In modern networking and internet usage, identifying and accessing resources efficiently is one of the most fundamental requirements. Whether someone is loading a web page, accessing an API, downloading a file, or sending an email, there must be a standardized way to refer to these resources. Without such a system, communication between devices and services would quickly become chaotic and unreliable.
This is where concepts like URI, URL, and URN come into play. These terms form the backbone of how resources are named, located, and accessed across networks. While they may appear technical or abstract at first glance, they are deeply embedded in everyday internet usage. Every time a user clicks a link, enters a web address, or interacts with an online service, they are indirectly using these concepts.
Understanding these identifiers is not just important for networking professionals. Developers, system administrators, cybersecurity analysts, and even content creators benefit from knowing how resources are structured and referenced. It helps build a clearer mental model of how the internet works behind the scenes.
At the highest level, these identifiers exist to solve a simple but critical problem: how do we uniquely identify and possibly locate a resource in a vast and distributed system like the internet? The solution is not a single method but a structured system that includes different types of identifiers, each serving a specific purpose.
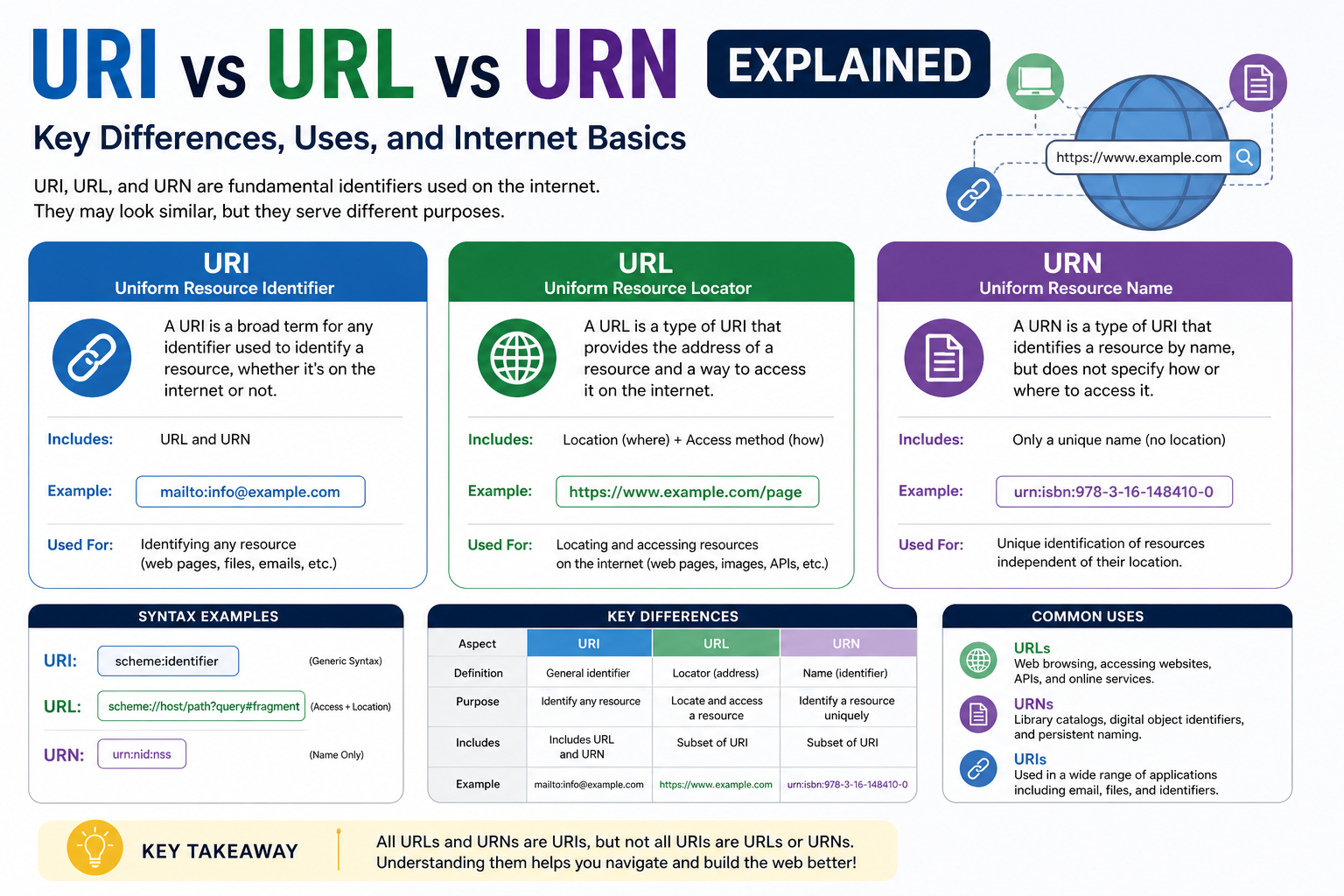
Before diving into the technical differences, it is helpful to understand that URI, URL, and URN are not competing concepts. Instead, they are part of a hierarchy. URI is the broadest term, and both URL and URN fall under it. This hierarchical relationship is key to understanding how they interact and why they are defined separately.
What is a URI and Why It Matters
A URI, or Uniform Resource Identifier, is a string of characters used to identify a resource. The resource could be anything from a web page to a file, an image, a service endpoint, or even a conceptual entity. The defining feature of a URI is that it provides a way to uniquely identify something within a given context.
One of the most important aspects of a URI is that it focuses on identification rather than access. In other words, a URI tells you what something is, but it does not necessarily tell you how to retrieve it. This distinction may seem subtle, but it is crucial for understanding how different types of identifiers function.
URIs are designed to be flexible and extensible. They can take many forms depending on the scheme being used. The scheme is the first part of a URI and indicates the type of identifier. Common schemes include http, https, ftp, mailto, and others. Each scheme defines a specific way of interpreting the rest of the URI.
