The Domain Name System, commonly known as DNS, is one of the most essential services in modern networking. It acts as the mechanism that allows users and systems to communicate using human-readable names instead of numerical IP addresses. Without DNS, navigating the internet or even managing internal networks would be significantly more complicated, as every connection would require remembering long strings of numbers.
At its core, DNS functions as a translation system. When a user enters a domain name into a browser or when an application attempts to connect to a resource, DNS is responsible for resolving that name into an IP address. This translation allows devices to locate each other across networks and establish communication efficiently. Although this process happens almost instantly and behind the scenes, it involves several structured components working together.
Understanding DNS is critical not only for network administrators but also for anyone studying networking concepts. It provides the foundation for how services are discovered and accessed, and it plays a major role in performance, reliability, and security. Among its many components, DNS zones and lookup mechanisms stand out as key elements that determine how information is organized and retrieved.
DNS is often compared to a directory or catalog because it organizes information in a hierarchical manner. This structure ensures that queries can be resolved quickly and accurately, even across vast and complex networks. Each part of the system has a defined role, and together they create a reliable framework for name resolution.
Understanding DNS as a Structured System
To better understand DNS, it helps to think of it as a structured system rather than a single service. It is composed of multiple layers that work together to manage and resolve queries. At the top of this hierarchy are root servers, followed by top-level domains, and then individual domain zones. Each layer plays a role in guiding a query toward the correct destination.
When a DNS query is initiated, it does not immediately know where the answer is located. Instead, it follows a process of delegation, moving through the hierarchy until it reaches the authoritative source for the requested information. This structured approach allows DNS to scale efficiently, supporting billions of queries across the internet every day.
Within this system, DNS zones act as manageable portions of the overall namespace. They allow administrators to define boundaries and control specific sections of the DNS hierarchy. By dividing the namespace into zones, DNS becomes easier to manage and more flexible in terms of administration.
Each zone is responsible for storing records that define how names are resolved within that portion of the namespace. These records are the building blocks of DNS functionality, and they determine how queries are answered. Without zones, it would be difficult to organize and maintain the vast amount of information required for DNS to function properly.
What Are DNS Zones
DNS zones are essentially containers that hold DNS records for a specific domain or portion of a domain. They define the scope of authority for a DNS server and determine which records it is responsible for managing. A zone can represent an entire domain or just a subset of it, depending on how it is configured.
Zones are important because they allow different parts of the DNS namespace to be managed independently. This is especially useful in large organizations where different teams may be responsible for different sections of the network. By delegating control through zones, administration becomes more efficient and scalable.
A single domain can be divided into multiple zones, each with its own set of records and administrative control. For example, a parent domain might delegate a subdomain to another team or department. This delegation allows each group to manage its own resources without interfering with others.
Zones also play a role in how DNS queries are resolved. When a query is made, it is directed to the appropriate zone based on the domain name. The DNS server responsible for that zone then provides the answer, ensuring that the query is resolved accurately.
In addition to public zones that are accessible over the internet, many organizations maintain internal zones that are only available within their private networks. These internal zones are used to manage resources such as servers, printers, and applications that are not exposed to the public.
DNS Records and Their Purpose
Inside each DNS zone are DNS records, which define the actual mappings between names and resources. These records are the core elements that enable DNS to function. Each record type serves a specific purpose, and together they provide a comprehensive system for name resolution.
One of the most fundamental record types is the A record. This record maps a hostname directly to an IP address, allowing devices to locate the correct destination for communication. A records are widely used and form the basis of most DNS queries.
Another important record type is the CNAME record. Unlike A records, CNAME records do not map directly to an IP address. Instead, they create an alias by pointing one hostname to another. This allows for greater flexibility, as changes can be made to the target hostname without needing to update multiple records.
MX records are used to handle email routing. They specify which mail servers are responsible for receiving messages for a domain. These records include priority values, which determine the order in which mail servers are contacted.
