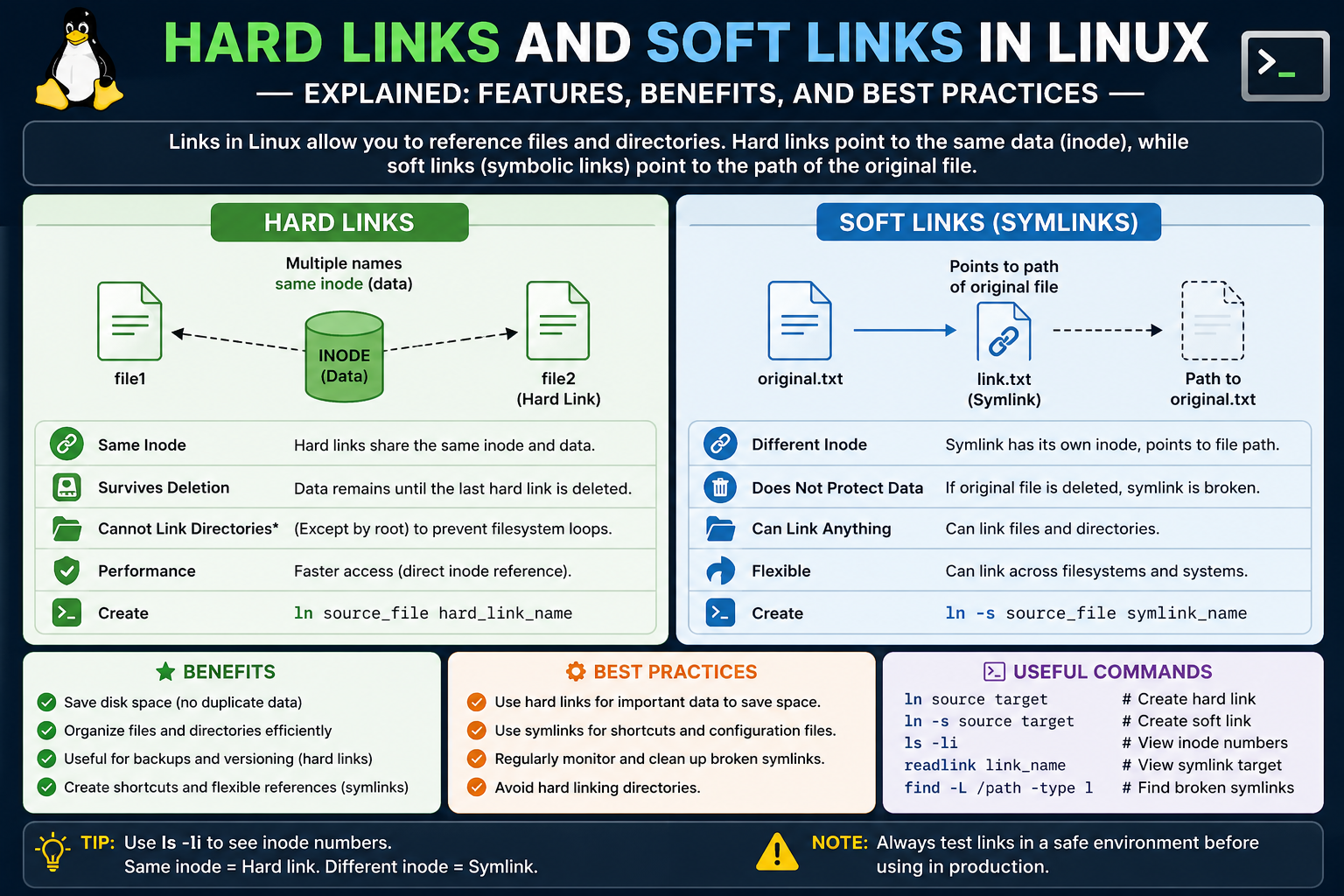
When starting with Linux, one of the biggest challenges is understanding how the system manages files behind the scenes. Unlike some other operating systems, Linux separates the concept of a file’s name from the actual data stored on disk. This design allows for powerful features, one of which is file linking. Among these, hard links and soft links are two fundamental concepts that every Linux user should understand.
At first glance, both hard links and soft links may appear similar because they provide alternative ways to access files. However, they operate very differently at a deeper level. These differences affect how files behave when modified, moved, or deleted. Understanding these behaviors is essential for anyone working with Linux, whether for system administration, development, or general use.