For example, when a URI begins with http or https, it indicates that the resource can be accessed using the Hypertext Transfer Protocol. When it begins with mailto, it indicates an email address. This flexibility allows URIs to be used across a wide range of applications and protocols.
Another important characteristic of URIs is that they provide a uniform way of identifying resources. This uniformity is essential for interoperability. Different systems, applications, and devices can understand and use URIs consistently, regardless of their underlying architecture.
The concept of a URI also supports abstraction. By separating identification from location and access, URIs allow systems to refer to resources without needing to know exactly where they are or how they are accessed. This abstraction can be particularly useful in distributed systems, where resources may move or change over time.
In practical terms, URIs are everywhere. They are used in web browsers, APIs, databases, and many other systems. Even when users are not aware of them, URIs are working behind the scenes to ensure that resources can be identified and referenced accurately.
Understanding URIs provides a foundation for exploring more specific types of identifiers, such as URLs and URNs. It helps clarify why these terms exist and how they fit into the broader system of resource identification.
The Relationship Between URI, URL, and URN
To fully grasp the differences between URI, URL, and URN, it is essential to understand their relationship. The simplest way to think about it is that URI is the general category, while URL and URN are specific types within that category.
This means that every URL is a URI, and every URN is also a URI. However, not every URI is a URL or a URN. This distinction is often a source of confusion, especially because URLs are so commonly used that people sometimes use the term URI and URL interchangeably.
The reason for this hierarchy is that different types of identifiers serve different purposes. A URI provides a general way to identify a resource. A URL provides a way to locate and access that resource. A URN provides a persistent and location-independent name for the resource.
This layered approach allows for greater flexibility and scalability. Systems can choose the type of identifier that best fits their needs. For example, a web application might use URLs to provide direct access to resources, while a digital library might use URNs to ensure long-term identification of documents.
