In today’s digital-first world, organizations rely heavily on uninterrupted access to applications, networks, databases, and online services. Businesses of all sizes—from small startups to multinational enterprises—depend on technology for communication, transactions, customer engagement, internal collaboration, and data management. Because of this dependence, even a brief interruption can lead to significant operational disruption, financial loss, reputational damage, and customer dissatisfaction.
Modern users expect services to be available around the clock. Whether it is online banking, cloud storage, e-commerce, healthcare systems, or communication platforms, downtime is no longer viewed as a minor inconvenience. It is often seen as a critical failure. For businesses, the stakes are high. A single outage can affect productivity, halt revenue generation, compromise customer trust, and even create regulatory consequences.
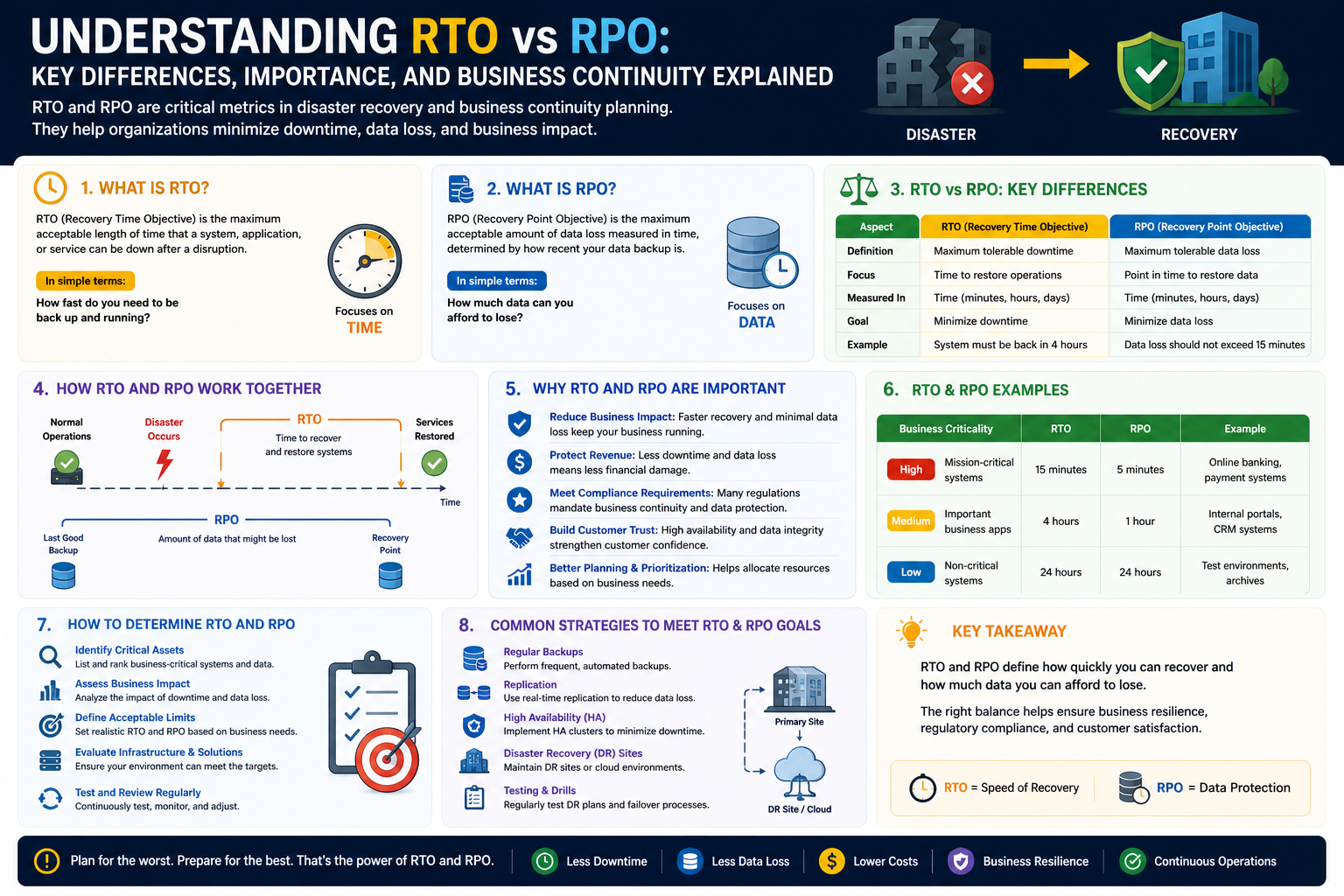
This reality has made business continuity and disaster recovery essential components of organizational strategy. Rather than simply reacting to failures after they occur, organizations must proactively define how quickly systems should recover and how much data loss is acceptable. These expectations are measured through two critical business continuity metrics: Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
Understanding these two concepts is fundamental for IT teams, network engineers, security professionals, cloud architects, and business leaders alike. They are not just technical terms—they are strategic business decisions that shape infrastructure design, backup policies, disaster recovery investments, and operational resilience.