Links are not copies of files in the traditional sense. Instead, they are references. A link provides a way to access file data without duplicating it unnecessarily. This makes links both efficient and flexible, but it also introduces complexity that can be confusing at first.
To fully grasp the concept of links, it is important to first understand how Linux organizes file data internally. Without this foundation, the differences between hard links and soft links can seem abstract.
How Linux Stores Files Internally
In Linux, files are not stored as simple name-and-data pairs. Instead, the system uses a structure called an inode to manage file data. An inode contains important information about a file, such as its size, permissions, ownership, timestamps, and pointers to the actual data blocks on the disk.
The filename itself is not stored inside the inode. Instead, filenames are stored in directories, which act as mappings between names and inode numbers. This means that a filename is simply a reference to an inode.
This separation is what makes linking possible. Since filenames and data are not tightly bound together, multiple filenames can point to the same inode. This is the key idea behind hard links.
When a file is created, the system assigns it an inode and creates a directory entry that maps the filename to that inode. When you access the file, the system looks up the filename, retrieves the inode, and then uses the inode to locate the data.
This design allows Linux to manage files more efficiently and provides flexibility in how files are accessed. It also means that deleting a filename does not necessarily delete the data. The data is only removed when no references to its inode remain.
Understanding this relationship between filenames and inodes is crucial. Without it, the behavior of hard links and soft links can seem confusing or even unpredictable.
What is a Hard Link
A hard link is essentially another name for the same file data. When you create a hard link, you are creating an additional directory entry that points to the same inode as the original file. This means both names refer to the same underlying data.
From a user’s perspective, hard-linked files look like separate files. They can have different names and can exist in different directories. However, they are not independent copies. They are simply multiple references to the same data.
Because of this, any change made through one hard link is immediately visible through the other. Editing one file modifies the data stored in the inode, so all links reflect the change.
Another important characteristic of hard links is that there is no concept of an original file once a hard link is created. All links are equal. The system does not distinguish between the first filename and subsequent ones.
This can be surprising to new users. For example, deleting what appears to be the original file does not remove the data if other hard links still exist. The system only deletes the data when all references to the inode are removed.
Hard links are tightly tied to the filesystem. Since they reference inodes directly, they cannot span across different filesystems. This limitation is important to keep in mind when working with multiple storage devices or partitions.
How Hard Links Behave
The behavior of hard links is closely tied to how inodes work. When a hard link is created, the system increases the reference count of the inode. This count represents how many directory entries point to that inode.
When you delete a file, you are actually removing a directory entry. The inode and its data remain intact as long as the reference count is greater than zero. Only when the count reaches zero does the system free the data blocks.
This behavior makes hard links very reliable. They ensure that data is not accidentally lost as long as at least one reference remains. This can be particularly useful in scenarios where data integrity is important.
However, this behavior can also lead to confusion. Users may delete a file expecting it to be gone, only to find that it still exists through another hard link. This is not a bug but a feature of how the system is designed.
Another aspect of hard links is that they share metadata in the inode. This means attributes like file size and modification time are the same across all links. However, directory entries themselves can have different names and locations.
Hard links also cannot typically be created for directories. This restriction exists to prevent circular references that could complicate filesystem traversal and maintenance.
What is a Soft Link
A soft link, also known as a symbolic link, works in a completely different way. Instead of pointing directly to an inode, a soft link points to a file path. It is essentially a small file that contains the location of another file or directory.
When you access a soft link, the system reads the path stored in the link and uses it to locate the target file. This extra step is what distinguishes soft links from hard links.
Soft links behave much like shortcuts. They provide a convenient way to reference files without duplicating them. However, because they rely on paths, they are more fragile than hard links.
If the target file is moved or deleted, the soft link no longer points to a valid location. In such cases, the link becomes broken. A broken link still exists, but it cannot be used to access any data.
Despite this limitation, soft links are very useful. They can point to directories, files in different filesystems, and even remote locations. This flexibility makes them a powerful tool for organizing files and creating efficient workflows.
Soft links also take up very little space. Since they only store a path, their size is independent of the size of the target file. This makes them ideal for referencing large files without consuming additional storage.