Another way to understand this relationship is to think in terms of questions. A URI answers the question what is this resource. A URL answers the question where is it and how do I access it. A URN answers the question what is its unique name regardless of location.
This conceptual framework helps clarify why these terms are not interchangeable. Each one provides a different type of information, and using the correct term ensures clear communication, especially in technical contexts.
In many real-world scenarios, the distinction may not seem important. For example, when browsing the web, users typically interact with URLs and do not need to think about URIs or URNs. However, in more advanced applications, such as system design, API development, or data management, these differences become much more significant.
Understanding the relationship between these terms also helps avoid common misconceptions. For instance, some people assume that URI and URL are completely separate concepts, when in fact URL is a subset of URI. Recognizing this hierarchy provides a more accurate understanding of how resource identification works.
Breaking Down the Structure of a URI
To better understand how URIs function, it is useful to examine their structure. While URIs can vary depending on the scheme, they generally follow a consistent format that includes several key components.
The first component is the scheme. This part appears at the beginning of the URI and is followed by a colon. The scheme indicates the type of identifier and provides context for interpreting the rest of the URI. Examples of schemes include http, https, ftp, and mailto.
Following the scheme, many URIs include a hierarchical part. In the case of URLs, this often includes the authority, which may contain the domain name and optional port number. The domain name identifies the server or host where the resource is located.
After the authority, there is typically a path that specifies the location of the resource within the server. This path can include directories and file names, similar to a file system structure. Additional components, such as query parameters and fragments, may also be included to provide more specific information.
Not all URIs include every component. The exact structure depends on the scheme and the type of resource being identified. For example, a mailto URI may simply include an email address, while an HTTP URI may include multiple components.
Understanding the structure of URIs helps illustrate how they can be used to represent a wide range of resources. It also highlights the differences between URIs, URLs, and URNs. URLs typically include detailed information about location and access, while URNs focus on naming and uniqueness.
Another important aspect of URI structure is standardization. The format and rules for URIs are defined by technical standards, ensuring consistency across different systems and applications. This standardization is essential for interoperability and reliability.
By breaking down the structure of URIs, it becomes easier to see how they function as identifiers. Each component plays a specific role, and together they create a complete reference to a resource.
Real-World Examples of URIs in Use
To make these concepts more concrete, it is helpful to look at real-world examples of URIs. These examples demonstrate how URIs are used in everyday scenarios and how they differ from URLs and URNs.
One common example is a web address entered into a browser. This is a URL, and therefore also a URI. It includes a scheme such as https, a domain name, and a path to a specific resource. This type of URI provides both identification and access.
Another example is an email link using the mailto scheme. This type of URI identifies an email address and can be used to open an email client. While it does not provide a location in the same way as a web address, it still serves as a valid identifier.
URIs are also used in APIs to identify resources such as users, products, or services. In these cases, the URI often takes the form of a URL, providing a clear path to the resource and enabling interaction through HTTP methods.
In more specialized systems, URNs may be used to identify resources in a way that is independent of their location. For example, a digital archive might assign a URN to each document, ensuring that it can be uniquely identified even if it is moved to a different server.
These examples highlight the versatility of URIs and their importance in modern networking. They show how a single concept can be applied in different ways to meet various needs.
By examining real-world use cases, it becomes easier to understand the practical significance of URI, URL, and URN. These are not just theoretical concepts but essential tools for organizing and accessing information in a connected world.
Why Understanding URIs is Important
Understanding URIs is more than just learning technical definitions. It provides insight into how the internet is structured and how different systems communicate with each other. This knowledge is valuable for anyone working in technology and can also enhance general digital literacy.
One of the key benefits of understanding URIs is improved clarity. When working on projects that involve networking or web development, using the correct terminology helps avoid confusion and ensures effective communication. It also makes it easier to understand documentation and technical specifications.