TXT records are used to store text-based information. They are commonly used for verification purposes, such as confirming domain ownership or implementing security measures like email authentication policies.
Each of these record types contributes to the overall functionality of DNS. By combining different types of records within a zone, administrators can create a comprehensive mapping system that supports a wide range of services.
How DNS Records Are Stored and Managed
The way DNS records are stored and managed can vary depending on the system being used. Traditionally, DNS records are stored in text-based zone files. These files contain all the information needed to define a zone, including records, configuration settings, and metadata.
Zone files are structured in a specific format that allows DNS servers to interpret them correctly. They include entries for each record, along with additional information such as time-to-live values, which determine how long records are cached by other systems.
Modern DNS implementations often provide graphical interfaces or automated tools for managing records. These tools simplify the process of creating and updating records, making it easier for administrators to maintain their zones. However, the underlying principles remain the same, regardless of how the records are managed.
In some environments, DNS is integrated with directory services or cloud platforms. This allows records to be stored in databases rather than traditional text files. Such integration can provide additional features, such as replication, security controls, and centralized management.
Despite these advancements, the concept of the zone file remains important. Understanding how records are structured and stored helps administrators troubleshoot issues and ensure that their DNS configurations are accurate.
Subdomains and Delegation of Control
Subdomains are an important aspect of DNS that allow for the division of a domain into smaller, more manageable parts. A subdomain is essentially a child domain that exists within a larger domain. It can be used to organize resources, separate functions, or delegate administrative control.
For example, an organization might use subdomains to represent different departments, locations, or services. Each subdomain can have its own set of DNS records, allowing it to operate independently within the larger domain structure.
Delegation is the process of assigning authority over a subdomain to a different DNS server or administrative entity. This is achieved by creating specific records that direct queries for the subdomain to the appropriate servers. Delegation allows for distributed management, which is especially useful in large or complex environments.
By using subdomains and delegation, organizations can create a more flexible and scalable DNS infrastructure. It allows different teams to manage their own resources while still being part of a unified system.
Subdomains also play a role in security and organization. By separating resources into different subdomains, administrators can apply different policies and controls as needed. This helps maintain order and ensures that the DNS system remains manageable.
DNS Zone Files and Their Structure
DNS zone files are the backbone of how DNS information is defined and stored. They provide a structured representation of all the records within a zone, along with important configuration details. Even in environments where graphical tools are used, the underlying data is often based on the same principles as traditional zone files.
A zone file typically begins with a Start of Authority record. This record defines key information about the zone, including the primary name server and contact details for the administrator. It also includes parameters that control how the zone is updated and how long records are cached.
Following the Start of Authority record, the zone file includes other records such as name server records, which specify the servers responsible for the zone. Additional records define the mappings between names and resources.
The structure of a zone file is designed to be both human-readable and machine-readable. This makes it easier for administrators to understand and modify the configuration as needed. At the same time, it ensures that DNS servers can process the information efficiently.
Zone files also include directives that define how names are interpreted. These directives help simplify the configuration by allowing common elements to be defined once and reused throughout the file.
Understanding the structure of zone files is important for anyone working with DNS. It provides insight into how the system operates and helps with troubleshooting and optimization.
When and Why DNS Zones Are Used
DNS zones are used whenever there is a need to manage domain-related information. This includes both public domains that are accessible over the internet and private domains used within internal networks. Zones provide the framework for organizing and controlling DNS records.
In public environments, DNS zones are used to make websites, email services, and other resources accessible to users around the world. They ensure that queries are directed to the correct servers and that services can be reached reliably.
In private environments, DNS zones are used to manage internal resources. This includes servers, applications, and devices that are not exposed to the public. Internal zones allow organizations to use meaningful names for their resources, improving usability and efficiency.
Zones also play a role in security. By controlling which records are available and how they are accessed, administrators can protect sensitive information and prevent unauthorized access. This is particularly important in environments where both public and private zones are used.