How Soft Links Behave
Soft links are resolved at runtime. When a program or user tries to access a soft link, the system follows the path stored in the link to find the target file. If the path is valid, the operation proceeds as if the target file was accessed directly.
If the path is invalid, the system returns an error. This is what happens when a soft link becomes broken. The link itself still exists, but it cannot fulfill its purpose.
One advantage of soft links is their flexibility. They can be used to create references across different parts of the filesystem, making it easier to organize files without moving them.
For example, a user can keep files in one location and create soft links to them in another directory for convenience. This avoids duplication while maintaining easy access.
Soft links are also commonly used in system configurations. They allow administrators to point to different versions of files or directories without changing the structure of the system.
However, their reliance on paths means they must be managed carefully. Moving or renaming target files can break links, leading to errors that may be difficult to diagnose.
Why Understanding Links Matters
Understanding hard links and soft links is not just an academic exercise. These concepts have practical implications for how you manage files in Linux.
For example, knowing how hard links work can help you avoid accidental data loss or duplication. It can also help you understand why certain files behave the way they do when deleted or modified.
Similarly, understanding soft links can help you create more flexible and organized file structures. You can use them to simplify navigation, manage configurations, and optimize storage usage.
These concepts are also important for system administration. Many system tools and processes rely on links to manage files efficiently. Without a clear understanding of how links work, it can be difficult to troubleshoot issues or optimize performance.
In addition, links play a role in backup systems, package management, and file synchronization. Knowing when to use hard links versus soft links can make a significant difference in these contexts.
Common Misconceptions
One common misconception is that links are copies of files. This is not true. Hard links share the same data, while soft links only point to a location. Neither type creates a full duplicate of the file’s content.
Another misconception is that deleting a file always removes its data. As discussed earlier, this is not the case with hard links. The data remains as long as at least one link exists.
Some users also assume that soft links are always safer because they act like shortcuts. In reality, they can be more fragile due to their dependence on paths.
Understanding these misconceptions is important because they can lead to mistakes. For example, relying on a soft link without realizing it can break may result in lost access to important data.
Building a Strong Foundation
Mastering hard links and soft links requires more than memorizing definitions. It involves understanding how Linux manages files at a deeper level.
By learning about inodes, directory entries, and file references, you gain insight into how the system works. This knowledge not only helps with links but also improves your overall understanding of Linux.
As you continue to explore Linux, you will encounter many situations where links are used. Having a solid foundation will make these situations easier to handle and allow you to use links effectively.
In the next part, the focus will shift to a deeper exploration of hard links, including how they are created, how they behave in real-world scenarios, and what limitations they have. This will build on the concepts introduced here and provide a more practical understanding of how hard links function in everyday use.
Introduction to Hard Links in Practical Scenarios
After understanding the basic concepts of file linking and how Linux separates filenames from actual data, it is time to explore hard links in greater depth. Hard links are one of the most powerful yet misunderstood features of the Linux filesystem. While they may seem simple at first, their behavior reveals important details about how Linux handles files internally.
A hard link is not a shortcut or a reference to a filename. Instead, it is a direct reference to the same inode that stores the file’s data. This means that multiple filenames can point to the exact same data without creating duplicate copies. Because of this, hard links behave very differently from what most users expect when they first encounter them.
To fully understand hard links, it is important to move beyond definitions and examine how they behave in real-world situations. This includes how they are created, how they interact with file operations, and how they affect storage and data management.
Creating Hard Links in Linux
Creating a hard link in Linux is straightforward, but the simplicity of the command hides the complexity of what is happening underneath. The command used to create a hard link is ln, followed by the source file and the name of the new link.
When this command is executed, the system does not copy the file’s data. Instead, it creates a new directory entry that points to the same inode as the original file. This means both filenames are now equal references to the same data.
After creating a hard link, listing the files in a directory may show two separate files. However, a closer inspection reveals that they share the same inode number. This is the key indicator that they are hard-linked.
Another detail that becomes visible is the link count. This number represents how many directory entries are pointing to the inode. When a hard link is created, this count increases. When a link is deleted, the count decreases.
Understanding this link count is important because it determines when the system will actually remove the file’s data. The data remains on disk as long as the link count is greater than zero.
Editing Files Through Hard Links
One of the most important characteristics of hard links is that they share the same data. This becomes very clear when editing files.
If you open one of the linked files and make changes, those changes are reflected in all other hard links. This is because there is only one copy of the data, and all links point to it.