Another benefit is better system design. Knowing how resources are identified and accessed allows developers and engineers to create more efficient and scalable systems. It helps in designing APIs, organizing data, and managing resources effectively.
Security is another area where understanding URIs can be helpful. Recognizing different types of URIs and how they are used can aid in identifying potential vulnerabilities, such as malicious links or improper resource handling.
Finally, understanding URIs provides a foundation for learning more advanced topics in networking and web technologies. Concepts such as RESTful APIs, microservices, and distributed systems all rely on effective resource identification.
As the internet continues to evolve, the importance of standardized identification systems will only grow. URI, URL, and URN will remain fundamental components of this system, supporting the ongoing expansion of digital communication and information sharing.
This foundational understanding sets the stage for exploring URLs in greater detail, including how they function, how they are structured, and why they are so widely used.
Deep Dive into URLs and How They Work
In the previous section, we explored the broader concept of URIs and how they act as a universal way to identify resources. Now, it is time to narrow the focus and examine URLs in greater detail. URLs are the most familiar type of URI because they are used constantly in everyday internet activities. Whenever someone opens a website, clicks a hyperlink, or downloads a file, they are interacting with a URL.
A URL, or Uniform Resource Locator, is designed to do more than just identify a resource. It provides a complete set of instructions that allow a system to locate and retrieve that resource. This dual role of identification and access is what makes URLs so practical and widely used.
At its core, a URL answers two essential questions. First, what is the resource? Second, how can it be accessed? By combining these two pieces of information into a single string, URLs make it possible for browsers and other applications to communicate with servers and retrieve data efficiently.
One of the defining characteristics of a URL is its inclusion of an access method. This is typically represented by the scheme at the beginning of the URL. The scheme tells the system which protocol to use when interacting with the resource. Common protocols include HTTP, HTTPS, FTP, and others. Each protocol defines a specific set of rules for how data is transmitted and received.
The importance of this access method cannot be overstated. Without it, a system would not know how to communicate with the resource. For example, accessing a web page requires a different process than sending an email or transferring a file. The scheme ensures that the correct method is used in each case.
Breaking Down the Components of a URL
To fully understand how URLs function, it is helpful to break them down into their individual components. While URLs can vary in complexity, most follow a standard structure that includes several key parts.
The first part of a URL is the scheme. This indicates the protocol used to access the resource. It is followed by a colon and, in many cases, two forward slashes. For example, in a typical web address, the scheme might be https.
Next is the authority component, which often includes the domain name. The domain name identifies the server where the resource is hosted. It acts as a human-readable address that corresponds to an IP address. This allows users to access resources without needing to remember numerical addresses.
The authority may also include a port number, although this is often omitted because default ports are assumed for common protocols. For example, HTTP typically uses port 80, while HTTPS uses port 443.
Following authority is the path. The path specifies the location of the resource within the server. It can include directories, subdirectories, and file names. This structure is similar to navigating a file system on a computer.
In addition to the path, a URL may include a query string. The query string provides additional parameters that can be used to modify the request or provide input to the server. It typically begins with a question mark and consists of key-value pairs separated by ampersands.
Finally, there may be a fragment identifier, which points to a specific section within the resource. This is often used in web pages to navigate to a particular heading or element.
Each of these components plays a specific role in helping the system locate and retrieve the resource. Together, they form a complete and precise reference that can be used across different systems and applications.
How URLs Enable Communication on the Web
URLs are not just static strings; they are active participants in the process of communication between clients and servers. When a user enters a URL into a browser, a series of events is triggered that ultimately leads to the retrieval of the requested resource.
The process begins with the browser interpreting the URL. It identifies the scheme and determines which protocol to use. If the scheme is HTTPS, the browser knows that it must establish a secure connection using encryption.
Next, the browser resolves the domain name to an IP address. This is done through a system known as the Domain Name System, which acts as a directory for mapping human-readable names to numerical addresses. Once the IP address is obtained, the browser can locate the server.