Another reason for using DNS zones is to enable delegation and scalability. As networks grow, it becomes increasingly important to divide responsibilities and manage different sections independently. Zones provide the mechanism for achieving this.
Overall, DNS zones are a fundamental part of how DNS operates. They provide the structure needed to organize information, manage resources, and ensure that queries are resolved accurately.
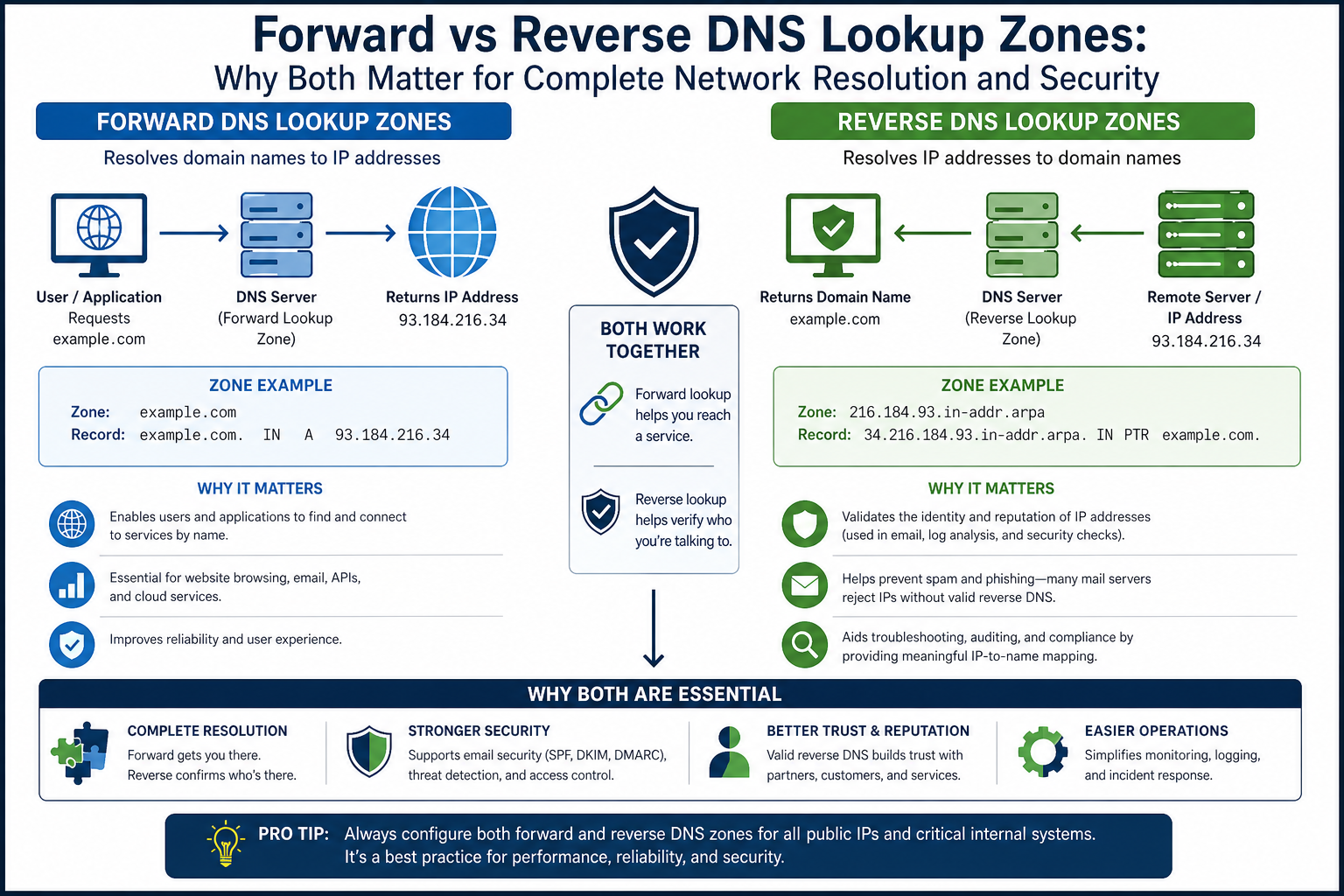
Introduction to Forward and Reverse Lookup Zones
Within the broader concept of DNS zones, there are two main types that serve distinct purposes. These are forward lookup zones and reverse lookup zones. Each type handles a different direction of resolution, and together they provide a more complete system for managing network identities.
