The Role of Subnet Masking in Network Classes
Subnet masking is another important concept that is closely related to network classes. A subnet mask is used to define which portion of an IP address represents the network and which portion represents the host.
In classful networking, each class has a default subnet mask. This mask determines how the IP address is divided. For example, one class may use a mask that reserves the first octet for the network, while another may reserve the first three octets.
The subnet mask works by applying a binary pattern to the IP address. Bits set to one represent the network portion, while bits set to zero represent the host portion. This allows networking devices to interpret the structure of the address correctly.
Subnet masking is essential for routing because it ensures that data is directed to the correct network and device. Without subnet masks, it would be difficult to determine how to interpret IP addresses.
Why Network Classes Were Important
Network classes played a crucial role in the early development of networking. They provided a simple and effective way to organize IP addresses and made it easier to manage networks of different sizes.
By dividing addresses into classes, network administrators could allocate resources more efficiently and ensure that networks operated smoothly. The fixed structure of network classes also simplified routing, allowing data to be transmitted quickly and reliably.
Although modern networking has moved beyond classful addressing, the concepts introduced by network classes continue to influence how networks are designed and managed.
Building a Foundation for Advanced Networking Concepts
Understanding network classes is important because it provides a foundation for more advanced networking concepts. Topics such as subnetting, CIDR notation, and IP address management all build on the principles established by network classes.
For example, subnetting involves dividing a network into smaller segments, which requires an understanding of how IP addresses are structured. Similarly, CIDR notation introduces a more flexible way of defining network boundaries, but it still relies on the basic idea of separating network and host portions.
By learning about network classes, you gain insight into how networking has evolved over time. This knowledge can help you understand why certain practices are used today and how to apply them effectively.
Relevance in Modern Networking Environments
Even though classful networking is no longer the primary method used in modern systems, it is still relevant in several ways. Many legacy systems and older network configurations still rely on class-based addressing, and network professionals may encounter these systems in real-world scenarios.
In addition, networking certifications often include questions about network classes, making it important for students to understand the topic thoroughly. A solid grasp of network classes can also make it easier to troubleshoot issues and interpret network documentation.
For example, recognizing the class of an IP address can provide clues about its structure and how it should be configured. This can be especially useful when working with older systems or analyzing network traffic.
Detailed Breakdown of Network Classes and Their Structure
Network classes were designed to divide IPv4 addresses into logical categories based on the size of the network and the number of devices it could support. This system made it easier to assign IP addresses in a structured way and allowed networks to scale according to organizational needs. Each class defines how an IP address is split between the network portion and the host portion, which directly determines how many networks and devices can exist within that class.
In classful addressing, the division between network and host is fixed. This means that once an IP address belongs to a certain class, its structure is predetermined. This rigidity simplifies understanding but also introduces inefficiencies that became more noticeable as networks grew larger.
To fully understand how network classes work, it is important to explore each class individually, along with their characteristics, address ranges, and intended use cases.
Class A Networks and Their Characteristics
Class A networks were created to support extremely large organizations that require a vast number of IP addresses. In this class, only the first octet of the IP address is used to identify the network, while the remaining three octets are reserved for hosts.
This structure allows for a massive number of devices within a single network. Because three octets are dedicated to hosts, a Class A network can support millions of unique devices. This made it ideal for very large enterprises, government institutions, and major technology organizations that needed extensive network capacity.
The range of IP addresses in Class A starts from 1.0.0.0 and goes up to 126.255.255.255. The reason it does not include 0 or 127 is due to special purposes reserved for those ranges. The default subnet mask for Class A is 255.0.0.0, which indicates that the first 8 bits represent the network and the remaining 24 bits represent hosts.
One key feature of Class A networks is their simplicity. Because the network portion is limited to a single octet, identifying the network is straightforward. However, this simplicity comes at a cost. Assigning such a large block of addresses to a single organization often results in significant wastage, as most organizations do not require millions of IP addresses.
Despite this inefficiency, Class A networks played a crucial role in the early development of the internet by providing the capacity needed for large-scale operations.
Class B Networks and Their Role
Class B networks were designed as a middle ground between the extremely large Class A networks and the much smaller Class C networks. They are intended for medium-sized organizations that require a moderate number of IP addresses.
In a Class B network, the first two octets represent the network portion, while the remaining two octets are used for hosts. This structure provides a balance between the number of networks and the number of devices per network.
The address range for Class B networks extends from 128.0.0.0 to 191.255.255.255. The default subnet mask is 255.255.0.0, meaning that 16 bits are allocated for the network and 16 bits for hosts.