After establishing a connection with the server, the browser sends a request for the resource specified in the URL. This request includes details such as the path and any query parameters. The server processes the request and sends back a response, which may include the requested data or an error message.
This entire process happens in a matter of milliseconds, allowing users to access information almost instantly. URLs serve as the starting point for this interaction, providing all the necessary information to initiate the process.
Understanding this workflow highlights the importance of URLs in enabling seamless communication on the web. They are not just identifiers but also instructions that guide the entire process of data retrieval.
The Role of Protocols in URLs
Protocols are a fundamental part of URLs because they define how data is transmitted between systems. Each protocol has its own set of rules and characteristics, which influence how resources are accessed and handled.
The most commonly used protocol in URLs is HTTP, which stands for Hypertext Transfer Protocol. It is the foundation of data communication on the web. HTTPS is a secure version of HTTP that uses encryption to protect data during transmission.
Other protocols include FTP, which is used for file transfers, and mailto, which is used for email addresses. Each of these protocols serves a specific purpose and is suited to different types of interactions.
The inclusion of the protocol in a URL ensures that the correct method is used to access the resource. This is essential for compatibility and functionality. Without a clearly defined protocol, systems would not be able to communicate effectively.
Protocols also play a role in security and performance. For example, HTTPS provides encryption, which helps protect sensitive information from being intercepted. Choosing the appropriate protocol can have a significant impact on the reliability and safety of a system.
Practical Examples of URLs in Everyday Use
URLs are an integral part of everyday internet usage, even if users are not consciously aware of them. They appear in web browsers, emails, mobile apps, and many other contexts.
When someone types a web address into a browser, they are using a URL to access a website. When they click a link in an email, the link is a URL that directs them to a specific resource. Even when using mobile applications, URLs are often used behind the scenes to communicate with servers.
APIs also rely heavily on URLs. In this context, URLs are used to identify endpoints that provide access to specific data or services. For example, a URL might be used to retrieve user information, submit a form, or update a record.
These examples demonstrate the versatility and importance of URLs. They are not limited to web pages but are used in a wide range of applications and systems.
Understanding how URLs are used in practice helps reinforce their role as both identifiers and access mechanisms. It also highlights why they are the most commonly encountered type of URI.
Limitations of URLs and Why They Are Not Always Enough
While URLs are extremely useful, they are not without limitations. One of the main limitations is that they are tied to the location of a resource. If the location changes, the URL may no longer be valid. This can lead to broken links and difficulties in accessing resources.
This limitation is particularly problematic in systems where resources are expected to remain accessible over long periods of time. For example, academic publications, digital archives, and legal documents often require stable and persistent identifiers.
Another limitation is that URLs can become complex and difficult to manage. Long URLs with multiple parameters can be hard to read and prone to errors. This can affect usability and increase the likelihood of mistakes.
Additionally, URLs may expose details about the structure of a system, which can have security implications. For example, revealing directory structures or file names may provide information that could be exploited by malicious actors.
These limitations highlight the need for alternative approaches to resource identification, which is where URNs come into play. URNs address some of these challenges by providing a way to identify resources independently of their location.
The Importance of Choosing the Right Identifier
Choosing the appropriate type of identifier is an important consideration in system design. While URLs are suitable for many applications, they may not be the best choice in every situation.
In scenarios where direct access is required, URLs are the preferred option. They provide a straightforward way to locate and retrieve resources, making them ideal for web applications and APIs.
However, in cases where long-term identification is more important than immediate access, URNs may be more appropriate. They provide a stable and persistent way to identify resources, even if their location changes.
Understanding the strengths and limitations of each type of identifier allows developers and engineers to make informed decisions. It also helps ensure that systems are designed in a way that meets their specific requirements.
This deeper exploration of URLs sets the stage for the next section, where we will examine URNs in detail. By comparing their characteristics and use cases, we can gain a more complete understanding of how these identifiers work together to support modern networking.