Forward lookup zones are responsible for translating domain names into IP addresses. This is the most common type of lookup and is used in everyday activities such as browsing the web or accessing network resources.
Reverse lookup zones perform the opposite function. They translate IP addresses back into domain names. While this type of lookup is less visible to end users, it plays an important role in diagnostics, logging, and security.
Both types of zones are important, but they are not always implemented together. In many cases, forward lookup zones are considered essential, while reverse lookup zones are treated as optional or secondary. However, understanding both is key to building a robust DNS infrastructure.
By exploring these two types of zones in detail, it becomes clear how they complement each other. Forward lookup zones enable communication by resolving names, while reverse lookup zones enhance understanding and verification by resolving addresses back to names.
This dual functionality forms the foundation of DNS lookup processes and highlights the importance of proper zone management in any network environment.
Understanding Forward Lookup Zones
Forward lookup zones are the most widely used and recognized component of the Domain Name System. They are responsible for translating human-readable domain names into IP addresses, which computers and network devices use to communicate with each other. This process is fundamental to nearly every interaction on a network, whether it involves accessing a website, connecting to a server, or using an application.
When a user enters a domain name into a browser, a forward lookup is initiated. The system queries a DNS server to find the corresponding IP address associated with that name. Once the IP address is returned, the device can establish a connection with the correct destination. This entire process typically occurs in milliseconds, making it seamless and invisible to the user.
Forward lookup zones exist to organize and store the records that make this translation possible. Without them, users would need to remember numerical IP addresses for every service they want to access, which would be highly impractical. By providing a structured way to map names to addresses, forward lookup zones simplify communication and improve usability across networks.
How Forward Lookup Resolution Works
The process of resolving a domain name to an IP address involves several steps. When a query is made, it is first checked against the local cache of the device. If the answer is not found there, the query is sent to a DNS resolver, which then begins the process of locating the correct record.
The resolver may contact multiple DNS servers as it works through the hierarchy of the DNS system. It starts with root servers, moves to top-level domain servers, and eventually reaches the authoritative server for the domain in question. The authoritative server is the one that holds the forward lookup zone containing the requested record.
Once the correct record is found, the IP address is returned to the resolver, which then passes it back to the requesting device. The result is typically cached for a certain period of time to improve performance for future queries. This caching mechanism reduces the need for repeated lookups and helps optimize network efficiency.
Forward lookup zones play a central role in this process because they contain the authoritative records that provide the final answer. Without these zones, the resolution process would not be able to complete successfully.
Key Record Types in Forward Lookup Zones
Forward lookup zones contain various types of DNS records, each serving a specific purpose. These records define how names are resolved and how different services are accessed within a domain.
A records are the most basic and commonly used record type. They map a hostname directly to an IPv4 address. When a forward lookup is performed, the A record is often the final destination of the query. It provides the exact address needed to establish a connection.
In environments that use IPv6, AAAA records serve a similar function by mapping hostnames to IPv6 addresses. As networks continue to evolve and adopt newer technologies, these records are becoming increasingly important.
CNAME records provide a way to create aliases. Instead of mapping directly to an IP address, a CNAME record points one hostname to another. This allows administrators to create multiple names for the same resource without duplicating configuration. It also simplifies maintenance, as changes can be made in one place rather than across multiple records.