This configuration allows each Class B network to support thousands of devices, making it suitable for universities, large businesses, and regional organizations. At the same time, it provides a greater number of distinct networks compared to Class A.
Class B networks address some of the inefficiencies found in Class A by offering a more balanced allocation of addresses. However, they still suffer from the limitations of fixed boundaries. Organizations that require slightly more addresses than a Class C network can provide are often assigned a Class B network, even if they do not need its full capacity.
This mismatch can lead to unused address space, which becomes a significant issue as the demand for IP addresses increases.
Class C Networks and Their Practical Use
Class C networks are designed for small organizations and local networks. They are the most commonly used class in traditional networking environments because they provide a manageable number of IP addresses for typical use cases.
In a Class C network, the first three octets represent the network portion, while only the last octet is reserved for hosts. This means that each network can support a relatively small number of devices.
The address range for Class C networks is from 192.0.0.0 to 223.255.255.255. The default subnet mask is 255.255.255.0, which allocates 24 bits for the network and 8 bits for hosts.
This structure allows for up to 256 possible addresses within a single network, although some of these addresses are reserved for special purposes, such as the network address and broadcast address.
Class C networks are widely used in home networks, small offices, and local area networks. Their structure makes them easy to manage and ideal for environments where the number of devices is limited.
One of the defining characteristics of a Class C network is that all devices share the same first three octets. For example, in a network with addresses like 192.168.1.1, 192.168.1.2, and 192.168.1.3, the common prefix indicates that these devices belong to the same network.
This consistency simplifies network management and makes it easier to identify which devices are part of a particular network.
Class D Networks and Multicast Communication
Class D networks serve a completely different purpose compared to Classes A, B, and C. Instead of being used for standard device addressing, Class D is reserved for multicast communication.
Multicast allows data to be sent from one source to multiple destinations simultaneously. This is particularly useful for applications such as video streaming, online gaming, and real-time communication, where the same data needs to reach multiple recipients.
The address range for Class D networks is from 224.0.0.0 to 239.255.255.255. Unlike other classes, Class D addresses do not have a traditional network and host division. Instead, they are used to identify groups of devices that receive multicast traffic.
When a device sends data to a multicast address, all devices that are part of the corresponding multicast group receive the data. This approach reduces network congestion by minimizing the need for duplicate transmissions.
Class D networks play an important role in modern networking by enabling efficient data distribution across multiple devices.
Class E Networks and Experimental Use
Class E networks are reserved for experimental purposes and are not used in standard networking environments. These addresses range from 240.0.0.0 to 255.255.255.255.
Because they are intended for research and testing, Class E addresses are not assigned to devices in production networks. Their primary purpose is to support the development of new networking technologies and protocols.
Although Class E networks are not commonly encountered in everyday networking, they are an important part of the overall classification system.
Fixed Boundaries and Their Impact
One of the defining features of classful networking is the use of fixed boundaries between the network and host portions of an IP address. Each class has a predefined structure that determines how the address is divided.
This approach simplifies the process of identifying the network portion of an address. By examining the first octet, it is possible to determine the class and, therefore, the structure of the address.
However, these fixed boundaries also create limitations. Because the size of each class is predetermined, organizations cannot adjust the number of available addresses to match their exact needs. This often leads to inefficient use of address space.
For example, an organization that requires 500 IP addresses cannot use a Class C network, as it only supports up to 256 addresses. Instead, it must use a Class B network, which provides tens of thousands of addresses. This results in a large number of unused addresses.
As the internet expanded, this inefficiency became a major concern, leading to the development of more flexible addressing methods.
Subnetting Within Classful Networks
Subnetting is a technique used to divide a larger network into smaller, more manageable segments. Even within the constraints of classful networking, subnetting provides a way to improve efficiency and organization.
In subnetting, bits from the host portion of an IP address are borrowed to create additional network segments. This allows a single network to be divided into multiple sub-networks, each with its own range of addresses.
For example, a Class C network with a default subnet mask of 255.255.255.0 can be subdivided into smaller networks by extending the subnet mask. This creates multiple smaller networks, each capable of supporting a limited number of devices.
Subnetting offers several advantages. It improves network performance by reducing traffic within each segment, enhances security by isolating different parts of the network, and simplifies management by organizing devices into logical groups.
However, in classful networking, subnetting is still constrained by the original class boundaries. While it provides some flexibility, it does not fully address the inefficiencies associated with fixed address allocation.
Real-World Implications of Network Classes
In practical terms, network classes influenced how organizations designed and managed their networks. Large enterprises often relied on Class A networks, while medium-sized organizations used Class B, and smaller networks used Class C.