Understanding URNs and Their Purpose
After exploring URIs as the broad category and URLs as the most commonly used subset, the final piece of the puzzle is the URN, or Uniform Resource Name. While URNs are less visible in everyday internet usage compared to URLs, they play a crucial role in specific systems where long-term identification and consistency are essential.
A URN is designed to uniquely identify a resource without providing any information about its location or how to access it. This is a key distinction. While a URL tells you where a resource is and how to retrieve it, a URN focuses entirely on what the resource is in a persistent and globally unique way.
The idea behind URNs is to create identifiers that remain stable over time, even if the underlying resource moves or changes its location. This makes URNs particularly valuable in systems where resources must be referenced consistently across long periods, such as digital libraries, archival systems, and standards documentation.
A URN follows a specific structure that distinguishes it from other types of URIs. It typically begins with the scheme urn, followed by a namespace identifier and a namespace-specific string. This structure ensures that each URN is unique within its namespace and, ideally, globally unique across all namespaces.
The emphasis on global uniqueness is one of the defining features of URNs. Unlike simple names or labels that might be duplicated in different contexts, a properly constructed URN is intended to refer to one and only one resource. This eliminates ambiguity and ensures clarity when referencing resources.
How URNs Differ from URLs in Practice
Although both URNs and URLs are types of URIs, their practical applications are quite different. URLs are designed for immediate access. They are used when the goal is to retrieve a resource quickly and efficiently. URNs, on the other hand, are designed for identification without concern for access.
One way to understand this difference is to think about permanence. URLs are inherently tied to a specific location. If the resource moves, the URL may break unless redirects or updates are implemented. This is a common issue on the web, often referred to as link rot.
URNs address this problem by decoupling identification from location. A URN remains the same regardless of where the resource is stored. This makes it a more reliable identifier in situations where stability is critical.
However, this also means that URNs do not provide a direct way to access the resource. Additional systems or mechanisms are required to resolve a URN to a location where the resource can be retrieved. This extra step can make URNs less convenient for everyday use but more powerful in specialized contexts.
Another practical difference is visibility. Most internet users interact with URLs on a daily basis, but they rarely encounter URNs. This is because URLs are designed for user-facing applications, while URNs are often used behind the scenes in systems that require persistent identifiers.
Despite these differences, URNs and URLs are not mutually exclusive. In many systems, they can complement each other. A URN can be used to identify a resource, while a URL can be used to access it. This combination allows for both stability and usability.
Common Use Cases for URNs
URNs are particularly useful in environments where resources need to be identified consistently over time. One of the most common use cases is in digital libraries and academic publishing. In these contexts, documents, articles, and other resources must be referenced in a way that remains valid even if the storage location changes.
Another important use case is in standards and specifications. Organizations that develop technical standards often use URNs to identify documents and components. This ensures that references remain consistent across different versions and implementations.
URNs are also used in content management systems and archival systems. These systems often deal with large volumes of data that may be moved, reorganized, or migrated over time. Using URNs allows them to maintain consistent references without worrying about changes in location.
In some cases, URNs are used in conjunction with resolution systems that map the URN to one or more URLs. This allows users to access the resource while still benefiting from the stability of the URN. These resolution systems act as intermediaries, translating the persistent identifier into a usable location.
Another area where URNs are valuable is in metadata and indexing. By assigning unique identifiers to resources, systems can organize and retrieve information more efficiently. This is especially important in large-scale databases and distributed systems.
The Structure and Format of URNs
URNs follow a standardized format that helps ensure consistency and uniqueness. The general structure includes the urn scheme, followed by a namespace identifier and a namespace-specific string.
The namespace identifier defines the category or system within which the URN is unique. For example, a namespace might be associated with a specific organization, standard, or type of resource. The namespace-specific string then uniquely identifies the resource within that namespace.