MX records are used to direct email traffic. They specify which mail servers are responsible for receiving messages for a domain. These records include priority values, which determine the order in which mail servers are contacted. Proper configuration of MX records is essential for reliable email delivery.
TXT records are versatile and can store various types of text-based information. They are often used for verification purposes, such as proving domain ownership or implementing security measures like email authentication. Although they do not directly contribute to name resolution, they play an important role in supporting related services.
Together, these record types form the foundation of forward lookup zones. By combining them appropriately, administrators can create a comprehensive and functional DNS environment.
Structure and Components of a Forward Lookup Zone
A forward lookup zone is defined by its structure, which includes both records and configuration settings. At the top of the zone file is the Start of Authority record, which provides essential information about the zone. This record identifies the primary name server and includes details about how the zone should be managed.
The Start of Authority record also contains parameters such as the serial number, refresh interval, retry interval, and expiration time. These values control how the zone is updated and how changes are propagated to other servers. Proper configuration of these parameters is important for maintaining consistency and reliability.
Name Server records are another critical component. They specify which servers are responsible for hosting the zone. These records ensure that queries are directed to the correct servers and that the zone can be resolved properly.
Within the zone, individual records define the mappings between names and resources. These records can include A records, CNAME records, MX records, and others, depending on the needs of the environment. Each record contributes to the overall functionality of the zone.
The organization of these records is important for readability and maintainability. A well-structured zone makes it easier for administrators to understand and manage the configuration. It also helps prevent errors and ensures that queries are resolved correctly.
Practical Uses of Forward Lookup Zones
Forward lookup zones are used in a wide range of scenarios, both in public and private networks. One of the most common uses is for web browsing. When a user enters a website address, a forward lookup is performed to determine the IP address of the web server hosting the site.
Another common use is in application communication. Many applications rely on DNS to locate servers and services. By using domain names instead of IP addresses, applications can be more flexible and easier to manage. Changes to the underlying infrastructure can be made without affecting the application, as long as the DNS records are updated accordingly.
File sharing and network services also depend on forward lookup zones. Servers can be accessed using meaningful names, making it easier for users to connect to the resources they need. This improves usability and reduces the likelihood of errors.
In enterprise environments, forward lookup zones are often used to manage internal resources. Organizations create private zones that are not accessible from the internet. These zones allow internal systems to communicate using consistent naming conventions, which simplifies administration and enhances productivity.
Forward lookup zones are also used in cloud environments. As organizations move their infrastructure to the cloud, DNS plays a crucial role in managing resources and ensuring connectivity. Cloud-based DNS services provide scalable and flexible solutions for managing forward lookup zones.
Load Balancing and Traffic Distribution
One of the advanced uses of forward lookup zones is load balancing. By associating multiple IP addresses with a single domain name, DNS can distribute traffic across multiple servers. This helps improve performance and ensures that no single server becomes overwhelmed.
This technique is often implemented using multiple A records for the same hostname. When a query is made, the DNS server may return different IP addresses in a rotating manner. This approach, known as round-robin, allows traffic to be spread evenly across available resources.
Load balancing through DNS is relatively simple to implement and does not require specialized hardware. However, it has limitations, such as the inability to detect server health in real time. Despite these limitations, it remains a useful tool for distributing traffic in many scenarios.
In more advanced environments, DNS can be integrated with other systems to provide more sophisticated load balancing capabilities. This includes features such as geographic routing, where users are directed to servers based on their location. These capabilities enhance performance and improve the user experience.
Role of Forward Lookup Zones in Internal Networks
In internal networks, forward lookup zones play a crucial role in managing resources and enabling communication. Organizations often create private DNS zones that are used exclusively within their networks. These zones allow systems to communicate using meaningful names rather than IP addresses.
Internal forward lookup zones are commonly used in environments that rely on directory services. They provide the naming structure needed for systems to locate and authenticate with each other. This is essential for maintaining a functional and secure network.