Why Downtime Is More Expensive Than Ever
Historically, businesses could sometimes tolerate extended outages because fewer operations depended on digital systems. Today, however, technology is deeply embedded in nearly every business process. Sales platforms, payroll systems, supply chains, customer support portals, remote collaboration tools, and cybersecurity monitoring all rely on constant system availability.
Downtime costs can be measured in several ways:
Lost Revenue: If an online store is unavailable, sales stop immediately.
Operational Delays: Employees may be unable to perform critical tasks.
Reputational Harm: Customers may lose trust in unreliable services.
Regulatory Penalties: Industries like healthcare or finance may face compliance issues.
Data Integrity Risks: Interrupted systems may lead to corruption or incomplete transactions.
For example, a streaming platform outage may frustrate users, but a hospital system outage can delay patient care. A payment gateway outage can stop commerce globally. This variation means different organizations require different recovery priorities, which is where RTO and RPO become essential.
Defining Recovery Time Objective (RTO)
Recovery Time Objective refers to the maximum acceptable amount of time that a system, service, or business process can remain unavailable after a disruption before the consequences become unacceptable.
In simple terms, RTO answers one question:
“How quickly must this system be restored?”
This metric establishes the target duration for recovering systems after incidents such as:
Hardware failures
Cyberattacks
Natural disasters
Power outages
Software corruption
Human error
If an organization sets an RTO of one hour for its customer payment system, that means the system must be restored within sixty minutes to avoid severe business consequences.
RTO is primarily focused on downtime duration rather than data loss.
The Strategic Importance of RTO
RTO is not chosen randomly. It reflects business priorities, customer expectations, operational dependencies, and financial tolerance.
Shorter RTOs usually indicate mission-critical systems, such as:
Financial transaction platforms
Emergency communication systems
Healthcare databases
Manufacturing control systems
Cloud-based customer applications
Longer RTOs may apply to less critical systems, such as:
Internal training portals
Archived databases
Non-essential file servers
Legacy systems with minimal operational impact
Determining RTO requires organizations to assess the cost of downtime versus the cost of rapid recovery solutions.
Factors That Influence RTO
Several variables shape how RTO is established and achieved.
System Complexity
Complex systems with multiple dependencies often require more time to restore. For example, restoring a standalone file server is simpler than recovering a globally distributed cloud application with databases, APIs, security layers, and load balancers.
Business Impact
The more financially or operationally critical a system is, the shorter its acceptable downtime.
Resource Availability
Organizations with dedicated disaster recovery sites, trained personnel, automation, and spare infrastructure can often achieve faster recovery times.
Technology Architecture
Highly available systems with redundancy and failover mechanisms naturally support shorter RTOs.
Regulatory Requirements
Certain sectors may be legally required to restore systems within strict timeframes.
Examples of RTO in Real-World Environments
E-Commerce Platform:
An online retailer during peak shopping season may require an RTO of five minutes because every minute offline means lost revenue.
Healthcare Records System:
A hospital may require near-immediate restoration because patient care depends on data access.
Human Resources Portal:
An HR portal may tolerate several hours of downtime without catastrophic consequences.
These examples demonstrate that RTO is highly contextual.
Methods for Improving RTO
Organizations invest in several strategies to reduce downtime and meet aggressive recovery goals.
Automation
Automated recovery systems detect failures and initiate failover processes without waiting for human intervention.
Failover Infrastructure
Secondary systems automatically take over when primary systems fail.
Redundant Hardware
Duplicate servers, switches, storage devices, and network paths reduce restoration delays.
Disaster Recovery Planning
Documented and tested recovery procedures eliminate confusion during crises.
Cloud Recovery Solutions
Cloud providers often offer geographically distributed redundancy and rapid recovery options.
The Human Element in RTO
Even the best technology can fail if teams are unprepared. Incident response teams, network administrators, security engineers, and business continuity managers must all understand their roles.
Training improves:
Decision speed
Error reduction
Communication efficiency
Escalation accuracy
Without preparation, even advanced infrastructure may experience prolonged outages.
Defining Recovery Point Objective (RPO)
While RTO focuses on downtime, Recovery Point Objective focuses on data loss tolerance.
RPO answers this question:
“How much data can we afford to lose?”
RPO measures the maximum acceptable amount of data loss in time. For example, if backups occur every four hours, the worst-case data loss could be four hours of transactions.