This behavior can be surprising at first. Users often expect that modifying one file will not affect another, especially if the files have different names. However, with hard links, there is no distinction between files at the data level.
This property can be useful in certain situations. For example, it allows multiple applications or users to access and modify the same data without creating duplicates. It also ensures consistency, as there is only one version of the data.
However, it also requires careful handling. Accidental changes to one link will affect all others, which can lead to unintended consequences if not properly managed.
Deleting Hard Links and Data Persistence
Deleting files in Linux behaves differently when hard links are involved. When a file is removed using a command, the system deletes the directory entry, not the data itself.
If the file has multiple hard links, removing one link does not affect the others. The data remains intact because there are still references to it. The inode’s link count is simply reduced by one.
Only when the link count reaches zero does the system delete the inode and free the associated data blocks. This ensures that data is not lost as long as at least one reference exists.
This behavior is particularly useful for protecting important data. It provides a built-in safeguard against accidental deletion. Even if one link is removed, the data can still be accessed through another.
However, this can also lead to confusion. Users may believe they have deleted a file, only to find that it still exists under a different name. Understanding how link counts work helps avoid this confusion.
Moving and Renaming Hard Links
When working with hard links, it is important to understand how moving and renaming files affects them. Since filenames are simply directory entries, renaming a file does not change the inode or the data.
If you rename one hard link, the other links remain unchanged. They continue to point to the same inode, and the data remains accessible through all names.
Moving a hard link within the same filesystem also does not affect the data. The directory entry is simply relocated, but it still points to the same inode.
However, moving files across different filesystems is not possible with hard links. Since inodes are specific to a filesystem, hard links cannot span across boundaries. Attempting to move a hard link to another filesystem effectively creates a copy rather than preserving the link.
This limitation is important when working with multiple storage devices or partitions. It highlights one of the key differences between hard links and other file management techniques.
Storage Efficiency and Space Management
One of the major advantages of hard links is their efficiency in terms of storage. Since multiple links point to the same data, there is no duplication of file content.
This can be especially beneficial when working with large files. Instead of creating multiple copies, you can create hard links to provide access from different locations without consuming additional space.
This property is often used in backup systems. Some backup tools use hard links to create snapshots of files. Each snapshot appears to be a full copy, but unchanged files are actually shared between snapshots through hard links.
This approach saves a significant amount of disk space while still allowing access to previous versions of files. It also improves performance by avoiding unnecessary data duplication.
However, it is important to remember that all hard links share the same data. Modifying a file affects all links, which may not be desirable in all situations. Careful planning is required when using hard links for storage management.
Limitations of Hard Links
Despite their advantages, hard links have several limitations that must be understood. One of the most significant limitations is their restriction to a single filesystem. This means you cannot create hard links between files on different disks or partitions.
Another limitation is that hard links are generally not allowed for directories. This restriction exists to prevent cycles in the filesystem, which could lead to infinite loops and make navigation difficult.
Hard links also do not provide a clear distinction between original and linked files. Once a hard link is created, all references are equal. This can make file management more complex, especially in large systems.
Additionally, because hard links share the same inode, they also share metadata such as permissions and timestamps. Changing these attributes affects all links, which may not always be desirable.
Understanding these limitations is essential for using hard links effectively. They are powerful tools, but they are not suitable for every situation.
Real-World Use Cases for Hard Links
Hard links are used in a variety of real-world scenarios where efficiency and reliability are important. One common use case is in backup systems, where they help reduce storage requirements while maintaining multiple versions of files.
Another use case is in software development. Developers may use hard links to manage different builds or versions of files without duplicating data. This can save space and simplify workflows.
Hard links are also useful for organizing files. For example, a single file can be accessed from multiple directories without creating copies. This can make it easier to manage large collections of data.
In system administration, hard links can be used to ensure that critical files are not accidentally deleted. By maintaining multiple references, administrators can add an extra layer of protection.
These use cases highlight the practical benefits of hard links. They provide a combination of efficiency, reliability, and flexibility that can be valuable in many situations.
Common Pitfalls and Best Practices
While hard links are useful, they can also lead to mistakes if not used carefully. One common pitfall is assuming that deleting a file removes its data. As discussed earlier, this is not the case when multiple hard links exist.