By using forward lookup zones internally, organizations can maintain consistent naming conventions and simplify administration. Changes to IP addresses can be made without affecting users, as long as the DNS records are updated. This flexibility is particularly important in dynamic environments where resources may change frequently.
Internal zones also provide a level of isolation from the public internet. By keeping certain records private, organizations can protect sensitive information and reduce the risk of unauthorized access. This contributes to overall network security.
Caching and Performance Optimization
Caching is an important aspect of forward lookup zones that helps improve performance and efficiency. When a DNS query is resolved, the result is often stored in a cache for a specified period of time. This reduces the need for repeated queries and speeds up subsequent requests.
The duration of caching is determined by the time-to-live value associated with each record. This value specifies how long the record can be stored before it must be refreshed. Proper configuration of time-to-live values is important for balancing performance and accuracy.
Shorter time-to-live values allow changes to propagate more quickly, but they increase the number of queries that must be processed. Longer values reduce the load on DNS servers but may result in outdated information being used. Finding the right balance is key to optimizing performance.
Caching occurs at multiple levels, including on the client device, within the DNS resolver, and on intermediate servers. This layered approach helps ensure that queries can be resolved quickly and efficiently.
Importance of Forward Lookup Zones in Modern Networking
Forward lookup zones are essential for the operation of modern networks. They provide the foundation for name resolution and enable seamless communication between devices. Without them, the usability and functionality of networks would be significantly reduced.
As networks continue to grow and evolve, the importance of forward lookup zones remains constant. They support a wide range of services, from web browsing and email to cloud computing and application development. Their flexibility and scalability make them a critical component of any network infrastructure.
In addition to their core functionality, forward lookup zones contribute to performance, reliability, and manageability. By providing a structured way to map names to addresses, they simplify network administration and improve the overall user experience.
While forward lookup zones handle the majority of DNS queries, they are only one part of the overall system. To achieve a complete and robust DNS implementation, it is important to understand how they interact with other components, including reverse lookup zones.
Understanding Reverse Lookup Zones
Reverse lookup zones are a specialized part of the Domain Name System that perform the opposite function of forward lookup zones. Instead of translating domain names into IP addresses, reverse lookup zones take an IP address and resolve it back into a domain name. While this may seem less important at first glance, it plays a critical role in network management, diagnostics, and security.
In everyday usage, most users interact with DNS through forward lookups. They type a name, and the system returns an address. Reverse lookups, however, operate behind the scenes. They are primarily used by administrators, network tools, and automated systems that need to verify or interpret IP-based information.
Reverse lookup zones provide context to IP addresses. Without them, an IP address is just a number with no meaningful identity. By mapping it back to a hostname, reverse DNS allows systems and administrators to better understand where traffic is coming from and what resources are involved.
Although reverse lookup zones are not always required for basic connectivity, they add a layer of clarity and trust that is valuable in many situations. Their importance becomes more apparent in environments where monitoring, logging, and verification are critical.
How Reverse DNS Resolution Works
The process of reverse DNS resolution differs from forward resolution in both structure and execution. When a reverse lookup is performed, the system starts with an IP address instead of a domain name. This address must be converted into a format that DNS can understand.
To achieve this, the IP address is reversed and appended to a special domain used for reverse lookups. For IPv4 addresses, this domain is part of a hierarchical structure designed specifically for reverse mapping. This structure allows DNS servers to process reverse queries in a way that aligns with the overall DNS hierarchy.
Once the query is properly formatted, it is sent to a DNS server responsible for the reverse lookup zone. This server contains pointer records, commonly known as PTR records, which map IP addresses to hostnames. If a matching record is found, the corresponding hostname is returned as the result.
Like forward lookups, reverse lookups can involve multiple steps and servers before reaching the authoritative source. The result may also be cached to improve performance and reduce the need for repeated queries.