If a business sets an RPO of fifteen minutes, backup or replication systems must ensure that no more than fifteen minutes of data can be lost.
Why RPO Matters
Data is often more valuable than hardware. Systems can be rebuilt, but lost transactions, customer records, financial entries, or operational data may be impossible to recreate.
Poor RPO planning can lead to:
Financial discrepancies
Legal issues
Customer dissatisfaction
Compliance failures
Permanent business intelligence loss
Factors That Influence RPO
Backup Frequency
More frequent backups reduce potential data loss.
Data Change Rate
Systems with constant updates often require lower RPOs.
Replication Technology
Real-time replication significantly improves RPO.
Storage Infrastructure
Fast, scalable storage enables more frequent recovery points.
Cost Constraints
Shorter RPOs often require more expensive infrastructure.
Examples of RPO by Industry
Banking:
Seconds or near-zero tolerance due to transaction sensitivity.
Retail:
Minutes to preserve order integrity.
Education:
Hours may be acceptable for less critical systems.
Media Streaming:
User progress data may tolerate moderate loss, depending on platform design.
RTO vs. RPO: Understanding the Difference
Though often discussed together, these metrics serve different purposes.
RTO = How long systems can be down
RPO = How much data can be lost
An organization may recover quickly but lose hours of data, or preserve data perfectly but take too long to restore operations.
Effective continuity planning balances both.
Why Businesses Must Balance Both Metrics
Reducing RTO without improving RPO may restore services quickly but with missing data.
Reducing RPO without improving RTO may preserve data but leave systems unavailable too long.
Organizations must evaluate:
Business priorities
Customer expectations
Operational costs
Risk tolerance
Common Misunderstandings
Many organizations mistakenly assume backups alone guarantee resilience. Backups are only one part of continuity. Recovery speed, testing, redundancy, and infrastructure design all matter.
Another misconception is that cloud services automatically guarantee ideal RTO and RPO. While cloud platforms improve resilience, organizations must still configure backup frequency, redundancy, and failover properly.
Business Impact Analysis and Recovery Objectives
Before setting RTO or RPO, organizations perform a Business Impact Analysis (BIA).
This process identifies:
Critical systems
Operational dependencies
Financial risks
Downtime costs
Data sensitivity
A proper BIA ensures recovery goals align with real business needs rather than assumptions.
The Cost of Aggressive Recovery Targets
Near-zero RTO and RPO are possible, but they require substantial investment.
These may include:
Multiple data centers
Real-time replication
Advanced automation
24/7 staffing
Premium cloud services
For some businesses, this cost is justified. For others, moderate recovery objectives provide better balance.
Building a Culture of Resilience
Business continuity is not solely an IT responsibility. Leadership, operations, security, compliance, and customer service all play roles.
Resilience requires:
Executive support
Policy enforcement
Regular audits
Cross-team coordination
Continuous testing
Organizations that treat continuity as a strategic priority are better prepared for disruption.
Introduction to Advanced Recovery Optimization
Once organizations understand the foundational concepts of Recovery Time Objective (RTO) and Recovery Point Objective (RPO), the next challenge is implementation. Knowing how quickly systems must recover and how much data loss is acceptable is only the beginning. The true complexity lies in designing infrastructure, policies, and operational strategies that consistently meet those targets under real-world conditions.
Modern organizations operate in environments where failures are inevitable. Hardware ages, software contains bugs, human errors occur, cyberattacks evolve, and natural disasters remain unpredictable. The goal of business continuity is not to eliminate every possible failure but to create systems resilient enough to withstand disruption while maintaining operational stability.
This is where advanced continuity strategies become essential. Redundancy, high availability, disaster recovery architecture, replication technologies, automation, and resilience engineering all contribute to reducing downtime and preserving data integrity.
Organizations that excel in continuity planning do not simply recover from failures—they design systems that anticipate failure, minimize impact, and restore normal operations rapidly.
From Recovery Planning to Resilience Engineering
Traditional disaster recovery often focused on restoring operations after a catastrophic event. Modern resilience engineering expands this perspective by designing systems that continue operating even when failures occur.
Rather than asking:
“How do we recover after failure?”
Organizations increasingly ask:
“How do we prevent a single failure from causing disruption?”
This mindset shift fundamentally changes how infrastructure is built.
Resilience engineering includes:
Fault tolerance
Distributed systems
Load balancing
Automatic failover
Self-healing automation
Multi-region deployment
This approach directly improves both RTO and RPO by reducing dependency on reactive recovery alone.
Understanding Redundancy as the Foundation of Availability
Redundancy refers to duplicating critical components so that if one fails, another can immediately take over.
This principle applies across multiple layers:
Hardware redundancy
Network redundancy
Power redundancy
Application redundancy
Data redundancy
Geographic redundancy
Each layer addresses different failure scenarios.