Another issue is modifying files without realizing that changes will affect all links. This can lead to unexpected results, especially in collaborative environments.
To avoid these problems, it is important to keep track of link counts and understand how files are connected. Tools that display inode numbers and link counts can be helpful for this purpose.
It is also a good practice to use hard links only when their behavior is clearly understood. In situations where independent copies are needed, traditional file copying may be more appropriate.
Careful planning and awareness can help you take full advantage of hard links while avoiding potential issues.
Building Confidence with Hard Links
Gaining confidence with hard links comes from practice and experimentation. By creating links, modifying files, and observing how the system behaves, you can develop a deeper understanding of how they work.
This hands-on experience reinforces the concepts discussed earlier and helps make them more intuitive. Over time, the behavior of hard links becomes easier to predict and manage.
Understanding hard links also provides insight into the broader design of the Linux filesystem. It reveals how the system prioritizes efficiency and flexibility, even if it introduces some complexity.
In the next part, the focus will shift to soft links. While they may appear simpler on the surface, they offer a different set of capabilities and challenges. Comparing them directly with hard links will provide a complete picture of how file linking works in Linux.
Introduction to Soft Links
Soft links, also known as symbolic links, provide a flexible and widely used way to reference files in Linux. While hard links connect directly to the underlying data, soft links take a different approach by pointing to a file’s path instead. This distinction may seem small at first, but it leads to major differences in how soft links behave in real-world scenarios.
A soft link is essentially a special file that contains a reference to another file or directory. When you access a soft link, the system follows the stored path to locate the actual target. This makes soft links similar to shortcuts, allowing users to access files without duplicating them.
Soft links are designed to be lightweight and flexible. They can point to almost anything within the filesystem and even beyond it. Because of this, they are commonly used in everyday Linux tasks, system configuration, and file organization.
Understanding soft links is important because they are used extensively across Linux systems. Many system-level operations and configurations rely on symbolic links to manage files efficiently.
Creating Soft Links in Linux
Creating a soft link is simple and uses the same ln command as hard links, but with an additional option. The command includes a flag that tells the system to create a symbolic link instead of a hard link.
When a soft link is created, the system generates a new file that stores the path to the target file. This file is usually very small because it does not contain the actual data of the target.
After creating a soft link, listing directory contents often shows an arrow-like indication pointing from the link to its target. This makes it easy to identify symbolic links and understand where they lead.
Unlike hard links, soft links can be created for directories as well as files. This makes them much more versatile in organizing complex directory structures.
Another important feature is that soft links can point to files that do not yet exist. This allows users to set up links in advance, which can be useful in scripting and system configuration.
How Soft Links Work Internally
Soft links operate by storing a path rather than referencing an inode directly. When a user or program accesses a soft link, the system reads the stored path and attempts to locate the target file.
This process involves an extra step compared to hard links. Instead of directly accessing the data, the system must resolve the path first. While this adds a small overhead, it is usually negligible in most use cases.
The reliance on paths is what gives soft links their flexibility. They are not tied to a specific inode or filesystem, so they can point to targets across different locations.
However, this design also introduces a level of fragility. If the path becomes invalid, the link no longer works. This is a key difference from hard links, which remain valid as long as the data exists.
Behavior When Accessing Soft Links
When accessing a soft link, the system treats it as a pointer to another file. If the target exists, operations performed on the link are applied to the target file.
For example, reading from a soft link retrieves the contents of the target file. Writing to a soft link modifies the target file. From the user’s perspective, this behavior feels seamless.
However, if the target file is missing, the system cannot resolve the path. In this case, the soft link becomes broken. Attempting to access it results in an error.
Broken links are a common issue when working with symbolic links. They occur when files are moved, renamed, or deleted without updating the links that point to them.
Despite this, soft links remain in the filesystem even when broken. This can be useful for debugging or restoring links once the target becomes available again.
Deleting and Moving Soft Links
Deleting a soft link is straightforward and does not affect the target file. Since the link is just a separate file containing a path, removing it only deletes that reference.
This is an important distinction from hard links. With hard links, removing a file may still leave the data accessible through other links. With soft links, the link and the target are completely independent.
Moving or renaming a soft link does not affect the target file either. However, moving or renaming the target file can break the link if the stored path is no longer valid.
This behavior highlights the importance of managing paths carefully when using soft links. Relative paths can sometimes reduce the risk of broken links, depending on the situation.