This classification system made it easier to assign addresses and plan network infrastructure. However, it also required careful consideration to ensure that resources were used effectively.
Network administrators needed to understand the limitations of each class and plan accordingly. This included determining how many devices would be connected to the network and selecting the appropriate class to meet those needs.
As networks grew and evolved, the limitations of this system became more apparent. The increasing demand for IP addresses highlighted the need for a more flexible approach.
Transition Toward More Flexible Addressing
The challenges associated with network classes eventually led to the development of new methods for managing IP addresses. These methods aimed to eliminate the inefficiencies of classful networking and provide greater flexibility.
While network classes are no longer the primary method used in modern networking, they remain an important part of networking education. Understanding how they work provides valuable insight into the evolution of networking technologies.
By studying network classes, it becomes easier to understand why newer approaches, such as CIDR and advanced subnetting techniques, were developed. These modern methods build on the concepts introduced by network classes while addressing their limitations.
Evolution Beyond Network Classes
As computer networks expanded rapidly and the number of connected devices increased, the limitations of classful addressing became more visible. The original system of dividing IP addresses into fixed classes was useful in the early days, but it struggled to keep up with modern demands. Organizations needed more flexibility in how they allocated IP addresses, and the rigid boundaries of network classes could not provide that.
The biggest issue was inefficiency. Many organizations were assigned large blocks of IP addresses that they did not fully use, while others found themselves running out of addresses. This imbalance created pressure on the available IPv4 address space and made it clear that a new approach was needed.
To address these challenges, networking engineers developed a system that removed the strict class boundaries and allowed for more precise control over how IP addresses were allocated. This new system became known as Classless Inter-Domain Routing, or CIDR.
Understanding CIDR and Its Purpose
CIDR was introduced as a replacement for classful addressing. Instead of dividing IP addresses into fixed categories, CIDR allows network administrators to define the size of a network based on actual requirements. This approach eliminates the inefficiencies associated with traditional network classes.
CIDR notation uses a format that combines an IP address with a suffix indicating how many bits are used for the network portion. For example:
192.168.1.0/24
In this notation, the number after the slash represents the number of bits allocated to the network portion of the address. In this case, 24 bits are used for the network, leaving the remaining bits for hosts.
This method provides a flexible way to define networks of different sizes. Instead of being limited to predefined classes, administrators can create networks that match their specific needs. This leads to more efficient use of IP addresses and reduces waste.
CIDR also improves routing efficiency. By allowing networks to be grouped into larger blocks, it reduces the size of routing tables and simplifies the process of directing data across networks.
How CIDR Replaces Classful Boundaries
One of the most significant changes introduced by CIDR is the removal of fixed boundaries between network and host portions. In classful networking, these boundaries were determined by the class of the IP address. With CIDR, they can be adjusted as needed.
For example, instead of being restricted to a Class C network with a fixed size, an administrator can create a network that uses fewer or more bits for the network portion. This allows for much greater flexibility in designing network structures.
This flexibility makes it possible to allocate address space more precisely. Organizations can receive exactly the number of addresses they need, rather than being forced into a category that provides too many or too few.
CIDR also enables route aggregation, which allows multiple smaller networks to be represented as a single larger network. This reduces the complexity of routing and improves overall network performance.
Introduction to Variable Length Subnet Masking
Variable Length Subnet Masking, commonly referred to as VLSM, is closely related to CIDR and plays a key role in modern networking. VLSM allows different parts of a network to use different subnet masks, providing even greater flexibility.
In traditional classful networking, all subnets within a network had to use the same subnet mask. This often led to inefficiencies, as some subnets would have more addresses than needed while others would have too few.
With VLSM, subnet sizes can be adjusted based on actual requirements. For example, a department with many devices can be assigned a larger subnet, while a smaller department can use a smaller subnet. This ensures that IP addresses are used efficiently across the entire network.
VLSM is especially useful in large organizations where different sections of the network have varying needs. By tailoring subnet sizes, administrators can optimize resource allocation and improve network performance.
The Role of Subnetting in Modern Networks
Subnetting is the process of dividing a network into smaller segments. While subnetting existed in classful networking, it became much more powerful with the introduction of CIDR and VLSM.
In modern networks, subnetting is used to improve performance, enhance security, and simplify management. By dividing a network into smaller segments, administrators can control traffic more effectively and reduce congestion.
For example, a large network can be divided into multiple subnets, each representing a different department or function. This separation helps prevent unnecessary traffic from spreading across the entire network and makes it easier to isolate and troubleshoot issues.