For example:
A redundant power supply protects against electrical failure.
A secondary ISP connection protects against internet outages.
A replicated database protects against storage corruption.
A geographically separate data center protects against regional disasters.
True resilience requires layered redundancy rather than isolated backup measures.
Hardware Redundancy and Physical Infrastructure Protection
Physical infrastructure failures remain one of the most common causes of downtime.
Common risks include:
Server hardware failure
Disk corruption
Power supply malfunction
Cooling system breakdown
Network switch failure
To reduce RTO, organizations often implement:
RAID storage arrays
Dual power supplies
Backup generators
Hot-swappable hardware
Clustered server environments
Redundant cooling systems
Hot-swappable systems are particularly valuable because they allow failed components to be replaced without shutting down services.
For mission-critical environments, hardware redundancy is often non-negotiable.
Network Redundancy and Communication Continuity
Network outages can render systems inaccessible even when servers remain operational.
Network redundancy strategies include:
Multiple internet service providers
Failover firewalls
Secondary routers
Redundant switches
Load-balanced pathways
Dynamic routing protocols
Technologies such as VRRP, HSRP, and SD-WAN improve network resilience by automatically redirecting traffic when primary routes fail.
Without network redundancy, organizations may technically preserve systems and data but still fail to meet RTO because users cannot connect.
Application Redundancy and Service Continuity
Application redundancy focuses on maintaining service availability by running multiple instances of critical applications.
Examples include:
Web server clusters
Container orchestration platforms
Microservices replication
Load-balanced application pools
Cloud auto-scaling groups
If one application node fails, traffic shifts to healthy nodes.
This model is especially important for customer-facing platforms where even brief service interruption can cause significant business damage.
Application redundancy is central to modern cloud-native architecture.
Data Redundancy and Storage Resilience
Data redundancy directly impacts RPO by ensuring multiple copies of critical information exist.
Methods include:
Onsite backups
Offsite backups
Cloud backups
Real-time replication
Snapshot technology
Immutable storage
The more frequently data is copied or replicated, the lower potential data loss becomes.
However, redundancy must also account for corruption risks. Simply duplicating corrupted data can spread damage rapidly.
This is why versioned backups and immutable storage are increasingly important.
High Availability (HA): Beyond Simple Redundancy
Redundancy alone does not guarantee high availability. High Availability (HA) is a system design principle focused on ensuring continuous service operation with minimal interruption.
HA systems combine:
Redundant infrastructure
Automatic failover
Load balancing
Continuous health monitoring
Fault isolation
Rapid scaling
The objective is to keep services operational even during component failure.
For example, if one server fails, HA systems redirect traffic seamlessly to another node.
High availability minimizes downtime rather than merely accelerating recovery after downtime occurs.
Availability Tiers and Business Expectations
Availability is often measured in uptime percentages:
99% uptime = ~3.65 days downtime annually
99.9% uptime = ~8.76 hours downtime annually
99.99% uptime = ~52.56 minutes downtime annually
99.999% uptime = ~5.26 minutes downtime annually
As uptime expectations rise, infrastructure complexity and cost increase significantly.
Many organizations pursue “five nines” availability, but achieving this requires advanced architecture and investment.
Disaster Recovery Sites: Cold, Warm, and Hot
Disaster recovery environments are often categorized by readiness.
Cold Site
Basic infrastructure with minimal active resources.
Pros:
Lower cost
Cons:
Longer RTO
Warm Site
Partially operational environment with some preconfigured systems.
Pros:
Moderate cost and faster recovery
Cons:
Requires additional activation steps
Hot Site
Fully operational replica capable of immediate failover.
Pros:
Very short RTO
Cons:
High cost
Choosing the right site depends on business priorities and budget.
Replication Technologies and RPO Optimization
Replication is central to reducing data loss.
Synchronous Replication
Writes data simultaneously to primary and secondary systems.
Advantages:
Near-zero RPO
Disadvantages:
Latency
Bandwidth demands
Higher cost
Asynchronous Replication
Writes data to the secondary system after primary confirmation.
Advantages:
Lower performance impact
Disadvantages:
Potential data gap
Continuous Data Protection (CDP)
Tracks and records every change.
Advantages:
Extremely low RPO
Granular recovery
Disadvantages:
Complexity
CDP is especially valuable for financial or transactional environments.
Cloud Disaster Recovery and Elastic Resilience
Cloud computing has transformed disaster recovery by reducing infrastructure barriers.
Benefits include:
Rapid provisioning
Cross-region deployment
Pay-as-you-scale economics
Automated snapshots
Managed replication
Infrastructure-as-code recovery
Cloud disaster recovery also supports hybrid continuity models where on-premises systems replicate to cloud failover environments.