This structured approach allows different systems to define their own namespaces while maintaining global uniqueness. It also provides a level of organization that makes it easier to manage and interpret URNs.
One of the key challenges in using URNs is ensuring that namespaces are properly managed. Without careful coordination, there is a risk of duplication or conflict. This is why namespaces are often governed by organizations or standards bodies.
Another important aspect of URNs is that they are designed to be persistent. This means that once a URN is assigned to a resource, it should not be reused or reassigned. Maintaining this persistence requires careful planning and management.
Despite these challenges, the structured format of URNs provides a powerful tool for long-term resource identification. It allows systems to create stable references that can be relied upon over time.
Comparing URI, URL, and URN in Real-World Contexts
Now that we have explored URIs, URLs, and URNs in detail, it is useful to compare them in practical terms. Each of these identifiers serves a specific purpose, and understanding their differences helps clarify when and how to use them.
A URI is the most general concept. It provides a way to identify a resource, regardless of how that identification is achieved. This makes it a flexible and versatile tool for a wide range of applications.
A URL is a specific type of URI that includes information about how to access the resource. It is the most commonly used type of identifier on the web and is essential for browsing, downloading, and interacting with online content.
A URN is another type of URI that focuses on providing a persistent and location-independent name. It is less commonly used in everyday applications but plays a critical role in systems that require stable and unique identifiers.
In many cases, these identifiers are used together. For example, a system might use URNs to assign unique identifiers to resources and URLs to provide access to those resources. This combination allows for both stability and usability.
Understanding these differences is not just an academic exercise. It has practical implications for system design, development, and maintenance. Choosing the right type of identifier can impact everything from user experience to data integrity.
Challenges and Misconceptions
Despite their importance, URI, URL, and URN are often misunderstood. One common misconception is that these terms are interchangeable. While they are related, they are not the same, and using them incorrectly can lead to confusion.
Another challenge is the complexity of the concepts. For beginners, the distinctions between identification, location, and naming can be difficult to grasp. This is especially true because URLs are so dominant in everyday usage that they overshadow other types of identifiers.
There is also the issue of implementation. While URLs are straightforward to use, URNs require additional infrastructure to be fully effective. This can make them less appealing for certain applications, even when they offer advantages in terms of stability.
Despite these challenges, gaining a clear understanding of these concepts is worthwhile. It provides a deeper insight into how the internet works and helps build a stronger foundation for working with networked systems.
The Future of Resource Identification
As technology continues to evolve, the need for effective resource identification will only grow. New types of systems, such as distributed applications, cloud services, and decentralized networks, present new challenges and opportunities.
In these environments, the principles behind URI, URL, and URN remain relevant. The need to identify resources, locate them, and ensure their persistence is as important as ever.
Emerging technologies may introduce new approaches to resource identification, but they are likely to build on the existing framework. Understanding URI, URL, and URN provides a solid foundation for adapting to these changes.
As systems become more complex and interconnected, the importance of clear and consistent identification will continue to increase. This makes the study of these concepts not only relevant but essential for anyone working in technology.
Conclusion
URI, URL, and URN are fundamental concepts in networking that provide a structured way to identify and interact with resources. While they are closely related, each serves a distinct purpose.
A URI acts as the broadest category, offering a general method for identifying resources. A URL builds on this by adding the ability to locate and access those resources, making it the most practical and widely used form. A URN, in contrast, focuses on providing a persistent and globally unique name, ensuring long-term identification regardless of location.
Understanding the differences between these three identifiers helps clarify how the internet is organized and how systems communicate. It also highlights the importance of choosing the right type of identifier based on the needs of a given application.
In everyday use, URLs dominate because they provide immediate access to resources. However, URNs offer valuable advantages in scenarios where stability and persistence are critical. Together, these identifiers form a comprehensive system that supports the vast and ever-growing network of information.
By mastering these concepts, individuals can gain a deeper understanding of networking fundamentals and improve their ability to design, develop, and manage modern systems.