Advantages of Soft Links
Soft links offer several advantages that make them an essential tool in Linux. One of the biggest advantages is flexibility. They can point to files, directories, and even locations across different filesystems.
This makes them ideal for organizing files without physically moving them. For example, you can keep files in one directory and create links to them in another for easier access.
Soft links also take up very little space. Since they only store a path, their size is minimal regardless of the size of the target file. This makes them efficient for referencing large files.
Another advantage is their transparency. When listing files, it is usually clear which ones are symbolic links and where they point. This makes them easier to identify and manage.
Soft links are also widely used in system configurations. They allow administrators to switch between different versions of files or directories without changing the overall structure.
Limitations of Soft Links
Despite their flexibility, soft links have some limitations. The most significant limitation is their dependence on the target file’s path. If the target is moved or deleted, the link becomes useless.
This can lead to broken links, which may cause errors in applications or scripts that rely on them. Managing these links requires careful attention to file locations.
Another limitation is the slight performance overhead involved in resolving the path. While this is usually negligible, it can become noticeable in systems with a large number of symbolic links.
Soft links also do not provide the same level of data protection as hard links. Since they do not reference the actual data, they cannot preserve access if the original file is removed.
Understanding these limitations helps in deciding when to use soft links and when to choose other methods.
Comparing Soft Links and Hard Links
The differences between soft links and hard links become clearer when comparing their behavior directly. Hard links point to the actual data through inodes, while soft links point to a file path.
This difference affects how they respond to file deletion. Hard links remain valid as long as the data exists, while soft links break if the target is removed.
Hard links are limited to a single filesystem and cannot usually link directories. Soft links can span across filesystems and link to directories without restrictions.
In terms of storage, hard links do not consume additional space for data, while soft links use a small amount of space to store the path.
From a usability perspective, soft links are easier to identify and manage, while hard links require a deeper understanding of inodes and link counts.
Each type of link has its strengths and weaknesses. Choosing the right one depends on the specific requirements of the task.
Real-World Applications of Soft Links
Soft links are widely used in many areas of Linux systems. One common use is in organizing files and directories. Users can create links to frequently accessed files, making navigation easier.
They are also heavily used in system administration. For example, configuration files often use symbolic links to point to active versions. This allows administrators to switch configurations without modifying multiple files.
In software development, soft links can be used to manage dependencies and project structures. They allow developers to reference shared resources without duplicating them.
Soft links are also useful in scripting. Scripts can rely on symbolic links to access files in predictable locations, even if the actual files are stored elsewhere.
These applications demonstrate the versatility of soft links and their importance in everyday Linux usage.
Best Practices for Using Soft Links
Using soft links effectively requires careful planning. One important practice is to ensure that target paths remain valid. This may involve avoiding unnecessary file movements or updating links when changes occur.
Using relative paths instead of absolute paths can sometimes make links more robust. Relative paths adjust based on the link’s location, which can help prevent breakage in certain scenarios.
Regularly checking for broken links is also a good practice. Tools are available that can scan directories and identify links that no longer point to valid targets.
It is also important to document the use of symbolic links in complex systems. This helps others understand how files are connected and reduces the risk of errors.
By following these practices, you can make the most of soft links while minimizing potential issues.
Conclusion
Hard links and soft links are fundamental concepts in Linux that provide powerful ways to manage files. While they may seem similar at a glance, their differences are significant and affect how they behave in various situations.
Hard links connect directly to the file’s data, making them reliable and efficient. They ensure that data remains accessible as long as at least one link exists. However, they come with limitations such as filesystem restrictions and the inability to link directories.
Soft links, on the other hand, offer flexibility and convenience. They act as pointers to file paths, allowing users to create shortcuts and organize files easily. Their ability to span filesystems and link directories makes them highly versatile, but their dependence on paths makes them more fragile.
Understanding when to use each type of link is essential for effective file management in Linux. Hard links are ideal for scenarios where data integrity and storage efficiency are priorities. Soft links are better suited for situations that require flexibility and ease of use.
By mastering both types of links, you gain a deeper understanding of how Linux handles files. This knowledge not only improves your ability to work with the system but also helps you design more efficient and reliable workflows.
In the end, both hard links and soft links are valuable tools. Knowing their strengths and limitations allows you to use them wisely and take full advantage of what Linux has to offer.