However, organizations must understand shared responsibility models. Cloud providers secure infrastructure, but customers remain responsible for configuration, backup strategy, and access management.
Automation as a Force Multiplier
Automation dramatically improves RTO by eliminating manual intervention delays.
Examples include:
Automated failover
Backup scheduling
Health monitoring
Configuration restoration
Infrastructure provisioning
Security containment
Automation reduces:
Human error
Response delays
Operational inconsistency
However, automation must be carefully tested because incorrect automation can amplify failures.
Orchestration and Coordinated Recovery
In complex environments, restoring one server is insufficient if dependencies remain offline.
Orchestration ensures:
Databases restore first
Authentication systems initialize
Applications reconnect properly
Networking routes correctly
Security policies apply
This dependency-aware approach is essential for enterprise continuity.
Cybersecurity’s Role in Recovery Objectives
Ransomware and destructive malware have reshaped disaster recovery planning.
Traditional backup strategies may fail if attackers compromise backup systems.
Modern protections include:
Immutable backups
Air-gapped storage
Zero-trust segmentation
Backup authentication controls
Threat detection integration
Cyber resilience now requires backup systems that survive intentional attacks.
Geographic Distribution and Regional Resilience
Regional disasters—including earthquakes, floods, and political disruptions—can disable entire facilities.
Multi-region deployment reduces this risk through:
Cross-country backups
Regional failover
Distributed DNS
Global traffic management
This strategy is particularly critical for multinational organizations.
Operational Testing and Recovery Validation
Disaster recovery plans must be tested regularly. A recovery strategy that exists only on paper cannot guarantee operational resilience during real disruption. Systems evolve, infrastructure changes, software updates introduce new dependencies, and business priorities shift over time. Without frequent testing, organizations may discover critical failures only during an actual emergency—when the cost of mistakes is highest.
Testing methods include:
Backup restoration drills
Regional failover simulations
Cyberattack scenarios
Chaos engineering
Dependency testing
Testing identifies weaknesses before real incidents occur.
Backup restoration drills confirm that data can actually be recovered accurately, within required RPO timelines, and without corruption. Regional failover simulations test whether operations can successfully transition to secondary sites or alternate cloud regions when primary environments fail. Cyberattack scenarios evaluate readiness against ransomware, destructive malware, insider threats, or compromised credentials, ensuring recovery systems remain secure under hostile conditions. Chaos engineering intentionally introduces controlled failures into live or simulated environments to measure system resilience, expose hidden vulnerabilities, and strengthen fault tolerance. Dependency testing verifies that interconnected applications, authentication systems, databases, APIs, and third-party services recover in the correct order without creating operational bottlenecks.
Regular testing also improves team confidence, clarifies communication procedures, validates documentation, and exposes outdated assumptions. It allows leadership to measure actual recovery performance against target RTO and RPO goals. Most importantly, testing transforms continuity planning from theory into proven capability, ensuring organizations are prepared not only to recover—but to recover effectively, predictably, and under pressure.
Cost-Benefit Analysis of Recovery Investments
Reducing RTO and RPO often requires balancing protection against expense.
Questions organizations must answer:
What is one hour of downtime worth?
What is one hour of lost data worth?
What level of investment matches business risk?
Overengineering can waste resources, while underinvestment creates vulnerability.
Metrics, Monitoring, and Continuous Improvement
Effective recovery optimization requires measurable outcomes.
Key metrics include:
Mean Time to Detect (MTTD)
Mean Time to Recover (MTTR)
Backup success rates
Replication lag
System availability percentages
These metrics support strategic refinement.
Building Organizational Readiness
Technology alone cannot guarantee recovery. Even the most advanced infrastructure, automation platforms, backup systems, and failover architectures can fall short if organizational readiness is weak. Successful continuity depends equally on human coordination, strategic governance, and operational discipline.
Organizations also need:
Clear communication plans
Role definitions
Leadership alignment
Vendor coordination
Employee training
Prepared teams execute faster and more effectively under pressure.
Communication plans ensure accurate, timely information reaches employees, customers, stakeholders, and regulators during disruption. Clearly defined roles prevent confusion by establishing who leads, who escalates, who communicates, and who executes technical recovery. Leadership alignment ensures executives support continuity priorities, allocate resources properly, and make decisive choices during crises. Vendor coordination is equally critical because third-party outages or delayed support can significantly slow recovery efforts. Regular employee training, tabletop exercises, and full-scale simulations help staff understand procedures before real emergencies occur. Cross-functional collaboration between IT, security, operations, legal, and communications teams also strengthens response efficiency. When people understand responsibilities and processes clearly, organizations reduce panic, improve decision-making speed, and restore operations more effectively. Ultimately, resilience is built not just through technology, but through preparation, coordination, and confident execution.