Reverse resolution is generally slower and less frequently used than forward resolution, but it remains an essential tool for certain applications. Its ability to provide meaningful names for IP addresses makes it invaluable in many administrative and security contexts.
PTR Records and Their Role
PTR records are the core component of reverse lookup zones. These records define the mapping between an IP address and a hostname. Each PTR record is associated with a specific IP address and points to a single domain name.
Unlike forward lookup zones, where multiple names can point to the same IP address, reverse lookup zones are typically designed to provide a one-to-one mapping. This means that each IP address should resolve to a single, consistent hostname. Maintaining this consistency is important for reliability and trust.
PTR records are particularly important in environments where identity verification is required. For example, when a system receives a connection request, it may perform a reverse lookup to determine the hostname associated with the source IP address. This information can then be used for logging, filtering, or access control.
Creating and maintaining PTR records requires careful planning. Administrators must ensure that the records accurately reflect the corresponding forward lookup entries. Any discrepancies between forward and reverse mappings can lead to confusion or potential issues.
Despite these challenges, PTR records provide significant value. They enhance the visibility of network activity and help ensure that systems can be identified accurately.
Structure of Reverse Lookup Zones
Reverse lookup zones are structured differently from forward lookup zones. Instead of using standard domain names, they rely on a reversed representation of IP addresses. This approach allows DNS to maintain its hierarchical structure while supporting reverse queries.
For IPv4, the reverse lookup structure is organized in a way that mirrors the octets of the IP address. The address is reversed, and each segment is used to navigate the hierarchy. This design simplifies the process of locating the correct zone for a given IP address.
Within the reverse lookup zone, PTR records are defined using either the full reversed address or just the relevant portion, depending on the configuration. This flexibility allows administrators to choose the most appropriate method for their environment.
The zone also includes standard records such as the Start of Authority record and name server records. These provide the same type of metadata and configuration information found in forward lookup zones. They define how the zone is managed and which servers are responsible for it.
Understanding the structure of reverse lookup zones is important for proper configuration and troubleshooting. It ensures that queries are directed to the correct location and that records are interpreted correctly.
When to Use Reverse Lookup Zones
Reverse lookup zones are used in a variety of scenarios where identifying the source of network activity is important. One of the most common use cases is troubleshooting. When analyzing logs or network traffic, administrators often encounter IP addresses. Reverse lookups allow them to determine the corresponding hostnames, making it easier to understand the context.
Diagnostic tools also rely on reverse DNS. Utilities that trace network paths or analyze connectivity often display hostnames instead of IP addresses when reverse records are available. This makes the output more readable and easier to interpret.
Another key use case is in email systems. Many mail servers perform reverse DNS checks as part of their filtering process. When an email is received, the server may verify that the sending IP address maps to a legitimate hostname. If no reverse record exists or if the mapping appears suspicious, the message may be flagged or rejected.
Reverse lookup zones are also used in security monitoring. Systems that detect unusual or unauthorized activity can use reverse DNS to identify the source of traffic. This information can be used to investigate incidents and enforce policies.
Although reverse lookup zones are not always mandatory, they are highly recommended in environments where reliability and security are important. Their ability to provide additional context and verification makes them a valuable tool.
Challenges in Implementing Reverse DNS
Implementing reverse lookup zones can present several challenges, particularly when dealing with public IP addresses. In many cases, organizations do not own their public IP ranges. Instead, these ranges are assigned by service providers, who retain control over the reverse DNS entries.
To create reverse records for public IP addresses, organizations may need to request delegation from their provider. This process can vary depending on the provider and the size of the address range. For smaller allocations, the provider may manage the reverse records directly. For larger ranges, they may delegate control to the organization.
Managing reverse DNS internally is generally more straightforward. Organizations that control their own private IP ranges can create and maintain reverse lookup zones without external dependencies. This allows for greater flexibility and control.