Subnetting also improves security by allowing administrators to implement access controls between different parts of the network. Sensitive data can be kept within specific subnets, reducing the risk of unauthorized access.
Transition from IPv4 to IPv6
As the demand for IP addresses continued to grow, it became clear that IPv4 alone would not be sufficient to support the expanding internet. This led to the development of IPv6, which provides a much larger address space.
IPv6 uses 128 bits for its addresses, compared to 32 bits in IPv4. This allows for an enormous number of unique addresses, ensuring that the supply will not run out in the foreseeable future.
An IPv6 address is written in hexadecimal format and consists of eight groups of four digits. To simplify notation, sequences of zeros can be compressed. This makes IPv6 addresses more manageable despite their length.
In addition to providing more addresses, IPv6 introduces several improvements in areas such as routing efficiency, security, and automatic configuration. These features make it better suited for modern networking environments.
Although IPv6 adoption is increasing, IPv4 is still widely used. As a result, network professionals must understand both systems and how they interact.
Why Network Classes Still Matter
Even though classful networking has largely been replaced by CIDR and modern techniques, the concept of network classes remains important. Many legacy systems and older network configurations still rely on class-based addressing.
In addition, networking education and certification exams often include questions about network classes. Understanding these concepts is essential for anyone studying networking or working in the field.
Network classes also provide a historical perspective on how networking has evolved. By studying the limitations of classful addressing, it becomes easier to appreciate the advantages of modern approaches.
Furthermore, the basic idea of dividing an IP address into network and host portions is still relevant. While the methods used to define this division have changed, the underlying concept remains the same.
Practical Applications in Networking
In real-world scenarios, understanding network classes can help with tasks such as troubleshooting, network design, and documentation. For example, recognizing the structure of an IP address can provide clues about how a network is configured.
When analyzing network traffic, identifying patterns in IP addresses can help determine whether devices belong to the same network. This information can be useful for diagnosing connectivity issues and ensuring proper configuration.
Network classes can also serve as a reference point when working with older systems. Even if a network uses modern addressing methods, legacy documentation may still include class-based information.
By having a solid understanding of network classes, administrators can bridge the gap between older and newer technologies.
The Importance of Efficient Address Allocation
Efficient use of IP addresses is a critical aspect of network management. As the number of connected devices continues to grow, it is important to ensure that address space is used effectively.
CIDR and VLSM play a key role in achieving this goal by allowing networks to be designed with precision. Instead of wasting addresses, administrators can allocate exactly what is needed.
This efficiency not only conserves address space but also improves network performance. Smaller, well-organized networks are easier to manage and less prone to congestion.
Efficient address allocation also supports scalability. As organizations grow, their networks can be expanded without requiring major restructuring.
Challenges and Considerations in Modern Networking
While modern addressing methods offer many advantages, they also introduce new challenges. Managing complex networks with multiple subnets requires careful planning and expertise.
Administrators must consider factors such as network size, traffic patterns, and security requirements when designing a network. Mistakes in subnetting or address allocation can lead to connectivity issues and inefficiencies.
In addition, the transition from IPv4 to IPv6 presents its own set of challenges. Compatibility between the two systems must be maintained, and organizations need to ensure that their infrastructure supports both protocols.
Despite these challenges, modern networking provides the tools needed to build scalable and efficient systems. By understanding both historical and current approaches, professionals can make informed decisions and create robust networks.
Conclusion
Network classes were a foundational concept in the early development of computer networking. They provided a structured way to organize IP addresses and made it possible to build networks of different sizes. However, their rigid structure led to inefficiencies that became increasingly problematic as the internet grew.
The introduction of CIDR and Variable Length Subnet Masking marked a significant shift toward more flexible and efficient address allocation. These methods removed the limitations of classful networking and allowed networks to be designed based on actual needs.
At the same time, the development of IPv6 ensured that the growing demand for IP addresses could be met. With its vast address space and improved features, IPv6 represents the future of networking.
Despite these advancements, the principles behind network classes remain relevant. They provide a foundation for understanding how IP addressing works and offer valuable insight into the evolution of networking technologies.
By learning about network classes, CIDR, subnetting, and modern addressing methods, you gain a comprehensive understanding of how networks are designed and managed. This knowledge is essential for anyone working in the field of networking or preparing for professional certifications.
In the end, networking is about connecting devices and enabling communication. From the early days of classful addressing to the advanced systems used today, the goal has always been to create efficient, reliable, and scalable networks. Understanding the journey from network classes to modern techniques helps you appreciate the complexity of this field and prepares you to contribute to its ongoing development.