The Evolution Toward Proactive Continuity
Modern continuity planning increasingly emphasizes prevention over restoration. Traditional disaster recovery focused primarily on restoring systems after disruption occurred, but modern organizations now recognize that true resilience begins long before an outage happens. Instead of waiting for failures and then reacting, proactive continuity aims to anticipate risks, reduce vulnerabilities, and prevent operational disruption before it impacts business functions. This strategic shift reflects growing infrastructure complexity, rising customer expectations, and the increasing financial and reputational cost of downtime.
Key trends include:
Predictive analytics
Self-healing infrastructure
AI-driven anomaly detection
Distributed architecture
Autonomous remediation
These innovations aim to reduce both incident frequency and severity.
Proactive continuity also increasingly depends on continuous monitoring, real-time telemetry, and deep system observability. By collecting and analyzing infrastructure data across applications, networks, endpoints, and cloud environments, organizations can identify weak signals before they become critical failures. For example, unusual latency spikes, storage degradation, or suspicious access behaviors can trigger preventative action automatically. This reduces the likelihood of cascading outages. Infrastructure-as-code and automated policy enforcement further strengthen resilience by ensuring systems are consistently deployed, securely configured, and rapidly recoverable. In addition, cyber resilience now plays a larger role, with zero-trust frameworks, immutable backups, and threat intelligence integration helping organizations prevent security incidents from becoming continuity disasters. Together, these advancements represent a major transformation: business continuity is no longer just about recovering quickly—it is about operating intelligently, predicting disruption, and continuously adapting to prevent crises before they occur.
Introduction to Sustainable Recovery Excellence
Defining Recovery Time Objective (RTO) and Recovery Point Objective (RPO), building redundancy, and deploying high-availability infrastructure are critical steps in continuity planning—but they are not the final destination. Business continuity is not a one-time project. It is an evolving discipline that requires governance, continuous testing, strategic adaptation, leadership alignment, and responsiveness to technological change.
Organizations often make a critical mistake after building recovery architecture: they assume implementation alone guarantees resilience. In reality, systems change constantly. New applications are deployed, vendors change, staff turnover occurs, cyber threats evolve, and business priorities shift. A disaster recovery plan that was effective one year ago may become dangerously outdated if not continuously reviewed.
Long-term success depends on creating a culture where continuity planning is integrated into business operations, strategic leadership, compliance, cybersecurity, and technological innovation. Sustainable resilience means organizations must consistently refine their RTO and RPO strategies to match current realities.
The businesses that recover best are not simply those with advanced infrastructure—they are those with disciplined governance and continuous operational maturity.
The Framework That Sustains Continuity
Governance is the structure through which continuity objectives are maintained, measured, enforced, and improved.
Without governance:
Recovery plans become outdated
Responsibilities become unclear
Testing becomes inconsistent
Budgets may be misaligned
Compliance gaps emerge
Governance ensures continuity remains an active organizational priority rather than a forgotten technical document.
Effective governance includes:
Executive oversight
Policy development
Risk committees
Recovery audits
Compliance integration
Performance metrics
Governance transforms recovery planning from isolated IT responsibility into enterprise-wide accountability.
Executive Leadership and Strategic Ownership
Leadership involvement is one of the strongest predictors of continuity success.
When executives understand RTO and RPO, they can make better decisions about:
Investment priorities
Risk tolerance
Customer commitments
Insurance requirements
Regulatory exposure
Vendor strategy
For example, leadership may determine that maintaining five-minute RTO for customer-facing applications is essential to protect brand trust, while internal reporting systems may tolerate longer recovery windows.
Without executive sponsorship, continuity initiatives may lack funding or strategic relevance.
Business continuity must align with organizational mission, not just infrastructure capability.
Policy Development and Documentation Standards
Policies provide the formal rules that govern recovery expectations.
Strong policies define:
Acceptable downtime thresholds
Data retention requirements
Backup schedules
Testing frequency
Escalation procedures
Communication responsibilities
Vendor obligations
Documentation must also remain current. Recovery procedures written for legacy systems may fail entirely in cloud-native or hybrid environments.
Documentation should include:
System inventories
Dependency maps
Recovery playbooks
Contact chains
Regulatory obligations
Third-party service dependencies
Clear documentation reduces confusion during crises and accelerates coordinated action.
Business Impact Analysis as a Continuous Process
A Business Impact Analysis (BIA) should never be static.
As organizations evolve, business priorities change due to:
New products
Mergers
Cloud migration
Geographic expansion
Regulatory changes
Customer expectations
A modern BIA continuously reevaluates:
Criticality rankings
Revenue impact
Operational dependencies
Legal consequences
Service-level commitments
Regular BIA updates ensure RTO and RPO targets remain aligned with actual business priorities.