Another challenge is maintaining consistency between forward and reverse records. Since these records are stored separately, they must be updated independently. Failure to keep them synchronized can lead to mismatches that affect reliability and trust.
Despite these challenges, the benefits of reverse DNS often outweigh the difficulties. With proper planning and management, reverse lookup zones can be implemented effectively.
Relationship Between Forward and Reverse Lookup Zones
Forward and reverse lookup zones are closely related but operate independently. Each serves a different purpose, and they are not automatically synchronized. This means that changes made in one zone do not automatically reflect in the other.
In forward lookup zones, it is common to have multiple names pointing to the same IP address. This many-to-one relationship allows for flexibility in naming and resource management. In reverse lookup zones, however, each IP address typically maps to a single hostname. This one-to-one relationship ensures consistency in reverse resolution.
Because of these differences, it is possible for discrepancies to occur. For example, an IP address may resolve to a hostname in reverse DNS, but that hostname may not map back to the same IP in the forward zone. Such inconsistencies can lead to confusion and may impact certain applications.
Maintaining alignment between forward and reverse records is considered a best practice. It ensures that both types of lookups provide consistent and reliable information. This is particularly important in environments where reverse DNS is used for verification or security purposes.
Understanding the relationship between these zones helps administrators design and manage their DNS infrastructure more effectively.
Security and Verification Benefits
Reverse lookup zones contribute significantly to network security and verification processes. By providing a way to confirm the identity of an IP address, they help establish trust in network communications.
One of the most notable examples is in email filtering. Mail servers often perform reverse DNS checks to verify that incoming messages originate from legitimate sources. If the reverse lookup does not match expected patterns, the message may be treated as suspicious.
Reverse DNS can also be used in access control systems. By identifying the hostname associated with an IP address, administrators can enforce policies based on trusted domains. This adds an additional layer of security beyond simple IP-based filtering.
In logging and monitoring, reverse DNS enhances visibility. It allows administrators to quickly identify the sources of activity, making it easier to detect anomalies or investigate incidents. This improved visibility is crucial for maintaining a secure environment.
While reverse DNS is not a standalone security solution, it complements other measures and contributes to a more robust defense strategy.
Are Both Forward and Reverse Lookup Zones Necessary
When considering whether both types of lookup zones are needed, it is important to understand their roles. Forward lookup zones are essential for basic functionality. They enable name resolution, which is required for almost all network interactions.
Reverse lookup zones, on the other hand, are not strictly required for connectivity. Systems can operate without them, and many networks function with only forward DNS configured. However, the absence of reverse DNS can limit visibility and affect certain services.
In environments where email, security, or detailed monitoring is important, reverse lookup zones become highly valuable. They provide additional information that can be used for verification and troubleshooting. Without them, some systems may behave differently or impose restrictions.
In practice, most organizations implement forward lookup zones as a necessity and treat reverse lookup zones as a best practice. This approach ensures that basic functionality is maintained while also providing the benefits of reverse DNS where needed.
Conclusion
Forward and reverse DNS lookup zones are fundamental components of the Domain Name System, each serving a distinct but complementary purpose. Forward lookup zones enable the translation of domain names into IP addresses, forming the backbone of everyday network communication. Reverse lookup zones perform the opposite function, providing meaningful context to IP addresses and supporting diagnostics, security, and verification processes.
While forward lookup zones are essential for the operation of any network, reverse lookup zones enhance the overall reliability and transparency of the system. They allow administrators to better understand network activity, verify identities, and troubleshoot issues more effectively.
Although it is possible to operate without reverse DNS, doing so may limit the capabilities of certain services and reduce visibility into network behavior. For this reason, implementing both forward and reverse lookup zones is considered a best practice in most environments.
Together, these two types of zones create a more complete and efficient DNS infrastructure. By understanding their roles and maintaining them properly, organizations can ensure that their networks remain functional, secure, and easy to manage.