Testing as the Core of Real-World Preparedness
Testing is where theory becomes reality.
Many organizations create excellent disaster recovery documentation but fail because those plans were never realistically validated.
Testing answers critical questions:
Can backups actually restore?
Can failover systems handle production traffic?
Do employees know their responsibilities?
Can communication systems function during outages?
Do vendors respond as expected?
Types of Recovery Testing
Tabletop Exercises
Discussion-based scenario simulations.
Advantages:
Low cost
Strategic alignment
Good for communication planning
Functional Testing
Specific technical systems are tested.
Advantages:
Validates backups or failover systems
Full-Scale Simulations
Comprehensive disaster exercises.
Advantages:
Most realistic
Highest confidence
Challenges:
Resource-intensive
Chaos Engineering
Controlled disruptions intentionally introduced.
Advantages:
Tests resilience under unpredictable conditions
Frequent testing identifies weaknesses before actual emergencies expose them.
The Human Factor in Continuity Success
Technology can fail, but people often determine whether failures escalate or stabilize.
Human-related risks include:
Poor communication
Lack of training
Misunderstood procedures
Delayed escalation
Manual errors
Staff shortages
Organizations improve human resilience through:
Role-specific drills
Cross-training
Clear command structures
Leadership exercises
Psychological readiness
During high-pressure incidents, confidence and clarity are as valuable as technology.
Communication Planning During Recovery Events
Communication failures can worsen technical incidents.
Key stakeholders include:
Employees
Customers
Vendors
Regulators
Media
Investors
Effective communication plans define:
Who communicates
What is communicated
When updates occur
Which channels are used
How misinformation is managed
Transparency builds trust, even during outages.
Poor communication often creates greater reputational harm than the outage itself.
Vendor and Third-Party Dependency Management
Modern organizations rely heavily on third parties:
Cloud providers
Payment processors
Security vendors
Logistics systems
Telecommunications carriers
Software platforms
A vendor outage can directly impact internal RTO and RPO targets.
Best practices include:
Vendor SLAs
Independent backup plans
Multi-vendor redundancy
Contractual recovery clauses
Third-party audits
Organizations must assess external resilience, not just internal systems.
Compliance, Regulation, and Legal Preparedness
Industries increasingly face strict continuity obligations.
Examples include:
Financial resilience mandates
Healthcare data protection
Government service continuity
Critical infrastructure regulations
Failure to meet required recovery obligations may lead to:
Fines
Lawsuits
License restrictions
Public investigations
Compliance planning should integrate directly with continuity architecture.
Cyber Resilience and Security-Centered Recovery
Cyber threats have transformed continuity planning.
Modern threats include:
Ransomware
Supply chain attacks
Credential compromise
Data destruction
Insider sabotage
Because attackers often target backups, organizations must prioritize:
Immutable storage
Offline backups
Privileged access controls
Zero-trust frameworks
Recovery environment isolation
Recovery planning now overlaps significantly with cybersecurity architecture.
The Importance of Immutable and Air-Gapped Backups
Traditional backups may fail if compromised by attackers.
Immutable Backups
Data cannot be altered or deleted for a defined period.
Air-Gapped Backups
Physically or logically isolated from primary systems.
These strategies dramatically improve resilience against ransomware.
Metrics for Long-Term Success
Continuous improvement depends on measurable outcomes.
Key metrics include:
Recovery success rate
Backup validation frequency
Mean Time to Detect
Mean Time to Respond
Mean Time to Recover
Replication latency
Policy compliance rates
These metrics should be reviewed regularly by leadership.
Continuous Improvement Models
Recovery planning should operate similarly to cybersecurity maturity.
Basic
Manual backups
Limited planning
Intermediate
Defined RTO/RPO
Scheduled testing
Advanced
Automation
Continuous replication
Cross-region failover
Optimized
Predictive analytics
AI automation
Self-healing systems
The objective is progression, not perfection.
Artificial Intelligence and Predictive Continuity
AI is increasingly shaping business continuity.
Applications include:
Predictive hardware maintenance
Anomaly detection
Automated remediation
Threat prediction
Backup optimization
Capacity forecasting
AI reduces human response time and identifies risks earlier.
Cloud-Native Recovery Evolution
Cloud-native technologies continue changing continuity strategy.
Examples include:
Container orchestration
Serverless failover
Distributed databases
Infrastructure-as-code
Policy-as-code
These approaches increase agility while requiring updated governance models.
Environmental and Geopolitical Risk Planning
Continuity planning now includes broader risk categories:
Climate events
Regional instability
Supply chain disruptions
Energy shortages
Pandemics
Organizations must increasingly diversify infrastructure geographically and operationally.
Financial Sustainability of Recovery Programs
Long-term continuity requires sustainable budgeting.
Budget categories include:
Infrastructure
Testing
Staffing
Training
Compliance
Insurance
Vendor contracts
Recovery planning must remain economically realistic.
Insurance and Risk Transfer
Cyber insurance and business interruption insurance increasingly depend on continuity maturity.
Insurers may evaluate:
Backup practices
Testing frequency
Security controls
Incident history
Strong continuity can reduce insurance costs.
Cultural Integration of Resilience
The most resilient organizations embed continuity into culture.
This means:
Leadership prioritization
Employee awareness
Routine testing
Strategic budgeting
Cross-department collaboration
When continuity becomes cultural, resilience improves organization-wide.
Common Long-Term Mistakes to Avoid
Frequent failures include:
Treating DR as a one-time project
Ignoring documentation updates
Overlooking vendor risks
Testing too rarely
Underestimating cyber threats
Failing to align business priorities
Assuming cloud alone solves continuity
Avoiding these pitfalls significantly strengthens resilience.
Future Trends in Recovery and Continuity
Key trends include:
Autonomous infrastructure recovery
Quantum-safe backup encryption
AI orchestration
Global resilience frameworks
Decentralized architectures
Cyber-physical convergence
Organizations that adapt early will gain competitive resilience advantages.
Strategic Leadership Checklist for Ongoing Continuity
Are our RTO and RPO targets still aligned with current business priorities, customer expectations, and operational realities?
Have we tested disaster recovery, backup restoration, failover systems, and incident response procedures recently enough to validate real-world readiness?
Are our vendors, cloud providers, telecommunications partners, and critical third parties resilient enough to support our continuity requirements during disruption?
Are backups secure, immutable, properly segmented, regularly validated, and protected from ransomware, insider threats, or accidental deletion?
Are employees adequately trained for both technical recovery procedures and organizational crisis response responsibilities?
Are regulatory, legal, compliance, and contractual obligations fully integrated into continuity planning and recovery frameworks?
Do we understand emerging threats such as ransomware evolution, supply chain compromise, geopolitical instability, environmental disruption, AI-driven cyberattacks, and infrastructure dependency risks?
Do we maintain clear business impact analyses that reflect current systems, services, revenue dependencies, and operational criticality?
Are our incident response, disaster recovery, and business continuity plans synchronized, regularly updated, and free from outdated assumptions?
Do we have sufficient geographic redundancy to withstand regional outages, natural disasters, or political disruptions?
Are communication plans prepared for employees, customers, regulators, partners, and media during major disruptions?
Have we identified single points of failure across hardware, software, personnel, vendors, network architecture, and security controls?
Are our cybersecurity strategies directly integrated with continuity planning to ensure secure recovery under attack conditions?
Do our insurance policies, financial reserves, and contractual protections adequately cover interruption scenarios?
Are continuity budgets sufficient for evolving infrastructure, testing, staffing, automation, and resilience improvements?
Do we measure recovery effectiveness through metrics such as MTTR, backup success rates, replication lag, and operational recovery benchmarks?
Are we investing in modern resilience technologies such as automation, predictive analytics, AI monitoring, immutable storage, and self-healing infrastructure?
Can leadership teams make rapid, informed decisions under pressure with clear escalation authority and communication structures?
Are organizational culture and executive priorities reinforcing resilience as a strategic function rather than an isolated IT responsibility?
Do we continuously learn from incidents, near misses, testing failures, and industry disruptions to strengthen future continuity capabilities?
The strongest leaders recognize that business continuity is never “finished.” It is an ongoing strategic discipline requiring constant reassessment, modernization, and alignment with changing risks. By consistently asking deeper operational, strategic, technical, and governance questions, leadership ensures continuity maturity evolves alongside the organization itself—preserving resilience, trust, and long-term business stability.
Conclusion
Recovery Time Objective and Recovery Point Objective are not static technical measurements—they are living strategic commitments that define an organization’s ability to survive disruption, preserve trust, and maintain operational continuity.
Long-term success requires more than infrastructure. It demands governance, leadership, testing, compliance, cybersecurity, vendor management, cultural integration, and continuous improvement. As technology evolves and threats grow more complex, organizations must treat continuity as an adaptive business discipline rather than a fixed recovery plan.
The most successful organizations are not those that avoid disruption entirely—that is impossible. They are the ones that prepare comprehensively, respond intelligently, recover rapidly, and improve continuously.
In a world where downtime can destroy trust and data loss can cripple operations, mastering RTO and RPO is ultimately about more than recovery. It is about resilience, strategic foresight, and the ability to thrive despite uncertainty.